
schedutil governor情景分析
作者:OPPO内核团队 发布于:2022-4-26 6:29 分类:进程管理
前言
这是一篇分析schedutil governor(后文称之sugov)代码逻辑的文章。通过详细的代码级别的分析,希望能够帮助读者理解sugov的代码精妙之处。本文主要分四个章节:第一章简单重复了sugov相关的软件结构和基本算法,让读者对整个sugov在系统所处的位置和基本的逻辑控制有所了解。第二章对sugov使用的数据结构给出了详细的解释。第三章对sugov和cpufreq core的基本数据流和控制流进行分析。第四章描述了sugov本身的调频逻辑。
本文出现的内核代码来自Linux5.10.61,为了减少篇幅,我们会引用缩减版本的代码(仅包含主要逻辑),如果有兴趣,读者可以配合原始代码阅读本文。
一、Sugov概述
1、sugov相关软件模块
Sugov在整个调频软件的位置如下所示:
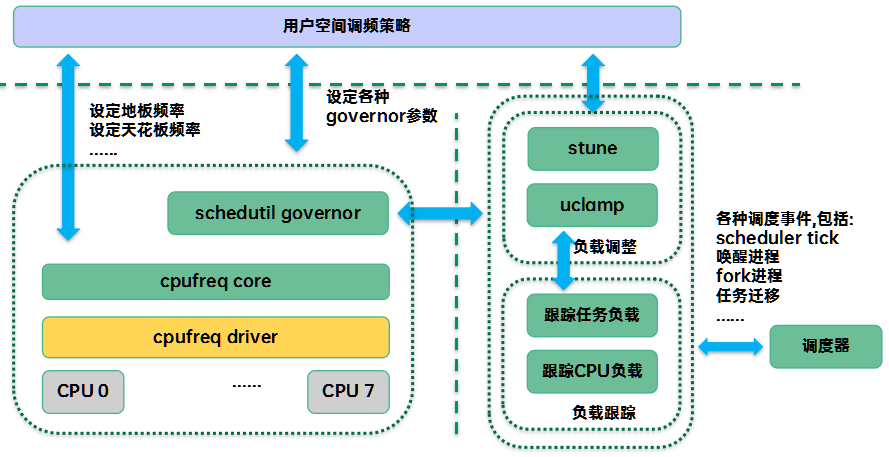
Sugov作为一种内核调频策略模块,它主要是根据当前CPU的利用率进行调频。因此,sugov会注册一个callback函数(sugov_update_shared/sugov_update_single)到调度器负载跟踪模块,当CPU util发生变化的时候就会调用该callback函数,检查一下当前CPU频率是否和当前的CPU util匹配,如果不匹配,那么就进行提频或者降频。
为了适配各种场景,sugov还提供了可调参数,用户空间可以检测当前的场景,并根据不同的场景设定不同的参数,以便满足用户性能/功耗的需求。
Sugov选定target frequency之后,需要通过cpufreq core(cpufreq framework)、cpufreq driver,cpu调频硬件完成频率的调整。cpufreq core是一个硬件无关的调频框架,集中管理了cpufreq governor、cpufreq driver、cpufreq device对象,同时提供了简单方便使用的接口API,让工程师很轻松的就能完成特定governor或者driver的撰写。
2、Sugov的基本算法描述
Sugov的基本算法如下:
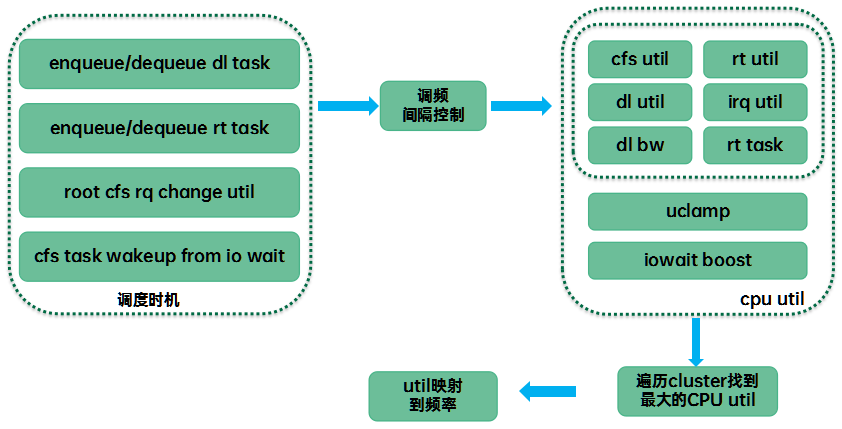
和基于采样的governor不同的是sugov是基于调度器调度事件的。每当发生调度事件的时候,负载跟踪模块会及时更新各个level的调度实体和cfs_rq的平均调度负载(sched_avg),直到顶层cfs rq(即CPU的平均调度负载) 。每当CPU利用率发生变化的时候,调度器都会调用cpufreq_update_util通知sugov,由sugov判断是否需要进行调频操作。基于采样的governor是governor定期去采样负载信息,而sugov是调度事件(进程切换、入队、出队、tick等)驱动调频的,因此调频会更及时。具体驱动调频的时机包括:
(1)实时线程(rt或者deadline)的入队出队
(2)Cpu上的cfs util发生变化
(3)处于Iowait的任务被唤醒
调度事件的发生还是非常密集的,特别是在重载的情况下,很多任务可能执行若干个us就切换出去了。如果每次都计算CPU util看看是否需要调整频率,那么本身sugov就给系统带来较重的负荷,因此并非每次调频时机都会真正执行调频检查,sugov设置了一个最小调频间隔,小于这个间隔的调频请求会被过滤掉。当然,这个最小调频间隔规定也不是永远强制执行,在特定情况下(例如cpufreq core修改了sugov可以动态调整的范围的时候),调频间隔判断可以略过。
由于调频的最小粒度是cluster,当一个cpu上的util发生变化而发起调频操作的时候,实际上sugov会遍历cluster中的所有CPU(如果cluster中只有一个cpu,那么不需要这么复杂,我们这里以cluster中包含多个cpu的sugov_update_shared场景为例来进行说明),找到util最大的那个,用这个最大的util来驱动调频。在计算cpu util要从多个视角考量:
(1)cfs、rt、dl、irq的load avg。这些都是从执行时间的视角来看util,由于PELT窗口是同步的,因此这些load avg可以对比和运算
(2)任务属性视角。对于deadline类型的任务,我们需要根据当前dl任务的参数来计算满足该任务deadline的最小utility。
找到cluster中最大的cpu utility之后,通过将其映射到一个具体的CPU frequency上来(具体参考map_util_freq函数)。目前sugov采用的映射公式如下:
next_freq = C * max_freq * util / max
其中C = 1.25,表示CPU需要调整的next freq需要提供1.25倍的算力,这样CPU在next freq上运行当前的任务还有20%的算力余量。这里计算出来的next_freq未必是最终设定的频率,因为底层硬件支持的调频是一系列的档位频率,因此,还需要底层硬件驱动进一步根据next_freq来选择一个它支持的频率,最后设定下去。
二、sugov使用的数据结构
1、struct sugov_tunables
这个数据结构用来描述sugov的可调参数:
|
成员 |
描述 |
|
struct gov_attr_set attr_set |
Sugov所属的attribute set。这个数据结构中最重要的就是policy_list成员,它是所有使用该tunalbe参数的sugov policy对象链表。如果每个policy都有自己的tunable参数,那么该链表只有一个节点。如果多个policy共享一个tunable参数,那么共享该tunable参数的sugov policy会被挂入该链表。 |
|
unsigned int rate_limit_us |
目前sugov只有一个可调参数rate_limit_us,该参数用来限制连续调频的间隔(单位是us)。当用户空间修改这个参数之后,tunalbe参数链表的所有sugov policy对象的freq_update_delay_ns成员也随之改变。 |
2、struct sugov_cpu
Sugov为每一个cpu构建了该数据结构,记录per-cpu的调频数据信息:
|
成员 |
描述 |
|
Struct update_util_data update_util |
这个成员保存了cpu util发生变化之后的callback函数。 |
|
struct sugov_policy *sg_policy |
该sugov cpu对应的sugov policy对象。一个cluster中的sugov cpu指向同一个sugov policy对象。 |
|
unsigned int cpu |
该sugov cpu对应的CPU id |
|
bool iowait_boost_pending |
当前是否有pending的iowait boost,当这个iowait boost应用到cpu调频之后,pending标记被清除,下一次iowait boost可以继续发起请求,进入pending状态。 |
|
unsigned int iowait_boost |
Iowait boost值,即根据当前io状态设定的util(可能比实际的util要大)。最初被设定为128,后续会随着iowait的情况而变化,如果短期内发起请求大量的iowait boost,那么这个boost会double,如果长期(一个tick)没有更新,那么该值会被reset。 |
|
u64 last_update |
上一次cpu负载变化驱动调频的时间点。这里的update指的是util update,不是指上一次的频率更新时间点。 这个成员是配合iowait boost,为了过滤一些零零星星偶发的io操作引起的boost。 |
|
unsigned long bw_dl |
我们可以通过deadline任务对CPU带宽的需求来定义cpu utility。bw_dl成员就是该CPU上来自dl任务属性的utility |
|
unsigned long max |
该cpu的最大算力(归一化到1024),和当前运行频率无关,对齐到该cpu的最大频率上的算力。 |
|
unsigned long saved_idle_calls |
这个成员仅在single cpu cluster的调频中有效。在这样的场景中,由于任务迁移会导致该CPU的utility下降,从而引发降频,然而实际上CPU可能有其他任务还在持续执行,这时候降频还为时过早。因此,saved_idle_calls保存了上次轮询的idle call的计数。如果这个计数没有变化,说明当前CPU还是繁忙,暂时不适合降频。在multi cpu cluster中不存在这样的问题,因为在调频的时候选择的是所有CPU中utility最大的那个。 |
3、struct sugov_policy
Sugov为每一个cluster构建了该数据结构,记录per-cluster的调频数据信息:
|
成员 |
描述 |
|
struct cpufreq_policy *policy |
指向cpufreq framework层的policy对象 |
|
struct sugov_tunables *tunables |
Sugov的可调参数 |
|
struct list_head tunables_hook |
Sugov的可调参数可以是per-cluster的,也可以是全系统的。在sugov tunable是global的情况下,共享一套参数的sugov会挂入sugov tunable的链表,这个成员就是链入sugov tunable链表的节点。在per-cluster场景下,sugov tunable和sugov对象是一一对应的,sugov tunable链表只有一个节点。 |
|
raw_spinlock_t update_lock |
保护sugov对象的自旋锁,一旦要修改sugov对象必须要持有该锁。 |
|
s64 freq_update_delay_ns |
太快的调整CPU也不是好事情,花费太多的CPU资源。调频间隔最好有一个门限,距离上一次频率调整的时间要大于这个成员给出的门限值,sugover才会真正的发起调频操作。这个值跟随sugov tunable中的rate_limit_us。 |
|
unsigned int next_freq u64 last_freq_update_time |
next_freq记录了上次调整的CPU频点值 last_freq_update_time记录了上一次进行频率调整的时间点 |
|
unsigned int cached_raw_freq |
这个频率是上次根据utility计算出来的原始频率(或者叫做target frequency),这个频率不是最终设定的cpu频率(上面的next_freq才是),通过一定的算法(例如向上靠近cpu硬件支持的一个频点)可以将其转换成对应的CPU频点值。 |
|
struct irq_work irq_work bool work_in_progress |
在不支持fast switch的场景下,我们不能直接发起调频,而是通过irq work机制来提交请求。 work_in_progress用来控制irq work入队的频次,防止queue过多的irq work。 |
|
struct kthread_work work struct kthread_worker worker struct task_struct *thread |
由于非fast switch场景下需要找一个可以阻塞的上下文来完成频率切换,这里采用了通用的kthread机制。Worker是kthread worker线程,用来处理调频的请求。具体的调频请求封装在work中,在irq work中通过kthread work完成调频请求的递交。 |
|
struct mutex work_lock |
用来控制并发的调频操作,只允许一个调频请求下发。 |
|
bool limits_changed |
Cpufreq core的max或者min发生了修改,需要立刻开启频率调整,不需要估计调频间隔限制。有些其他的模块也利用这个标记来忽略调频间隔,例如dl模块 |
|
bool need_freq_update |
当need_freq_update等于true的时候,sugov不会忽略任何一次调频请求,都会忠实的下发给驱动进行频率调整。一般而言,sugov不需要每次下发频率调整请求(例如变化的cpu util不足以引起CPU频点的变化),但是在某些特殊场景下,我们需要sugov忠实下发。具体场景下面会具体分析。 |
三、Sugov和cpufreq core之间的接口和流程分析
1、Sugov的注册
如果想要自己实现一个cpufreq governor,那么就需要定义一个struct cpufreq_governor的数据对象并向cpufreq framwork(或者叫cpufreq core)系统注册它。对于sugov而言,这个数据对象定义如下:
|
struct cpufreq_governor schedutil_gov = { .name = "schedutil", .owner = THIS_MODULE, .flags = CPUFREQ_GOV_DYNAMIC_SWITCHING, .init = sugov_init, .exit = sugov_exit, .start = sugov_start, .stop = sugov_stop, .limits = sugov_limits, }; |
然后调用cpufreq_governor_init(schedutil_gov)即可向系统注册sugov。完成注册之后,仅仅是系统可以看到这个governor,它还不一定会起作用,在将sugov设置为当前的governor之后(通过/sys/devices/system/cpu/cpufreq/policyx/scaling_governor),sugov的功能才会启用,根据调度器的利用率信息对CPU频率进行控制。当sugov切换成当前governor的时候,cpufreq framework会依次调用sugov_init、sugov_start完成sugov的初始化和启动。当sugov被其他governor替换的时候,cpufreq framework会依次调用sugov_stop、sugov_exit函数。具体请参考cpufreq_set_policy函数。
除了人为的切换cpufreq gover,在cpu hotplug场景也会有governor的启停操作。例如当CPU offline的时候,如果cluster中的所有CPU都被offline,那么cpufreq framework会依次调用sugov_stop、sugov_exit函数让sugov停止工作。如果仅仅是cluster中的一个cpu被offline,cluster中还有其他oneline的cpu core,那么我们仅仅是调用sugov_stop来暂停sugov的运作,然后在cpufreq policy中清除该cpu的bit,最后调用sugov_start来确保其他active cpu可以通过sugov来继续开展频率调整工作。Cpufreq online的操作类似,当online的cpu core所在的cluster还有active的cpu的时候,那么我们仅仅需要调用sugov_stop暂停该policy的运作,在把当前online的cpu core加入cpufreq policy的cpu mask后,重新调用sugov_start来恢复该cluster的调频运作就OK了。如果该oneline的cpu是cluster的第一个cpu core,那么逻辑要复杂一些,需要重新初始化整个cpufreq policy(cpufreq_init_policy),也就会依次调用sugov_init、sugov_start完成sugov的初始化和启动。
当cpufreq policy(位于cpufreq framework)中的频率调整范围发生变化之后(例如由于发热而引起的CPU限频),需要通知到cpufreq governor layer,这时候会调用sugov_limits来通知频率受限事件。
Cpufreq governor有很多种,并不是每一种governor都是普适的。例如:有些特定的的硬件平台根本就不希望上层的governor自动调整频率,而是自己完全掌控,这时候sugov类似的governor就不适合了。为了解决这个问题,struct cpufreq_governor和struct cpufreq_driver都提供了flags成员,报告给cpufreq core,由它来判断一个cpufreq governor是否匹配当前硬件驱动。由于sugov会自己根据CPU利用率动态的调整频率,因此需要标记CPUFREQ_GOV_DYNAMIC_SWITCHING。
2、sugov的初始化
我们分两段来解析sugov的初始化过程。sugov_init的第一段执行逻辑大致如下:
|
if (policy->governor_data)-------------------------A return -EBUSY; cpufreq_enable_fast_switch(policy);-----------B sg_policy = sugov_policy_alloc(policy);--------C ret = sugov_kthread_create(sg_policy);-------D |
A、struct cpufreq_policy的governor_data会指向当前governor policy对象,要把sugov设置为当前governor,那么旧的governor应该完成stop和exit动作,确保governor_data为空,否则返回-EBUSY
B、调用cpufreq_enable_fast_switch来使能fast switch功能。所谓fast switch是指在频率切换过程中不涉及阻塞的行为,可以直接在中断上下文执行频率切换动作。当然,这里只是sugov policy层enable fast switch,具体是否支持还要看底层cpufreq驱动。为了调和cpufreq governor和cpufreq driver的行为,cpufreq policy数据结构提供了两个成员:fast_switch_possible和fast_switch_enabled。如果底层驱动支持快速切频功能,那么cpufreq driver必须提供fast_switch的回调函数,这时候cpufreq policy的fast_switch_possible等于true,表示驱动支持任何上下文(包括中断上下文)的频率切换。只有上下打通(上指governor,下指driver),CPU频率切换才走fast switch路径。
此外,fast switch和cpufreq transition notifier是互斥的,如果有驱动已经注册了cpufreq transition notifier,那么fast switch将无法enable,反之亦然。那么为何会有这样的限制呢?其实在fasts witch出现之前就已经有了cpufreq transition notifier机制:即当CPU频率发生变化的时候,cpufreq驱动将通过notifier机制向注册的模块发送PRECHANGE和POSTCHANGE消息。收到消息的模块会调用callback来回应这个频率切换事件。然而在fasts witch机制下,我们不能调用这些callback,除非保证调用callback的过程是非阻塞的。为了保证频率切换是串行执行的,驱动模块一般会执行下面的逻辑:
|
cpufreq_freq_transition_begin---通知CPUFREQ_PRECHANGE事件 操作硬件寄存器,完成CPU频率切换 cpufreq_freq_transition_end---通知CPUFREQ_POSTCHANGE事件 |
对于fast switch,我们无法实现类似的notifiy操作,因为cpufreq_freq_transition_begin函数中有阻塞操作wait_event(为了串行化多个上下文的频率切换动作,transition_begin和transition_end顺便也完成了同步功能)。当然,我们也可以设计atomic版本的cpufreq notifier机制,但是这样要改造所有callback函数,这几乎是不现实的,所以做成fast switch和cpufreq transition notifier互斥是最简单的方案。
顺便说一句,虽然fast switch没有了频率切换通知机制,但是串行化仍然是需要的,因此,调用cpufreq_driver_fast_switch(一般是governor)完成cpu频率快速切换的时候,调用者需要使用适当的同步机制。
C、调用sugov_policy_alloc分配sugov policy对象,通过其policy成员建立和cpufreq framework的关联。
D、当不支持fast switch的时候,我们需要一个可以阻塞的线程上下文来发起调频操作。在早期的版本,这是通过workqueue机制来实现的。不过考虑到普通线程在RT/DL负载重或者整机负载非常重的情况下,cpu频率切换会由于调度延迟的加大而delay。因此,slow switch修改为优先级为50的rt内核线程(SCHED_FIFO)来替代workqueue。后来,考虑到频率切换确实非常重要,需要尽快完成,因此最终将该内核线程修改为deadline类型,即一人之下(stop class),万人之上。具体请参考sugov_kthread_create函数。当policy是fast switch模式的时候,这个deadline的内核线程是不需要的。
一般手机系统中有多个调频域,因此有多个cpufreq policy(对应cluster,cluster内的cpu统一调频),每个policy都可以有自己的可调节参数,当然也可以所有policy共同使用一组可调参数(global_tunables全局变量)。具体是使用统一的可调参数还是per-cluster可调参数是底层驱动决定的(CPUFREQ_HAVE_GOVERNOR_PER_POLICY)。目前手机场景,大部分是per-cluster的可调参数。因此我们这里略过global tunables的场景,sugov_init的第二段执行逻辑大致如下:
|
tunables = sugov_tunables_alloc(sg_policy);-----------A sg_policy->tunables = tunables; tunables->rate_limit_us = cpufreq_policy_transition_delay_us(policy);------B policy->governor_data = sg_policy;----------C ret = kobject_init_and_add(&tunables->attr_set.kobj, &sugov_tunables_ktype, get_governor_parent_kobj(policy), "%s", schedutil_gov.name);---------D |
A、调用sugov_tunables_alloc函数分配该policy(或者说cluster)的struct sugov_tunables数据对象,并建立sugov和tunable对象之间的关联(即把sugov的tunables成员指向这个分配的数据对象,同时也会把sugov挂入tunables 的链表)。
B、关于调频间隔有三个控制参数。一个是来自CPU调频硬件能力的,即硬件需要从F1频率切换到F2频率并且稳定下来的时间间隔。保存在cpufreq policy数据结构的cpuinfo成员的transition_latency中。另外两个来自软件,一个是上层sugov的设定,保存在tunables数据结构的rate_limit_us成员中(也可以说是sugov policy的freq_update_delay_ns的成员)。另外一个是底层cpufreq driver对上层governor的间隔需求,保存在cpufreq policy数据结构的transition_delay_us中。在初始化的时候,rate_limit_us应该跟随policy->transition_delay_us,如果driver没有设定该值,那么考虑硬件transition_latency乘上一个合理的倍数(缺省是1000)。对于一些硬件transition_latency比较慢的平台,这样的调频间隔设定的太大,因此clamp min到10ms。
C、建立cpufreq framework和sugov的关联(初始化governor_data)
D、初始化可调参数的sysfs接口
3、Sugov的启动
sugov_start首先执行sugov policy各个成员的初始化,逻辑大致如下:
|
sg_policy->freq_update_delay_ns = sg_policy->tunables->rate_limit_us * NSEC_PER_USEC; sg_policy->last_freq_update_time = 0; sg_policy->next_freq = 0; sg_policy->work_in_progress = false; sg_policy->limits_changed = false; sg_policy->cached_raw_freq = 0; sg_policy->need_freq_update = cpufreq_driver_test_flags(CPUFREQ_NEED_UPDATE_LIMITS); |
在cpufreq governor layer,sugov是否发起频率切换是由freq_update_delay_ns参数确定的,因此在启动sugov的时候需要根据tunable参数中的rate_limit_us来完成其初始化。need_freq_update的初始化和底层驱动相关,如果底层驱动需要在policy更新min或者max frequency的时候,无脑下发调频请求(参考__cpufreq_driver_target),那么need_freq_update是always true的(即驱动是标记CPUFREQ_NEED_UPDATE_LIMITS,目前只有intel CPU的驱动是这样设定的)。其他的成员初始化非常简单,不再赘述。
随后,sugov_start会遍历该sugov policy(cluster)中的所有cpu,建立sugov cpu和sugov policy之间的关联,代码逻辑如下:
|
for_each_cpu(cpu, policy->cpus) { struct sugov_cpu *sg_cpu = &per_cpu(sugov_cpu, cpu); memset(sg_cpu, 0, sizeof(*sg_cpu)); sg_cpu->cpu = cpu; sg_cpu->sg_policy = sg_policy; } |
最后,sugov_start会遍历该sugov policy(cluster)中的所有cpu,调用cpufreq_add_update_util_hook为sugov cpu注册调频回调函数,代码逻辑如下:
|
for_each_cpu(cpu, policy->cpus) { struct sugov_cpu *sg_cpu = &per_cpu(sugov_cpu, cpu); cpufreq_add_update_util_hook(cpu, &sg_cpu->update_util, policy_is_shared(policy) ? sugov_update_shared : sugov_update_single); } |
至此,sugov和调度器打通了,一旦调度器判断CPU util发生变化,那么将调用相应的回调函数,由sugov进一步判断是否需要进行频率调整。
4、Sugov的停止
sugov_stop执行逻辑大致如下:
|
for_each_cpu(cpu, policy->cpus) cpufreq_remove_update_util_hook(cpu);-------A synchronize_rcu();---------------B if (!policy->fast_switch_enabled) {---------------C irq_work_sync(&sg_policy->irq_work); kthread_cancel_work_sync(&sg_policy->work); } |
A、遍历该sugov policy(cluster)中的所有cpu,调用cpufreq_remove_update_util_hook注销sugov cpu的调频回调函数
B、sugov_stop之后可能会调用sugov_exit来释放该governor所持有的资源,包括update_util_data对象。通过synchronize_rcu函数可以确保之前对update_util_data对象的并发访问都已经离开了临界区,从而后续可以安全释放。
C、在不支持fast switch模式的时候,我们需要把pending状态状态的irq work和kthread work处理完毕,为后续销毁线程做准备
5、Sugov的退出
sugov_exit主要功能是释放申请的资源,具体执行逻辑大致如下:
A、断开cpufreq framework中的cpufreq policy和sugover的关联(即将其governor_data设置为NULL)
B、调用sugov_tunables_free释放可调参数的内存(如果是多个policy共用一个可调参数对象,那么需要通过引用计数来判断是否还有sugov policy引用该对象)
C、调用sugov_kthread_stop来消耗用于sugov调频的内核线程(仅用在不支持fast switch场景)
D、调用sugov_policy_free释放sugov policy的内存
E、调用cpufreq_disable_fast_switch来禁止本policy上的fast switch。
6、限频处理
从系统角度看,整个限频路径如下:
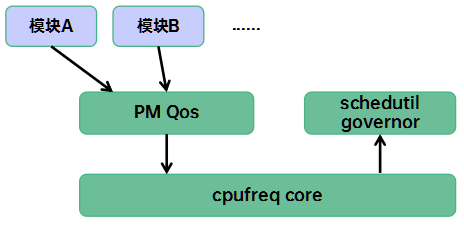
想要发起限频的内核模块A(例如检测到触摸事件后,将min freq拉升到1.2GHz)通过PM Qos模块提供的接口API向指定的cpufreq policy发起限频请求操作(例如freq_qos_add_request、freq_qos_update_request接口)。PM Qos模块会根据这个新的限频请求,并综合之前的所有的限频请求计算当前实际的限频值,如果限频值发生了变化,那么就通知cpufreq core模块frequency limits已经更新(具体的接口形态是notifier_block)。收到这个通知之后,cpufreq core模块会调用refresh_frequency_limits,最后通知到sugov模块调用sugov_limits。sugov_limits执行逻辑大致如下:
|
if (!policy->fast_switch_enabled) {---------------------A mutex_lock(&sg_policy->work_lock); cpufreq_policy_apply_limits(policy); mutex_unlock(&sg_policy->work_lock); } sg_policy->limits_changed = true;----------------B |
A、对于不支持fast switch的情况下,立刻调用cpufreq_policy_apply_limits函数使用最新的max和min来修正当前cpu频率,同时标记sugov policy中的limits_changed成员。
B、对于支持fast switch的情况下,仅仅标记sugov policy中的limits_changed成员即可,并不立刻进行频率修正。后续在调用cpufreq_update_util函数进行调频的时候会强制进行一次频率调整。
四、sugov如何进行调频
1、Sugov的频率调整间隔
虽然在调度器中有很多点都会触发cpu utility change的时间,从而会调用governor的callback函数,但是为了避免多度频繁的进行cpu频率调整(例如底层cpufreq驱动最多1ms完成频率切换,那么上次0.5ms连续下发的频率调整命令其实是没有意义的),sugov模块通过sugov_should_update_freq函数来过滤调度器密集下发的频率调整请求:
|
if (!cpufreq_this_cpu_can_update(sg_policy->policy))----------------A return false; if (unlikely(sg_policy->limits_changed)) {----------------------B sg_policy->limits_changed = false; sg_policy->need_freq_update = true; return true; } delta_ns = time - sg_policy->last_freq_update_time; return delta_ns >= sg_policy->freq_update_delay_ns;--------------------C |
A、CPU a能否调整不在一个cluster中另外一个CPU b的频率?不同的硬件平台是不一样的,有些平台上调整CPU频率的寄存器是per CPU的,因此只能调整自己CPU(cluster)的频率。这时候就需要判断一下当前发起的cpu是否在当前准备进行频率调整的policy之中,如果不在,那么就没有必要继续下去了,毕竟到了底层也无法完成频率调整,还不如一开始就结束,节省后续相关的计算。对于ARM平台不存在这样的限制,因此其cpufreq policy的dvfs_possible_from_any_cpu成员都是true的,用来标记任何的cpu都可以修改其他cpu的频率。这种情况下,也不是全部长驱直入的,需要看看当前CPU是否处于offline的过程中,如果是那么也不能进行频率调整。
B、调度器有可能会以非常密集的间隔来上报cpu util change事件,为防止没有意义的调频,sugov会进行拦截。然而还是有一些特殊情况:当该cpufreq policy的频率上下限发生变更的时候,就会忽略时间间隔的限制。此外,当cpu util的变更是由于deadline的带宽需求引发的,那么同样也需要忽略时间间隔的限制,具体参考ignore_dl_rate_limit函数。
C、这里是正常的sugov在调频时间间隔的限制逻辑。
2、计算cpu utility
schedutil_cpu_util是计算cpu utility的主函数,大概的逻辑过程如下:
|
if (!uclamp_is_used() &&----------------A type == FREQUENCY_UTIL && rt_rq_is_runnable(&rq->rt)) { return max; } irq = cpu_util_irq(rq);-----------------B if (unlikely(irq >= max)) return max; |
A、Cpu utility应该是综合考虑CPU上各个调度类(cfs、rt、dl)以及irq的utility。然而为了平衡性能和功耗,在某些场景下(例如手机场景),用户空间会通过uclamp机制对用户体验相关的线程进行boost,或者对后台线程进行频率限制。这样,CPU频率的选择并不能完全从负载跟踪模块得到的utility去换算,而是要综合考虑用户空间的uclamp限制。在过去,没有uclamp功能,在计算调频utility的场景下(FREQUENCY_UTIL),只要rq上有rt任务,那么就上报该CPU的最大可能的utility。如果系统使能了uclamp功能并且的确对cfs或者rt任务进行了uclamp,那么我们将采用更精细的频率控制方法(下面会讲)。
B、如果该CPU处理了过多的中断handler(包括软中断),irq负载已经高过CPU的最大算力,那么直接提满频。
|
util = util_cfs + cpu_util_rt(rq);----------------------A if (type == FREQUENCY_UTIL) util = uclamp_rq_util_with(rq, util, p); dl_util = cpu_util_dl(rq);-----------------B if (util + dl_util >= max) return max; if (type == ENERGY_UTIL) util += dl_util; |
A、这里累加了cfs和rt任务的utility,并通根据当前的设置进行clamp。关于uclamp机制,后续我们会其他的文章详细描述,敬请期待。
B、Deadline类型的任务可以从两个不同的层面输出utility,一种是PELT算法下的utility,另外一个是带宽视角下的utility。一般而言,PELT dl utility不应该算入来提频,但这里只是为了判断是否cfs rt和dl已经耗尽了所有的CPU算力,如果是这样,那么直接返回cpu utility的最大值。如果本次调用schedutil_cpu_util是为了计算能耗(ENERGY_UTIL),那么utility需要累计deadline类型的任务,毕竟只要运行就会消耗CPU的能量。
|
util = scale_irq_capacity(util, irq, max);----------A util += irq; if (type == FREQUENCY_UTIL)----------------B util += cpu_bw_dl(rq); return min(max, util); |
A、各种类型任务的PELT跟踪下的utility是在一个timeline下(基于pelt clock),并且窗口也是对齐的,因此它们可以相加起来。Irq utility的计算和这些task utility的计算形式是类似的,但是timeline和窗口并不是对齐的,因此不能直接相加。Irq time并没有计算进入task clock,因此task utility计算值会稍微大一些。这个概念有点类似irq会偷走一部分的cpu算力,从而让其capacity没有那么大。这里通过scale_irq_capacity对任务的utility进行调整。
B、至此,util变量保存了cfs和rt的利用率信息(经过clamp和irq的调整),这里再累加上dl任务的utility。对于频率调整的util,dl任务采用了带宽视角的utility,作为CPU输出算力的最小值,毕竟CPU算力至少要满足dl任务的带宽需要。
3、iowait boost
在sugov中内嵌了iowait boost算法,主要是为了解决轻载下的io吞吐量下降的问题:

在轻载场景下,CPU上往往只有一个重载io的任务在运行。假设目前处于较高的CPU频率状态,这时候CPU的busy的时间比较短,utility比较轻,因此sugov就会将CPU频率降低,从而拉长了任务运行时间,这样,单位时间内下发的io command数量就会降低,从而拉低了io吞吐量。
iowait boost算法过程如下:
(1)当enqueue一个处于iowait状态任务的时候,通过cpufreq_update_util来通知sugov模块发生了一次SCHED_CPUFREQ_IOWAIT类型的cpu utility变化。
(2)在sugov callback函数中调用sugov_iowait_boost来更新该CPU的io wait boost状态。具体更新的规则如下表所示:
|
条件 |
Iowait boost的utility |
|
第一次从io wait状态唤醒中唤醒 |
Iowait boost值设定为IOWAIT_BOOST_MIN,目前设定为128 |
|
已经处于io wait boost状态,但是随后的io wait wakeup并没有连续到来,而是超过了一个tick(即io操作没有那么频繁)才来 |
重置Iowait boost值设定为IOWAIT_BOOST_MIN |
|
已经处于io wait boost状态,但是随后没有新的io wait wakeup到来(即停止了io操作) |
一个tick之后,将Iowait boost值设定为0,结束iowait boost |
|
已经处于io wait boost状态,并且随后的io wait wakeup密集的出现(即短期内有大量的io操作发生) |
把Iowait boost值翻倍,直到1024(即SCHED_CAPACITY_SCALE) |
(3)在调用sugov_get_util函数获取cpu utility之后,通过调用sugov_iowait_apply来应用iowait boost的utility值。如果Iowait boost之后的utility比较大的话,那么用iowait boost utility来替代之前计算的cpu utility。顺便说一句,如果在一个tick内没有联系的pending的iowait boost,那么Iowait boost值会衰减,也就是说,只有在大量io下发的场景中,CPU频率才会维持较高的boost值。
4、计算cluster的utility
对于只有一个cpu的cluster,cpu utility就是cluster的utility,对于cluster内有多个cpu的情况,我们需要遍历cluster中的cpu,找到cluster utility(用来映射cluster频率的utility),具体的代码实现在sugov_next_freq_shared函数中,如下:
|
for_each_cpu(j, policy->cpus) { j_util = sugov_get_util(j_sg_cpu);------------A j_max = j_sg_cpu->max; if (j_util * max > j_max * util) {-------------B util = j_util; max = j_max; } } |
A、获取该CPU的utility和CPU的最大算力
B、大部分的情况下,一个cluster中的CPU其微架构是一样的,因此其最大算力也是一样的,这时候就是选择cpu utility最大的那个就OK了。如果cluster中的CPU微架构不同,那么需要对比的是(utility/capacity)
5、如何将cluster utility映射到具体的频率?
通过get_next_freq函数,我们可以将cluster上指定的utility映射到具体的频率上去:
|
freq = map_util_freq(util, freq, max);---------A if (freq == sg_policy->cached_raw_freq && !sg_policy->need_freq_update) return sg_policy->next_freq;-----------B sg_policy->cached_raw_freq = freq; return cpufreq_driver_resolve_freq(policy, freq);-----C |
A、我们期望utility能够匹配当前算力,什么叫匹配?我们这里采用了20%的余量,即当前utility耗尽80%的目标算力即可(目标算力就是调整到目标频率CPU输出的算力)
B、这里通过map_util_freq映射出来的目标频率并不是最终CPU调整到的频率,不过如果这里计算的频率如果和上次缓存的目标频率一样的话,那么其底层驱动实际调整的频率应该也是一样的,因此这里不会再调用cpufreq_driver_resolve_freq函数来确定实际的CPU频率,直接返回sg_policy->next_freq。
C、底层驱动(硬件)不能支持“无级变速”,因此CPU频率是一张表格,有固定的档位,每一档对应一个CPU频率。在计算得到目标频率之后,还需要将其解析为底层驱动支持的频点。具体的方式有很多种,例如取大于目标频率的最小频点、取小于该目标频率的最大频点,或者最靠近的频点。
6、发起调频
至此,我们已经获得了需要调频的频点,下面就是通知底层驱动软件进行实际的频率调整了。对于单cpu的cluster而言,调频代码如下:
|
if (sugov_cpu_is_busy(sg_cpu) && next_f < sg_policy->next_freq) {-----A next_f = sg_policy->next_freq; sg_policy->cached_raw_freq = cached_freq; } if (sg_policy->policy->fast_switch_enabled) {------B sugov_fast_switch(sg_policy, time, next_f); } else { raw_spin_lock(&sg_policy->update_lock); sugov_deferred_update(sg_policy, time, next_f);-------C raw_spin_unlock(&sg_policy->update_lock); } |
A、如果本次是想要调降频率,但是最近该CPU并没有进入idle状态(runqueue上仍然有任务),这时候立刻调降频率有点为时过早,我们先保持频率不变
B、快速切换频率路径。由于cluster只有一个cpu,而且调用sugov_update_single已经获取了rq lock,因此sugov_fast_switch不需要其他手段来控制并发。
C、慢速切换频率路径。在这个场景下,仅仅rq lock不足以保护并发,因为慢速切换频率需要在sugov kthread上下文进行实际的调频动作,因此需要使用sg_policy->update_lock。
对于sugov_update_shared,其频率切换的逻辑和sugov_update_single类似,只不过sugov policy数据会在多个cpu上并发(无论是快速还是慢速切换频率路径),因此统一使用了update_lock来控制并发。
五、小结
Schedutil governor是标准linux缺省的cpufreq governor,它主要是hook在调度器的负载跟踪模块,当cpu的负载发生变化的时候就会驱动一次调频流程。通过遍历cluster中所有CPU,找到最大的负载来映射到target frequency。底层驱动会根据这个target frequency并结合CPU频率表选择一个最适合的频率设定下去。Schedutil governor虽然是一个优秀的governor,但是在移动平台上它还是有各种各样的缺点。目前各大厂商的工程师也正在优化cpufreq governor,也欢迎热爱技术的你积极参与。
参考文献:
1、内核源代码
2、linux-5.10.61\Documentation\scheduler\*
本文首发在“内核工匠”微信公众号,欢迎扫描以下二维码关注公众号获取最新Linux技术分享:
评论:
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2023-12-18 17:50
弊店に主要な販売する商品は時計,バッグ,財布,ルイヴィトンコピー,エルメスコピー,
シャネルコピー,グッチコピー,プラダコピー,ロレックスコピー,カルティエコピー,オメガコピー,
ウブロ コピーなどの世界にプランド商品です。
2006年に弊社が設立された、
弊社は自社製品を世界中に販売して、高品質な製品と優れたアフターサービスで、
過半数の消費者からの良い評判を獲得していた。
我々自身の生産拠点と生産設備を持って、
製品の質を保証すると消費者にサポートするために、製品も工場で厳格な人工的なテストを受けました。
消費者の継続的なサポートに感謝するために、そして、企業が低コスト、高品質な製品を提供してあげます。
弊店に望ましい製品を見つけることを願って。
ここで、弊社が皆の仕事でも幸せな人生でも成功することを望んてあげます。
誠にありがとうございます。