
Linux内核同步机制之(九):Queued spinlock
作者:OPPO内核团队 发布于:2022-6-29 6:33 分类:内核同步机制
前言
本站之前已经有了一篇关于spinlock的文档,在之前的文章中有对自旋锁进行简单的介绍,同时给出了API汇整和应用场景。不过该文章中的自旋锁描述是基于比较老的内核版本,那时候的自旋锁还是ticket base锁,而目前最新内核中的自旋锁已经进化成queued spinlock,因此需要一篇新的自旋锁文档来跟上时代。此外,本文将不再描述基本的API和应用场景,主要的篇幅将集中在具体的自旋锁实现上。顺便说一句,同时准备一份linux5.10源码是打开本文的正确方式。
由于自旋锁可以在各种上下文中使用,因此本文中的thread是执行线索的意思,表示进程上下文、hardirq上下文、softirq上下文等多种执行线索,而不是调度器中线程的意思。
一、简介
Spinlock是linux内核中常用的一种互斥锁机制,和mutex不同,当无法持锁进入临界区的时候,当前执行线索不会阻塞,而是不断的自旋等待该锁释放。正因为如此,自旋锁也是可以用在中断上下文的。也正是因为自旋,临界区的代码要求尽量的精简,否则在高竞争场景下会浪费宝贵的CPU资源。
1、代码结构
我们整理spinlock的代码结构如下:
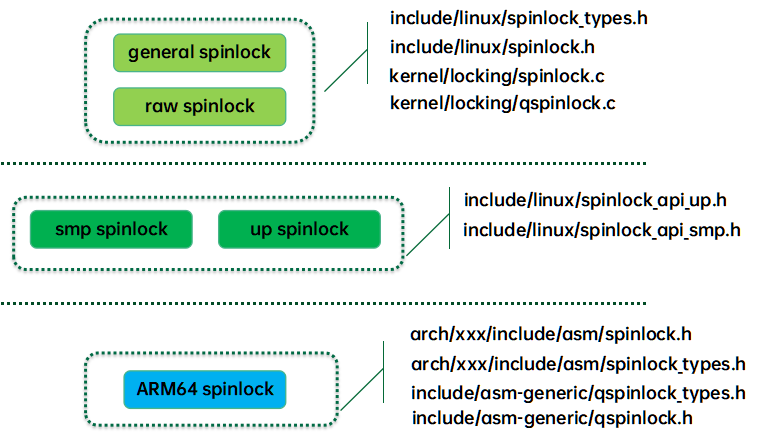
最上层是通用自旋锁代码(体系结构无关,平台无关),这一层的代码提供了两种接口:spinlock接口和raw spinlock接口。在没有配置PREEMPT_RT情况下,spinlock接口和raw spinlock接口是一毛一样的,但是如果配置了PREEMPT_RT,spinlock接口走rt spinlock,底层是基于rtmutex的。也就是说这时候的spinlock不再禁止抢占,不再自旋等待,而是使用了支持PI的睡眠锁来实现,因此有了更好的实时性。而raw spinlock接口即便在配置了PREEMPT_RT下仍然保持传统自旋锁特性。
中间一层是区分SMP和UP的,在SMP和UP上,自旋锁的实现是不一样的。对于UP,自旋没有意义,因此spinlock的上锁和放锁操作退化为preempt disable和enable。SMP平台上,除了抢占操作之外还有正常自旋锁的逻辑,具体如何实现自旋锁逻辑是和底层的CPU architecture相关的,后面我们会详细描述。
最底层的代码是体系结构相关的代码,ARM64上,目前采用是qspinlock。和体系结构无关的Qspinlock代码抽象在qspinlock.c文件中,也就是本文重点要描述的内容。
2、接口API
一个示例性的接口API流程如下(左边是UP,右边是SMP):
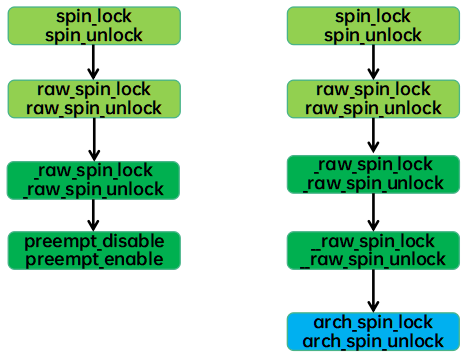
具体的接口API简单而直观,这里就不再罗列了。
3、自旋锁的演进
自旋锁的演进过程如下:

最早的自旋锁是TAS(test and set)自旋锁,即通过原子指令来修改自旋锁的状态(locked、unlocked)。这种锁存在不公平的现象,具体原因如下图所示:
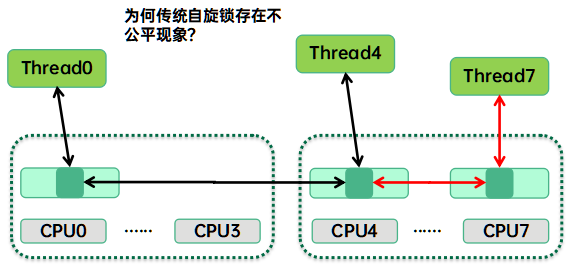
如果thread4当前持锁,同一个cluster中的cpu7上的thread7和另外一个cluster中的thread0都在自旋等待锁的释放。当thread4释放锁的时候,由于cpu7和cpu4的拓扑距离更近,thread7会有更高概率可以抢到自旋锁,从而产生了不公平现象。为了解决这个问题,内核工程师又开发了ticket base的自旋锁,但是这种自旋锁在持锁失败的时候会对自旋锁状态数据next成员进行++操作,当CPU数据巨大并且竞争激烈的时候,自旋锁状态数据对应的cacheline会在不同cpu上跳来跳去,从而对性能产生影响,为了解决这个问题,qspinlock产生了,下面的文章会集中在qspinlock的原理和实现上。
二、Qspinlock的数据结构
1、Qspinlock
struct qspinlock定义如下(little endian):
|
typedef struct qspinlock { union { atomic_t val; struct { u8 locked;------0 unlocked, 1 locked u8 pending;--------有thread(非队列中)自旋等待locked状态 }; struct { u16 locked_pending;-------mcs锁队列的head node等待该域变成0 u16 tail;--------在自旋等待队列中(mcs锁队列) }; }; } arch_spinlock_t; |
Qspinlock的数据结构一共4个byte,不同的场景下,为了操作方便,我们可以从不同的视角来看这四个字节,示意图如下:
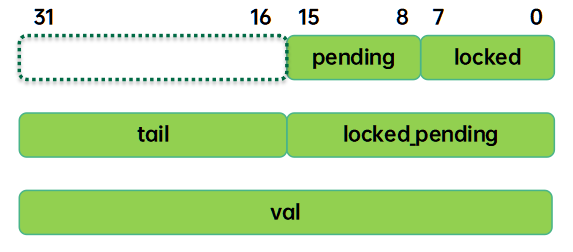
Tail成员占2B,包括tail index(16~17)和tail cpu(18~31)两个域。补充说明一下,上图是系统CPU的个数小于16k的时候的布局,如果CPU数据太大,tail需要扩展,压缩pending域的空间。这时候pending域占一个bit,其他的7个bit用于tail。之所以定义的如此复杂主要是为了操作方便,有时候我们需要对整个4B的spinlock val进行操作(例如判断空锁需要直接判断val是否为0值),有时候需要对pending+locked这两个byte进行操作(例如mcs node queue head需要自旋在pending+locked上),而有的时候又需要单独对pending或者locked进行设置,大家可以结合代码体会owner的良苦用心。
抛开这些复杂的union数据成员,实际上spinlock的4B由下面三个域组成:
|
域 |
描述 |
|
Locked |
描述该spinlock的持锁状态,0 unlocked, 1 locked |
|
Pending |
描述该spinlock是否有pending thread(没有在mcs队列中,等待在locked字段上),1表示有thread正自旋在spinlock上(确切的说是自旋在locked这个域),0表示没有pending thread。 |
|
Tail |
指向Mcs node队列的尾部节点。这个队列中的thread有两种状态:头部的节点对应的thread自旋在pending+locked域(我们称之自旋在qspinlock上),其他节点自旋在其自己的mcs lock上(我们称之自旋在mcs lock上)。 |
2、MCS lock
MCS lock定义如下:
|
struct qnode { struct mcs_spinlock mcs; }; struct mcs_spinlock { struct mcs_spinlock *next; int locked; /* 1 if lock acquired */ int count; /* nesting count, see qspinlock.c */ }; |
为了解决多个thread对spinlock的读写造成的cache bouncing问题,我们引入了per cpu的mcs lock,让thread自旋在各自CPU的mcs lock,从而减少了缓存颠簸问题,提升了性能。由于自旋锁可能是嵌套的,因此mcs lock节点在每个CPU上是多个,具体如下图所示:
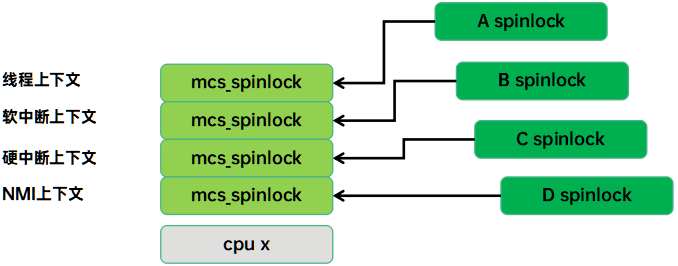
在某个线程上下文,由于持A锁失败而进入自旋,我们需要把该CPU上的mcs锁节点挂入A spinlock的队列。在这个自旋过程中,该CPU有可能发生软中断,在软中断处理函数中,我们试图持B锁,如果失败,那么该cpu上的mcs锁节点需要挂入B spinlock的队列。在这样的场景中,我们必须区分线程上下文和软中断上下文的mcs node。这样复杂的嵌套最多有四层:线程上下文、软中断上下文、硬中断上下文和NMI上下文。因此我们每个CPU实际上定义了多个mcs node节点(目前是四个),用来解决自旋锁的嵌套问题。
了解了上面的内容之后,我们可以回头看看tail成员。这个成员分成两个部分,一个是cpu id加一(0表示队列无节点),一个就是context index。这两部分合起来可以确定一个mcs node对象。
三、Qspinlock的原理
1、Qspinlock状态说明
通过上面对qspinlock数据结构的说明我们可以知道,spinlock的状态由locked、pending和tail三元组来表示。下面就是几种状态示例:
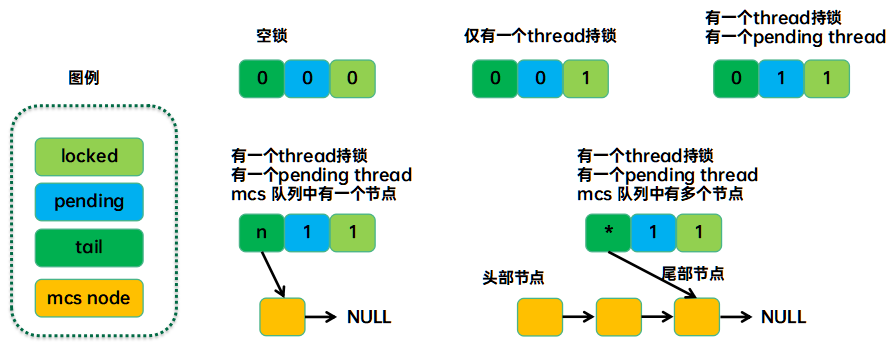
需要说明的是tail block中的“n”和“*”表示了mcs node队列的情况。n表示qspinlock只有一个mcs node,*表示qspinlock有若干个mcs node形成队列,同时在竞争spinlock。
2、Qspinlock中的状态迁移
一个完整的qspinlock状态迁移过程如下:
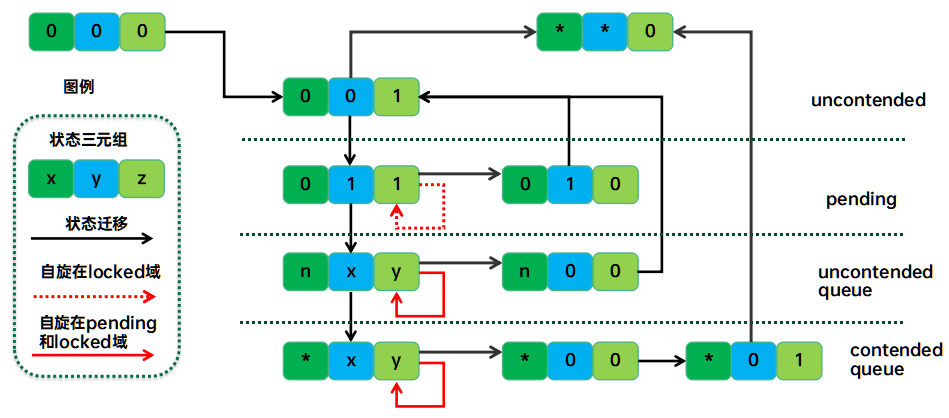
我们可以对照下一节的代码来验证上面的这张状态迁移图。
四、Qspinlock的实现
1、获取qspinlock
本小节我们主要描述获取和释放qspinlock的代码逻辑(省略了调试、内存屏障等的代码)。我们先看获取qspinlock的代码如下:
|
static __always_inline void queued_spin_lock(struct qspinlock *lock) { u32 val = 0; if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL))) return; queued_spin_lock_slowpath(lock, val); } |
如果spinlock的值(指完整的4B数据,即spinlock的val成员)等于0,那么说明是空锁,那么调用线程可以持锁进入临界区。这时候,spinlock的值被设置为_Q_LOCKED_VAL(值为1),即标记锁处于locked状态。如果快速路径失败,那么进入慢速路径。慢速路径比较长,我们分段解读
2、Pengding到locked的中间状态
慢速路径的第一段代码是处理Pengding到locked的中间的,如下:
|
if (val == _Q_PENDING_VAL) {----------------A int cnt = _Q_PENDING_LOOPS; val = atomic_cond_read_relaxed(&lock->val, (VAL != _Q_PENDING_VAL) || !cnt--); } if (val & ~_Q_LOCKED_MASK)---------------B goto queue; |
A、如果当前spinlock的值只有pending比特被设定,那么说明该spinlock正处于owner把锁转交给pending owner的过程中(即owner释放了锁,但是pending owner还没有拾取该锁)。在这种情况下,我们需要重读spinlock的值。当然,如果持续重读的结果仍然是仅pending比特被设定,那么在_Q_PENDING_LOOPS次循环读之后放弃。
为何这里我们要这么执着的等待pending owner线程将其状态从pending迁移到locked状态呢?因为我们不想排队。如果带着pending bit往下走,在B处就会直接接入排队过程。一旦进入排队过程,我们会触碰第二条cacheline(mcs lock),如果pending owner获取了锁,它会clear pending比特,这样我们就成为第一个等锁线程,也就不需要排队,变成pending owner线程。理论上owner释放锁和pending owner获取锁应该很快,但是当竞争比较激烈的时候,难免会出现长时间单pending bit被设定的情况,因此这里也不适合死等,我们设置_Q_PENDING_LOOPS等于1,即重读一次就OK了。
B、如果有其他的线程已经自旋等待该spinlock(pending域被设置为1)或者挂入MCS队列(设置了tail域),那么当前线程需要挂入MCS等待队列。否则说明该线程是第一个等待持锁的,那么不需要排队,只要pending在自旋锁上就OK了。
3、Pending owner task
我们先看看pending owner怎么自旋等待spinlock:
|
val = queued_fetch_set_pending_acquire(lock);---------A if (unlikely(val & ~_Q_LOCKED_MASK)) {------------B if (!(val & _Q_PENDING_MASK)) clear_pending(lock); goto queue; } |
A、执行至此tail+pending都是0,看起来我们应该是第一个pending线程,通过queued_fetch_set_pending_acquire函数读取了spinlock的旧值,同时设置pending比特标记状态。
B、在设置pending标记位之后,我们需要再次检查一下我们这里设置pending比特的时候,其他的竞争者是否也修改了pending或者tail域。如果其他线程已经抢先修改,那么本线程不能再pending在自旋锁上了,而是需要回退pending设置(如果需要的话),并且挂入自旋等待队列。如果没有其他线程插入,那么当前线程可以开始自旋在spinlock上,等待owner释放锁了(我们称这种状态的线程被称为pending owner)
4、Pending owner持锁
我们一起来看看pending owner如何持锁:
|
if (val & _Q_LOCKED_MASK) atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK));---------A,spinlock自旋 clear_pending_set_locked(lock);----------B return; |
A、至此,我们已经成为合法的pending owner,距离获取spinlock仅一步之遥,属于是一人之下,万人之上(对比pending在mcs lock的线程而言)。pending owner通过atomic_cond_read_acquire函数自旋在spinlock的locked域,直到owner释放spinlock。这里自旋并不是轮询,而是通过WFE指令让CPU停下来,降低功耗。当owner释放spinlock的时候会发送事件唤醒该CPU。
B、发现owner已经释放了锁,那么pending owner解除自旋状态继续前行。清除pending标记,同时设定locked标记,持锁成功,进入临界区。以上的代码就是pending owner自旋等待进入临界区的代码。
5、入队操作
下面我们再一起看看需要排队的情况:
|
node = this_cpu_ptr(&qnodes[0].mcs);--------A idx = node->count++;------B tail = encode_tail(smp_processor_id(), idx);-------C node = grab_mcs_node(node, idx);-------D |
当不能pending在spinlock的时候,当前执行线索需要挂入MCS队列。如果不是队首,那么线程会自旋在自己的mcs lock上,如果在队首的位置,那么线程需要自旋在spinlock的上。和pending owner不同的是,队首的线程是针对pending+locked两个域进行自旋。
首先要进行入队前的准备工作:一是要找到对应的mcs node,其次要准备好tail域要设置的值。
A、获取mcs node的基地址
B、由于spin_lock可能会嵌套(在不同的自旋锁上嵌套,如果同一个那么就是死锁了)因此我们构建了多个mcs node,每次递进一层。顺便一提的是:当index大于阀值的时候,我们会取消qspinlock机制,恢复原始自旋机制。
C、将context index和cpu id组合成tail
D、根据mcs node基地址和index找到对应的mcs node
找到mcs node之后,我们需要挂入队列,代码如下:
|
node->locked = 0;--------------------A node->next = NULL; if (queued_spin_trylock(lock))-------B goto release; old = xchg_tail(lock, tail);----------------C next = NULL; |
A、初始化MCS lock为未持锁状态(指mcs锁,注意和spinlock区分开),考虑到我们是尾部节点,next设置为NULL。
B、试图获取锁,很可能在上面的过程中,pending thread和owner thread都已经离开了临界区,这时候如果持锁成功,那么就可以长驱直入,进入临界区,无需排队。
C、当然,大部分场合下我们还是要入队。这里修改qspinlock的tail域,old保存了旧值。如果这是队列中的第一个节点,那么至此就结束了,如果之前tial域就有值,那么说明有队列中有其他waiter,需要把队列串联起来当前节点才真正挂入队列。
|
if (old & _Q_TAIL_MASK) {-----------A prev = decode_tail(old); WRITE_ONCE(prev->next, node);----------B arch_mcs_spin_lock_contended(&node->locked);-----C,MCS锁自旋状态 next = READ_ONCE(node->next);---------D if (next) prefetchw(next); } |
A、如果在本节点挂入队列之前,等待队列中已经有了waiter,那么我们需要把tail指向的尾部节点和旧的MCS队列串联起来。
B、建立新node和旧的等待队列的关系。
C、至此,我们已经是处于mcs queue的队列尾部,自旋在自己的mcs lock上,等待locked状态(是mcs lock,不是spinlock的)变成1。
D、执行至此,我们已经获得了MCS lock,也就是说我们成为了队首。在我们自旋等待的时候,可能其他的竞争者也加入到链表了,next不再是null了(即我们不再是队尾了)。因此这里需要更新next变量,以便我们把mcs锁禅让给下一个node。
6、持锁成功
由于本线程已经成为队首,获取了入主中原的机会,那么需要进入新的spinlock自旋状态:
|
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));---A,spinlock自旋状态 locked: if ((val & _Q_TAIL_MASK) == tail) { if (atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL)) goto release; /* No contention */------B } |
A、在获取了MCS lock之后(排到了mcs node queue的头部),我们获准了在spinlock上自旋。这里等待pending和owner离开临界区。
B、至此,我们获取了spinlock,成为万人敬仰的“owner task”,在进入临界区之前,我们需要把mcs锁传给下一个节点。如果本mcs node是队列中的最后一个节点,我们不需要处理mcs lock传递,直接试图持锁,如果成功,完成持锁,进入临界区。如果mcs node队列中仍然有节点,那么逻辑要更复杂一些,代码如下:
|
set_locked(lock);---------------A if (!next) next = smp_cond_load_relaxed(&node->next, (VAL));-----B arch_mcs_spin_unlock_contended(&next->locked);-----------C release: __this_cpu_dec(qnodes[0].mcs.count); |
A、如果本mcs node不是队列尾部,那么不需要考虑竞争,直接持spinlock
B、如果next为空,说明不存在下一个节点。不过也许在我们等自旋锁的时候,新的节点又挂入了,所以这里重新读一下next节点。
C、把mcs lock传递给下一个节点,让其自旋在spinlock上。
7、释放qspinlock
释放spinlock的代码是queued_spin_unlock函数,非常的简单,就是把qspinlock的locked域设置为0。
五、小结
本文简单的介绍了linux内核中的自旋锁同步机制,在移动环境的激烈竞争场景中,自旋锁的性能表现不尽如人意,无论是吞吐量还是延迟。产生这个问题的主要原因有两个:一是内核中自旋锁的设计基本上是仅考虑SMP硬件平台,在目前异构的手机平台上表现不佳。二是由于内核自旋锁是基于公平的原则来设计,而手机场景中从来不是追求公平的,它看中的是响应延迟。目前OPPO内核团队正在进行内核自旋锁的优化课题,我们也欢迎对此有兴趣的小伙伴加入我们,一起感受这份优化内核带来的快乐。
参考文献:
1、内核源代码
2、linux-5.10.61\Documentation\scheduler\*
本文首发在“内核工匠”微信公众号,欢迎扫描以下二维码关注公众号获取最新Linux技术分享:
修正记录:
1、7月14日,对qspinlock的实现进行了补充,修正。
评论:
2023-07-11 10:12
val = queued_fetch_set_pending_acquire(lock);---------A
if (unlikely(val & ~_Q_LOCKED_MASK)) {------------B
if (!(val & _Q_PENDING_MASK))
clear_pending(lock);
goto queue;
}
请教个问题,在这个地方,我们是判断的旧值的pending bit如果没有置位,就直接清楚了,特殊情况下如果在if判断条件成立后,我们被中断打断了(clear_pending被延后),其他核上也在尝试获取这个spin lock确实存在对pending bit置位的情况,那岂不是误清了pengding bit,而导致可能有两个wait自旋在locked域吗?
是我哪里想的不对吗?有大神帮忙解答下吗
2023-02-01 13:11
假如当CPU0获取了spinlock,而CPU1、CPU2、CPU3...在等锁,在CPU0 spin_unlock时通过sev/stlr唤醒其它所有所有CPU去check是否轮到自己;我们通过ticket可以知道lock->next是哪个CPU,其实只需要唤醒对应CPU上的task即可。
于是qspinlock应运而生:
1:当CPU0获取了spinlockA,而CPU1-->CPU2-->CPU3依次在等锁(lock->next是CPU1上的task)时,只需让CPU1自旋在spinlockA上(即qspinlock中的pending)、CPU2/CPU3自旋在percpu上的另外一把锁B(即qspinlock中的mcs锁),percpu的锁可以减少cache-boucing(具体怎么减 自行脑补);
2:当CPU0释放了spinlockA(armv8的stlr可以只唤醒对应地址上的waiter即CPU1,这点比armv7的sev好用),只会唤醒自旋在spinlockA上的CPU1,其它CPU则暂时不会被唤醒;
3:同理CPU1获取了spinlockA,需要把把lock->next标记为CPU2,并让CPU2从自旋在percpu的spinlockB转换到spinlockA;即qspinlock中对应的mcs队列;
4:同理CPU1释放了spinlockA,stlr(load-acquire/store-release)只会唤醒CPU2,;CPU2获取了spinlockA,把lock->next标记为CPU3,并让CPU3从自旋在percpu的spinlockB转换到spinlockA;即qspinlock中对应的mcs队列;
依次往下,这便是qspinlock的中心思想吧。至于怎么设计和实现,我觉得有不同的方法。
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2023-07-11 10:30