
PELT算法浅析
作者:OPPO内核团队 发布于:2022-4-7 7:09 分类:进程管理
前言
Linux是一个通用操作系统的内核,她的目标是星辰大海,上到网络服务器,下至嵌入式设备都能运行良好。做一款好的linux进程调度器是一项非常具有挑战性的任务,因为设计约束太多了:
---它必须是公平的
---快速响应
---系统的throughput要高
---功耗要小
3.8版本之前的内核CFS调度器在计算CPU load的时候采用的是跟踪每个运行队列上的负载(per-rq load tracking)。这种粗略的负载跟踪算法显然无法为调度算法提供足够的支撑。为了完美的满足上面的所有需求,Linux调度器在3.8版中引入了PELT(Per-entity load tracking)算法。本文将为您分析PELT的设计概念和具体的实现。
本文出现的内核代码来自Linux5.10.61,如果有兴趣,读者可以配合代码阅读本文。
一、为何需要per-entity load tracking?
完美的调度算法需要一个能够预知未来的水晶球:只有当内核准确地推测出每个线程对系统的需求,她才能最佳地完成任务调度、均衡和算力调整。PELT跟踪的负载包括两个方面:
----CPU/任务的利用率(task utility)
----CPU/任务的负载(task load)
跟踪任务的utility主要是为任务寻找合适算力的CPU。例如在手机平台上4个大核+4个小核的结构。一个任务本身逻辑复杂,需要有很长的执行时间,也就是说其utility比较大,那么需要将其安排到算力和任务utility匹配的CPU上,例如大核CPU上。PELT算法也会跟踪CPU上的utility,根据CPU utility选择提升或者降低该CPU的频率。CPU load和Task load主要用于负载均衡算法,即让系统中的每一个CPU承担和它的算力匹配的任务负载。
3.8版本之前的内核CFS调度器在负载跟踪算法上比较粗糙,采用的是跟踪每个运行队列上的负载(per-rq load tracking)。它并没有跟踪每一个任务的负载和利用率,只是关注整体CPU的负载。对于per-rq的负载跟踪方法,调度器可以了解到每个运行队列对整个系统负载的贡献。这样的统计信息可以帮助调度器平衡runqueue上的负载,但从整个系统的角度看,我们并不知道当前CPU上的负载来自哪些任务,每个任务施加多少负载,当前CPU的算力是否支撑runqueue上的所有任务,是否需要提频或者迁核来解决当前CPU上负载。因此,为了更好的进行负载均衡和CPU算力调整,调度器需要PELT算法来指引方向。
二、PELT算法的基本原理
1、定义
内核用struct sched_avg来抽象一个se或者cfs rq的平均调度负载:
|
成员 |
描述 |
|
last_update_time |
sched avg会定期更新,last_update_time是上次更新的时间点,结合当前的时间值,我们可以计算delta并更新*_sum和*_avg。对task se而言,还有一种特殊情况就是迁移到新的CPU,这时候需要将last_update_time设置为0以便新cpu上可以重新开始计算负载,此外,新任务的last_update_time也会设置为0。 |
|
load_sum runnable_load_sum util_sum |
*_sum的值是几何级数的累加(按照1ms为一个周期,距离当前点越远,衰减的越厉害,32个周期之后的load衰减50%,load_sum就是这些load的累加)。 *_sum的值仅考虑时间因素: 1、load_sum是running+runnable时间 2、util_sum仅统计running时间 3、对于task se,其runnable_load_sum等于util_sum,对于group se,runnable_load_sum综合考虑了其所属cfs上所有任务(整个层级结构中的任务)个数和group se处于running+runnable的时间 |
|
period_contrib |
period_contrib是一个中间计算变量,在更新负载的时候分三段,d1(合入上次更新负载的剩余时间,即不足1ms窗口的时间),d2(满窗时间),d3(不足1ms窗口的时间),period_contrib记录了d3窗口的时间,方便合入下次的d1。具体细节下文会进一步描述。 |
|
load_avg runnable_load_avg util_avg |
*_avg是根据*_sum计算得到的负载均值。 |
|
util_est |
任务阻塞后,其负载会不断衰减。如果一个重载任务阻塞太长时间,那么根据标准PELT算法计算出来的负载会非常的小,当该任务被唤醒重新参与调度的时候,由于负载较小会让调度器做出错误的判断。因此引入了这个成员,记录阻塞之前的load avg信息。 |
从这个数据结构可以看出,平均调度负载实际上包括了平均负载load_avg、平均运行负载runnable_load_avg和平均利用率util_avg。为了简单,后文省略“平均”二字,称这些术语为负载、运行负载和利用率。
2、基本公式
通过上一章,我们了解到PELT算法把负载跟踪算法从per rq推进到per-entity的层次,从而让调度器有了做更精细控制的前提。这里per-entity中的“entity”指的是调度实体(scheduling entity),其实就是一个进程或者control group中的一组进程。为了做到Per-entity的负载跟踪,时间被分成了1024us的序列,在每一个1024us的周期中,一个entity对系统负载的贡献可以根据该实体处于runnable状态(正在CPU上运行或者等待cpu调度运行)的时间进行计算。任务在1024us的周期窗口内的负载其实就是瞬时负载。如果在该周期内,runnable的时间是t,那么该任务的瞬时负载应该和(t/1024)有正比的关系。类似的概念,任务的瞬时利用率应该通过1024us的周期窗口内的执行时间(不包括runqueue上的等待时间)比率来计算。
当然,不同优先级的任务对系统施加的负载也不同(毕竟在cfs调度算法中,高优先级的任务在一个调度周期中会有更多的执行时间),因此计算任务负载也需要考虑任务优先级,这里引入一个负载权重(load weight)的概念。在PELT算法中,瞬时负载Li等于:
|
Li = load weight x (runnable time/1024) |
利用率和负载不一样,它和任务优先级无关,不过为了能够和CPU算力进行运算,任务的瞬时利用率Ui使用下面的公式计算:
|
Ui = Max CPU capacity x (running time/1024) |
在手机环境中,大核最高频上的算力定义为最高算力,即1024。瞬时运行负载的定义类似utility,如下:
|
RLi = Max CPU capacity x (runnable time/1024) |
任务的瞬时负载和瞬时利用率都是一个快速变化的计算量,但是它们并不适合直接调整调度算法,因为调度器期望的是一段时间内保持平稳而不是疲于奔命。例如,在迁移算法中,在上一个1024us窗口中,是满窗运行,瞬时利用率是1024,立刻将任务迁移到大核,下一个窗口,任务有3/4时间在阻塞状态,利用率急速下降,调度器会将其迁移到小核上执行。从这个例子可以看出,用瞬时量来推动调度器的算法不适合,任务会不断在大核小核之间跳来跳去,迁移的开销会急剧加大。为此,我们需要对瞬时负载进行滑动平均的计算,得到平均负载。一个调度实体的平均负载可以表示为:
|
L = L0 + L1*y + L2*y2 + L3*y3 + ... |
Li表示在周期pi中的瞬时负载,对于过去的负载我们在计算的时候需要乘一个衰减因子y。在目前的内核代码中,y是确定值:y ^32等于0.5。这样选定的y值,一个调度实体的负荷贡献经过32个窗口(32 x 1024us)后,对当前时间的的符合贡献值会衰减一半。
通过上面的公式可以看出:
(1)调度实体对系统负荷的贡献值是一个序列之和组成
(2)过去的负荷也会被累计,但是是以递减的方式来影响负载计算。
(3)最近时间点的负荷值拥有最大的权重1,随着时间的推移,权重指数衰减
使用这样序列的好处是计算简单,我们不需要使用数组来记录过去的负荷贡献,只要把上次的总负荷的贡献值乘以y再加上新的L0负荷值就OK了。utility和runnable load的计算也是类似的,不再赘述。
3、关于时间
在上面的公式中,有很多关于时间的部分参与到了运算中,本小节将对PELT算法中的时间进行详细说明。PELT算法中的时间都是来自几个rq clock,如下:
|
成员 |
描述 |
|
u64 clock |
基于sched clock的时间,通过update_rq_clock函数不断驱动这个timeline向前推进 |
|
u64 clock_task |
clock_task这个timeline类似上面的clock,只不过当执行irq的时候,clock_task会停掉,因此,这个clock只会随着任务的执行而不断向前推进。具体clock task更新的方法可以参考update_rq_clock_task函数 |
|
u64 clock_pelt |
PELT用于计算负载的timeline,这个时间是归一化后的时间(上面两个都是未归一化的物理时间)。当CPU idle的时候,clock_pelt会同步到clock_task上去。 |
对于CPU而言,算力处于比较低的水平的时候,同样的任务量要比高算力状态下花费更多的时间。这样,同样的任务量在不同CPU算力的情况下,PELT会跟踪到不同的结果。为了能达到一致性的评估效果,PELT的时间采用归一化时间,即把执行时间归一化到超大核最高频率上去。不过由于归一化,cpu idle的时间被压缩了(一般而言,归一化后的时间会小一些,实际运行时间会长一些),为了解决这个问题,pelt clock在cpu处于idle状态的时候会同步到clock task上去。
归一化的代码如下(update_rq_clock_pelt):
|
delta = cap_scale(delta, arch_scale_cpu_capacity(cpu_of(rq))); delta = cap_scale(delta, arch_scale_freq_capacity(cpu_of(rq))); rq->clock_pelt += delta; |
实际的任务执行时间delta,通过cpu scale和freq scale,归一化到了系统最大算力的CPU上去。
三、内核调度器基本知识
为了能够讲清楚PELT算法,我们本章需要科普一点基本的CFS的基础知识。
1、调度实体
内核用struct sched_entity抽象一个调度实体结构(蓝色成员是组调度相关):
|
成员 |
描述 |
|
load |
调度实体的负载权重。对于task se,该值和nice value相关。对于group se,其值和task group的share值定义以及该group的负载在各个cpu上的排布相关。 |
|
run_node |
挂入cfs rq上的红黑树节点 |
|
group_node |
挂入cpu rq上的cfs task链表节点 |
|
on_rq |
该se是否挂入cfs rq。对于task se而言,当on_rq等于true的时候有两种状态,runnable和running,需要特别说明的是当task se处于running的时候,其并没有挂入cfs rq的红黑树中。当任务阻塞之后,该task se从cfs rq中dequeue,这时候on_rq等于false。 |
|
exec_start sum_exec_runtime Vruntime prev_sum_exec_runtime nr_migrations statistics |
该调度实体各种统计信息,我们在其他文档中描述。 |
|
depth |
该se的深度,顶层的se深度是0,每嵌套一层se,其深度加一。 |
|
parent |
Task group可以嵌套,因此通过parent可以找到上一级task group的se。 |
|
cfs_rq |
该调度实体挂入(或者准备挂入)的那个cfs runqueue |
|
my_q |
该se所属的cfs runqueue。只有group se有所属cfs rq,Task se没有。 |
|
runnable_weight |
该所属cfs rq上的任务数量(整个层级结构上的所有任务数量)。对于task se,这个成员没有意义,对于group se,这个值用来计算该group se所属cfs rq上的所有任务的runnable load,其值等于其所属cfs rq的h_nr_running成员。 |
|
avg |
PELT算法跟踪的该调度实体的平均调度负载。对于task se,avg跟踪的就是该任务的负载、运行负载和利用率。对于group se,这里的avg则是跟踪其所属cfs rq上所有任务的负载、运行负载和利用率情况。 |
上面蓝色字体的成员都是CFS组调度相关的成员,所有的成员都很直观,不再赘述。
2、Cfs任务的运行队列
内核用struct cfs_rq抽象一个管理调度实体的cfs任务运行队列:
|
成员 |
描述 |
|
load |
挂入该cfs rq所有调度实体的负载权重之和 |
|
nr_running |
该cfs rq上处于runnable+running状态调度实体的数目(该层级的),这里的调度实体包括task se和group se |
|
h_nr_running |
Cfs rq会形成层级结构,该成员表示整个cfs rq上处于runnable+running状态的任务数目(所有层级,即以该cfs rq为根的整个hierarchy上所有的任务数目)。 |
|
idle_h_nr_running |
概念类似h_nr_running,只不过统计的是调度策略是SCHED_IDLE的任务数目。 |
|
exec_clock |
该cfs rq上持续有调度实体处于执行状态的时间,主要用于调度统计。 |
|
min_vruntime |
挂在该cfs rq上,所有调度实体的最小的vruntime |
|
tasks_timeline |
缓存leftmost的节点 |
|
Curr Next Last skip |
Curr指向当前调度实体 其他三个用于调度器的buddy算法,在其他文档中详细描述。 |
|
avg |
PELT算法跟踪的该cfs rq的平均负载和平均利用率 |
|
removed |
当一个任务退出或者唤醒后迁移到到其他cpu上的时候,那么原本所在CPU的cfs rq上需要移除该任务带来的负载。由于持rq锁问题,所以先把移除的负载记录在这个成员中,适当的时机再更新之。 |
|
tg_load_avg_contrib |
这个cfs rq向整个task group的负载贡献值 |
|
Propagate prop_runnable_sum |
在负载沿着PELT层级结构传播的时候,Propagate用来判断是否有上传的load,prop_runnable_sum表示上传的负载值 |
|
h_load |
该cfs rq的hierarchy load factor,这个成员用来计算任务的hierarchy load。 |
|
last_h_load_update |
上一次更新cfs rq hierarchy load的时间点(jiffies) |
|
h_load_next |
为了获取任务的hierarchy load(task_h_load函数),需要从顶层cfs向下,依次更新各个level的cfs rq的h_load。因此,这里的h_load_next就是为了形成一个从顶层cfs rq到底层cfs rq的链表(更准确的说是一个cfs rq---se----cfs rq----se的关系链)。 |
|
Rq |
该cfs rq对应的cpu runqueue |
|
Tg |
该cfs rq对应的task group |
Cfs rq有一个成员load保存了挂入该runqueue的调度实体load weight之和。为何要汇总这个load weight值?调度算法中主要有两个运算需要,一个是在计算具体调度实体需要分配的时间片的时候:
|
Se Time slice = sched period x se load weight / cfs rq load weight |
此外,在计算cfs rq的负载的时候,我们也需要load weight之和,下文会详细描述。
在负载均衡的时候,我们需要调配CPU上的runnable load以便达到均衡,为了完成这个目标,我们需要在CPU之间进行任务迁移。然而各个task se的load avg并不能真实反映它对root cfs rq(即对该CPU)的负载贡献,因为task se/cfs rq总是在某个具体level上计算其load avg(因为task se的load weight是其level上的load weight,并不能体现到root cfs rq上)。所以为了计算task对CPU的负载(h_load),我们在各个cfs rq上引入了hierarchy load的概念,对于顶层cfs rq而言,其hierarchy load等于该cfs rq的load avg,随着层级的递进,cfs rq的hierarchy load定义如下:
|
下一层的cfs rq的h_load = 上一层cfs rq的h_load X group se 在上一层cfs负载中的占比 |
在计算task se的h_load的时候,我们就使用如下公式:
|
Task se的h_load = task se的load avg x cfs rq的h_load / cfs rq的load avg |
通过上面的公式,我们把任务对其cfs rq的负载贡献转换成了对CPU runqueue的负载贡献。
3、任务组(task group)
内核用struct task_group来抽象属于同一个control group的一组任务(cpuctrl类型的cgroup组,需要内核支持组调度,具体细节可参考其他文章):
|
成员 |
描述 |
|
Css |
该任务组对应的control group状态信息 |
|
Se、cfs_rq |
假设系统中有N个CPU,那么一个任务组对应N个se,N个cfs rq。 |
|
shares |
该任务组可以分享CPU的比例。和task se的load weight是对等的概念。然而,一个task group的se有N个,因此shares对应的值需要按照一定的规律分配给N个group se |
|
load_avg |
该task group的平均负载,是所有group cfs rq的平均负载之和。这个成员主要是为了计算各个CPU group se的load weight。 |
|
Parent、siblings、children |
构建任务组层级结构的成员 |
在上面的task group成员中,load_avg稍显突兀。虽然task group作为一个调度实体来竞争CPU资源,但是task group是一组task se或者group se(task group可以嵌套)的集合,不可能在一个CPU上进行调度,因此task group的调度实际上在各个CPU上都会发生,因此其load weight(即share成员)需要按照一定的算法分配给各个CPU上的group se,因此这里需要跟踪整个task group的load avg以及该task group在各个CPU上的load avg。
4、基本组件
和调度器相关的基本组件如下:
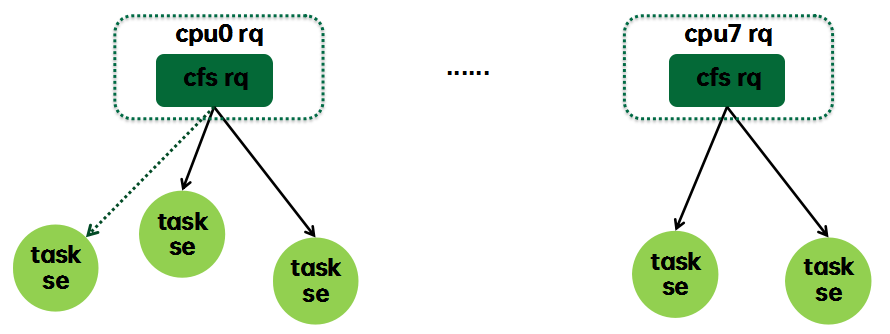
这是当系统不支持组调度时候的形态,每个任务都内嵌一个sched_entity,我们称之task se,每个CPU runqueue上都内嵌调度类自己的runqueue,对于cfs调度类而言就是cfs rq。Cfs rq有一个红黑树,每个处于runnable状态的任务(se)都是按照vruntime的值挂入其所属的cfs rq(实线)。当进入阻塞状态的时候,任务会被挂入wait queue,但是从PELT的角度来看,该任务仍然挂在cfs rq上(虚线),该task se的负载(blocked load)仍然会累计到cfs rq的负载(如上图虚线所示),不过既然该task se进入阻塞状态,那么就会按照PELT算法的规则衰减,计入其上次挂入的cfs rq。
5、构建大厦
当系统支持组调度的时候,cfs rq---se这个基本组件会形成层级结构,如下图所示:
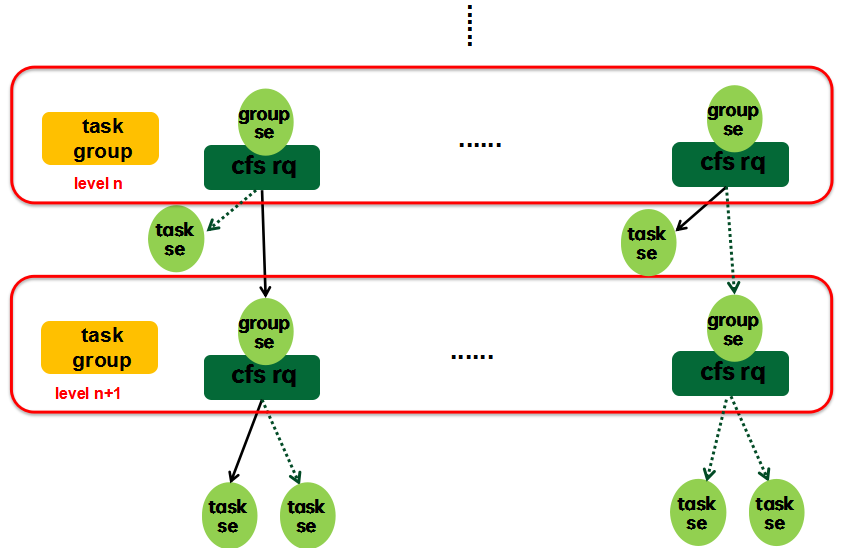
一组任务(task group)作为一个整体进行调度的时候,那么它也就是一个sched entity了,也就是说task group对应一个se。这句话对UP是成立的,然而,在SMP的情况下,系统有多个CPU,任务组中的任务可能遍布到各个CPU上去,因此实际上,task group对应的是一组se,我们称之group se。由于task group中可能包含另外一个task group,因此task group也是形成层级关系,顶层是一个虚拟的root task group,该task group没有对应的group se(都顶层了,不需要挂入其他cfs rq),因而其对应的cfs rq内嵌在cpu runqueue中。
Group se需要管理若干个sched se(可能是task se,也可能是其下的group se),因此group se需要一个对应的cfs rq。对于一个group se,它有两个关联的cfs rq,一个是该group se所挂入的cfs rq:
|
static inline struct cfs_rq *cfs_rq_of(struct sched_entity *se) { return se->cfs_rq; } |
另外一个是该group se所属的cfs rq:
|
static inline struct cfs_rq *group_cfs_rq(struct sched_entity *grp) { return grp->my_q; } |
四、关于负载权重(load weight)
1、load weight
PELT算法中定义了一个struct load_weight的数据结构来表示调度实体的负载权重:
|
struct load_weight { unsigned long weight; u32 inv_weight; }; |
这个数据结构中的weight成员就是负载权重值。inv_weight没有实际的意义,主要是为了快速运算的。struct load_weight可以嵌入到se或者cfs rq中,分别表示se/cfs rq的权重负载。Cfs rq的load weight等于挂入队列所有se的load weight之和。有了这些信息,我们可以快速计算出一个se的时间片信息(这个公式非常重要,让我们再重复一次):
|
Sched slice = sched period x se的权重 / cfs rq的权重 |
CFS调度算法的核心就是在target latency(sched period)时间内,保证CPU资源是按照se的权重来分配的。映射到virtual runtime的世界中,cfs rq上的所有se是完全公平的。
2、如何确定se的load weight?
对于task se而言,load weight是明确的,该值是和se的nice value有对应关系,但是对于group se,load weight怎么设定?这是和task group相关的,当用户空间创建任务组的时候,在其目录下有一个share属性文件,用户空间通过该值可以配置该task group在分享CPU资源时候的权重值。根据上面的描述,我们知道一个task group对应的group se是有若干个的(CPU个数),那么这个share值应该是分配到各个group se中去,即task group se的load weight之和应该等于share值。平均分配肯定不合适,task group se对应的各个cfs rq所挂入的具体任务情况各不相同,具体怎么分配?直觉上来说应该和其所属cfs rq挂入的调度实体权重相关,calc_group_shares函数给出了具体的计算方法,其基本的思想是:

这里的grq就是任务组的group cfs rq,通过求和运算可以得到该任务组所有cfs rq的权重之和。而一个group se的权重应该是按照其所属group cfs rq的权重在该任务组cfs rq权重和的占比有关。当然,由于运算量大,实际代码中做了一些变换,把load weight变成了load avg,具体就不描述了,大家可以自行阅读。
五、负载、运行负载和利用率
1、Se的平均负载和平均利用率
根据上文的计算公式,Task se的平均负载和利用率计算是非常直观的:有了load weight,有了明确的任务状态信息,计算几何级数即可。然而,对于group se而言,任务状态不是那么直观,我们定义其状态如下:只要group se所属cfs rq中有一个处于running状态的se,那么该group se就是running状态(该se其实就是cfs rq->curr)。只要group se所属cfs rq中有一个se处于runnable状态,那么该group se就是runnable状态(se->on_rq表示该状态)。定义清楚group se状态和load weight之后,group se的load avg计算和task se是一毛一样的。
2、cfs rq的平均负载和平均利用率
下面我们看看cfs runqueue的负载计算:
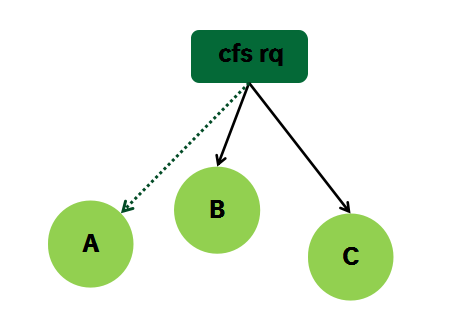
CFS runqueue也内嵌一个load avg数据结构,用来表示cfs rq的负载信息。CFS rq的load avg定义为其下sched entity的负载之和。这里的负载有两部分,一部分是blocked load,另外一部分是runnable load。我们用一个简单的例子来描述:Cfs rq上挂着B和C两个se,还有一个se A进入阻塞状态。当在se B的tick中更新cfs rq负载的时候,这时候需要重新计算A B C三个se的负载,然后求和就可以得到cfs rq的负载。当然,这样的算法很丑陋,当cfs rq下面有太多的sched se的时候,更新cfs rq的计算量将非常的大。内核采用的算法比较简单,首先衰减上一次cfs rq的load(A B C三个se的负载同时衰减),然后累加新的A和B的负载。因为cfs rq的load weight等于A的load weight加上B的load weight,所以cfs rq的load avg计算和sched entity的load avg计算的基本逻辑是一样的。具体可以参考__update_load_avg_se(更新se负载)和__update_load_avg_cfs_rq(更新cfs rq负载)的代码实现。
Cfs rq的平均利用率的思路同上,不再赘述。
3、运行负载
struct sched_avg数据结构中有负载(load_sum/load_avg)和运行负载(runnable_load_sum/runnable_load_avg),这两个有什么不同呢?在回答这个问题之前,我们先思考这样的问题:一个任务进入阻塞态后,它是否还对CPU的负载施加影响?从前文的PELT算法来看,即便任务从cpu runqueue摘下,但是该任务的负载依然存在,还是按照PELT规则进行衰减,并计算入它阻塞前所在的CPU runqueue中(这种负载称为blocked load)。因此,load_sum/load_avg在计算的时候是包括了这些blocked load。负载均衡的时候,我们需要在各个CPU runqueue之间均衡负载(runnable load),如果不支持组调度,那么其实也OK,因为我们通过se->on_rq知道其状态,通过累计CPU上所有se->on_rq==1的se负载可以了解各个CPU上的runnable load并进行均衡。然而,当系统支持cgroup的时候,上述算法失效了,对于一个group se而言,只要其下有一个se是处于runnable,那么group se->on_rq==1。这样,在负载均衡的时候,cpu runqueue的负载中计入了太多的blocked load,从而无法有效的执行负载均衡。
为了解决这个问题,我们引入了runnable load的概念。虽然是叫load,但是实际上它更像utility(未考虑load weight)。对于task se而言,其runnalbe load的计算方法类似util,只不过runnable load是计算runnable+running的时间。对于group se而言,需要一个runnable weight的概念,计算的公式如下:
|
static inline void se_update_runnable(struct sched_entity *se) { if (!entity_is_task(se)) se->runnable_weight = se->my_q->h_nr_running; } |
只有group se才有runnable weight的概念,其值等于其所属cfs rq上的任务数目。即group se的runnable load是考虑该group se所代表的所有running +runnable task的负载,即该group se所属cfs rq上整个层级结构中的所有任务数量。
通过这样的方法,在group se内嵌的load avg中,我们实际上可以得到两个负载,一个是全负载(包括blocked load),另外一个是runnable load。
六、如何计算/更新CFS任务的load avg?
1、概述
内核构建了PELT层级结构之后,还需要日常性的维护这个PELT大厦上各个cfs rq和se节点上的sched avg,以便让任务负载、cfs rq负载(顶层的cfs rq负载就是CPU负载)能够及时更新。update_load_avg函数用来更新任务及其cfs rq的调度负载(也包括util,后续用调度负载指代load,runnable load和utility)。具体的更新的时间点总是和调度事件相关,例如一个任务阻塞的时候,把之前处于running状态的时间增加的调度负载更新到系统中。而在任务被唤醒的时候,需要根据其睡眠时间,对其调度负载进行衰减。具体调用update_load_avg函数的时机包括:
|
调用函数 |
场景 |
|
enqueue_task_fair (UPDATE_TG) enqueue_entity (UPDATE_TG| DO_ATTACH) |
有五个场景如下: a. 任务被唤醒(ttwu_do_activate)或新fork任务被唤醒(wake_up_new_task) b. 任务在CPU间迁移(deactivate_task,activate_task) c. 负载均衡(detach_task,attach_task) d. 任务在Cgroup组内迁移(sched_move_task) e. 修改任务的调度参数(dequeue_task,enqueue_task) 在enqueue_task_fair中,task se一定会调用enqueue_entity完成入队操作,但是在向上遍历整个层级结构的时候,不是每一个group se都需要调用enqueue_entity,只有那些gse->on_rq等于false的调度实体才会调用(即该gse是cfs rq中的第一个调度实体)。因此我们在enqueue_entity会更新负载,而在enqueue_task_fair函数中,也会为那些没有enqueue_entity动作的se和cfs rq进行负载更新。 |
|
dequeue_task_fair (UPDATE_TG) dequeue_entity (UPDATE_TG) |
有五个场景如下: a. 进程进入睡眠状态(__schedule--->deactivate_task) b. 任务在CPU间迁移(deactivate_task,activate_task) c. 负载均衡(detach_task,attach_task) d. 任务在Cgroup组内迁移(sched_move_task) e. 修改任务的调度参数(dequeue_task,enqueue_task) 在场景a中,se从running变成阻塞状态。而在其他场景中,se的状态没有发生变化(马上会enqueue),只是从一个cfs rq转移到另外一个而已。和上面的原因类似,没有全部统一在dequeue_entity中是因为在遍历层级结构的时候,虽然task se一定会执行dequeue_entity,然后中间的group se未必会执行dequeue_entity,只有其所属cfs rq上的所有调度实体全部dequeue之后,该group se才能执行dequeue_entity。 |
|
put_prev_entity (0) |
有两个用户场景: a. 进程切换 b. 修改任务的调度参数 这两个用户场景类似,我们以进程切换为例说明。当任务A切换到任务B执行的时候,首先遍历任务A的se hierarchy,执行put prev entity的操作,然后,遍历B的se hierarchy,执行set next entity的操作。 进程切换又有两中情况:任务被抢占的时候,从running变成runnable状态,更新负载状态。任务阻塞的时候,虽然也执行put prev entity的操作,但是没有进行负载更新,负载更新是在dequeue时候完成的。 |
|
set_next_entity (UPDATE_TG) |
Set_next_entity场景同上,也是进程切换和修改任务的调度参数两种,不再赘述。 |
|
sched_group_set_shares (UPDATE_TG) |
用户空间修改task group的调度参数(share值) |
|
entity_tick函数 (UPDATE_TG) |
被tick命中,状态不变,从running到running。虽然状态不变,但是为了能够及时跟踪running任务的负载,因此需要在tick中更新。 |
|
__update_blocked_fair (UPDATE_TG) |
CPU进入idle状态,并不意味着该CPU上的load avg的负载都是零,原来运行在该CPU的任务负载仍然存在(虽然这些任务阻塞了),只不过是需要不断进行衰减。因此,我们会在下面的场景中对CPU负载进行衰减: a. Nohz idle balance(更新所有idle cpu的blocked load) b. Newidle balance(更新本CPU的blocked load) c. Load balance(更新本CPU的blocked load) |
|
attach_entity_cfs_rq (0) |
调用场景如下: a. 唤醒新创建的任务 b. 从非cfs任务切换成cfs任务 c. cfs任务从一个cgroup组切换成另外一个cgroup组 d. Cgroup online(TODO) |
|
detach_entity_cfs_rq (0) |
调用场景如下: a. Cfs任务切换为其他调度类任务 b. cfs任务从一个cgroup组切换成另外一个cgroup组 |
|
propagate_entity_cfs_rq (UPDATE_TG) |
负载传播 |
在本章的后续小节中,我们选取几个典型的场景具体分析负载更新的细节。
2、一个新建sched entity如何初始化load avg?
Load avg的初始化分成两个阶段,第一个阶段在创建sched entity的时候(对于task se而言就是在fork的时候,对于group se而言,发生在创建cgroup的时候),调用init_entity_runnable_average函数完成初始化,第二个阶段在唤醒这个新创建se的时候,可以参考post_init_entity_util_avg函数的实现。Group se不可能被唤醒,因此第二阶段的se初始化仅仅适用于task se。
在第一阶段初始化的时候,sched_avg对象的各个成员初始化为0是常规操作,不过task se的load avg初始化为最大负载值,即初始化为se的load weight。随着任务的运行,其load avg会慢慢逼近其真实的负载情况。对于group se而言,其load avg等于0,表示没有任何se附着在该group se上。
一个新建任务的util avg设置为0是不合适的,其设定值应该和该task se挂入的cfs队列的负载状况以及CPU算力相关,但是在创建task se的时候,我们根本不知道它会挂入哪一个cfs rq,因此在唤醒一个新创建的任务的时候,我们会进行第二阶段的初始化。具体新建任务的util avg的初始化公式如下:
|
util_avg = cfs_rq->util_avg / (cfs_rq->load_avg + 1) * se.load.weight |
当然,如果cfs rq的util avg等于0,那么任务初始化的util avg也就是0了,这样不合理,这时候任务的util avg被初始化为cpu算力的一半。
完成了新建task se的负载和利用率的初始化之后,我们还会调用attach_entity_cfs_rq函数把这个task se挂入cfs---se的层级结构。虽然这里仅仅是给PELT大厦增加一个task se节点,但是整个PELT hierarchy都需要感知到这个新增的se带来的负载和利用率的变化。因此,除了把该task se的load avg加到cfs的load avg中,还需要把这个新增的负载沿着cfs---se的层级结构向上传播。类似的,这个新增负载也需要加入到task group中。具体请参考attach_entity_cfs_rq函数的实现。
3、在tick中更新load avg
主要的代码路径在entity_tick函数中:
|
update_load_avg(cfs_rq, curr, UPDATE_TG); update_cfs_group(curr); |
在tick中更新load avg是一个层次递进的过程,从页节点的task se开始向上,直到root cfs rq,每次都调用entity_tick来更新该层级的se以及cfs rq的load avg,这是通过函数update_load_avg完成的。更新完load avg之后,由于group cfs rq的状态发生变化,需要重新计算group se的load weight(以及runnable weight),这是通过update_cfs_group函数完成的。
update_load_avg的主要执行过程如下:
(1)更新本层级sched entity的load avg(__update_load_avg_se)
(2)更新该se挂入的cfs rq的load avg(update_cfs_rq_load_avg)
(3)如果是group se,并且cfs---se层级结构有了调度实体的变化(新增或者移除),那么需要处理向上传播的负载。在tick场景中,不需要这个传播过程。
(4)更新该层级task group的负载以及该层级对tg负载的贡献(update_tg_load_avg)。之所以计算task group的load avg,这个值后续会参与计算group se的load weight。
update_cfs_group的主要执行过程如下:
(1)找到该group se所属的cfs rq
(2)调用calc_group_shares计算该group se的load weight
(3)调用reweight_entity重新设定该group se的load weight,并根据这些新的weight值更新group se的负载以及所挂入的cfs rq的负载。注意:这里只是更新load_sum和load_avg,runnable_sum/util_sum和runnable_avg/util_avg和load weight无关,因此不需要更新。
4、任务睡眠时更新load avg
这个场景涉及的主要函数是dequeue_task_fair,是enqueue_task_fair的逆过程。和tick一样,任务休眠过程中更新load avg也是一个层次递进的过程,从页节点的task se开始向上,直到root cfs rq,不断的调用dequeue_entity函数来完成任务阻塞需要处理的逻辑。当然,并不是每一个level都会调用dequeue_entity,必须要该group se所属的sub hierarchy上所有任务都阻塞才会调用。这里我们主要看dequeue_entity函数中和负载相关的代码:
|
update_load_avg(cfs_rq, se, UPDATE_TG);------(1) se_update_runnable(se);------(2) account_entity_dequeue(cfs_rq, se);------(3) update_cfs_group(se);------(4) |
(1)由于任务状态发生变化,因此更新该层次上的se及其挂入cfs rq的负载
(2)由于有任务进入阻塞状态,因此group se的runnable_weight需要更新。需要特别说明的是:在这里我们并没有把load avg从cfs rq中减去,这说明虽然任务阻塞了,但是仍然会对cfs rq的load avg有贡献,只是随着睡眠时间不断衰减。
(3)将该se的load weight从cfs rq的load weight中减去
(4)更新group se的load weight
5、在任务唤醒时更新load avg
任务唤醒更新load avg分成两个部分:
(1)判断任务唤醒之后是否发生迁移。如果没有迁移那么这一步不需要特别的操作。如果唤醒后选择的cpu不是previous cpu,那么本次唤醒是一次迁移,需要调用migrate_task_rq_fair进行一些额外的处理,主要的处理逻辑在remove_entity_load_avg函数中,即把该任务的load avg从cfs load avg中减去。除此之外,还有一个非常重要的操作,把该se load avg的last_update_time清零,即表示在新的cfs rq上,该se的load avg需要对齐到新的cfs rq上去。
(2)通过enqueue task,将该任务的负载增加到新CPU上的PELT hierarchy中。
对于支持组调度的系统,将负载从cfs rq中移除需要沿着PELT hierarchy将负载从各个层级的cfs rq减去。在remove_entity_load_avg中我们只是把需要移除的负载记录在cfs_rq的removed成员中,真正的移除操作是发生在cfs rq负载更新的过程中,具体可以参考update_cfs_rq_load_avg函数。
我们再来看enqueue task,和tick一样,任务唤醒过程中更新load avg也是一个层次递进的过程,从页节点的task se开始向上,直到root cfs rq。不过在遍历中间节点(group se)的时候要判断当前的group se是否在runqueue上,如果没有那么就调用enqueue_entity,否则不需要调用。具体代码在enqueue_task_fair函数中:如果se->on_rq等于0,那么调用enqueue_entity进行负载更新。如果se->on_rq等于1,那么表示表示该group的子节点至少有一个runnable或者running状态的se,这时候不需要entity入队操作,直接调用update_load_avg和update_cfs_group完成负载更新(过程和tick中一致)
在enqueue_entity函数中,相关负载更新代码如下:
|
update_load_avg(cfs_rq, se, UPDATE_TG | DO_ATTACH); se_update_runnable(se); update_cfs_group(se); account_entity_enqueue(cfs_rq, se); |
和tick对比,这个场景下的update_load_avg多传递了一个DO_ATTACH的flag,当一个任务被唤醒的时候发生了迁移,那么PELT层级结构发生了变化,这时候需要负载的传播过程,具体细节我们在下一小节描述。由于队列中增加了一个任务,se_update_runnable函数用来更新cfs rq的runnable weight。update_cfs_group用来更新group se的load weight。account_entity_enqueue函数会更新cfs rq的load weight。
6、负载/利用率的传播
当一个新的task se加入cfs---se的层级结构(也称为PELT hierarchy)的时候,task se的负载会累计到各个level的group se,直到顶层的cfs rq。此外,当任务从一个CPU迁移到另外的CPU上或者任务从一个cgroup移动到另外的cgroup的时候,PELT hierarchy发生变化,都会引起负载的传播过程。我们下面用迁移的task se加入新的cpu PELT hierarchy来描述具体的负载传播细节。
迁移后的任务会通过enqueu_task将任务入队,从而引发各个level上se调用enqueue_entity--->update_load_avg:
|
static inline void update_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags) { ...... if (!se->avg.last_update_time && (flags & DO_ATTACH)) { attach_entity_load_avg(cfs_rq, se); update_tg_load_avg(cfs_rq); } ...... } |
attach_entity_load_avg的主要功能包括:
(1)将se的load avg和load sum(load、runnable load和util)加到cfs rq上去
(2)调用add_tg_cfs_propagate函数,启动传播过程
update_tg_load_avg用来更新task group的负载。
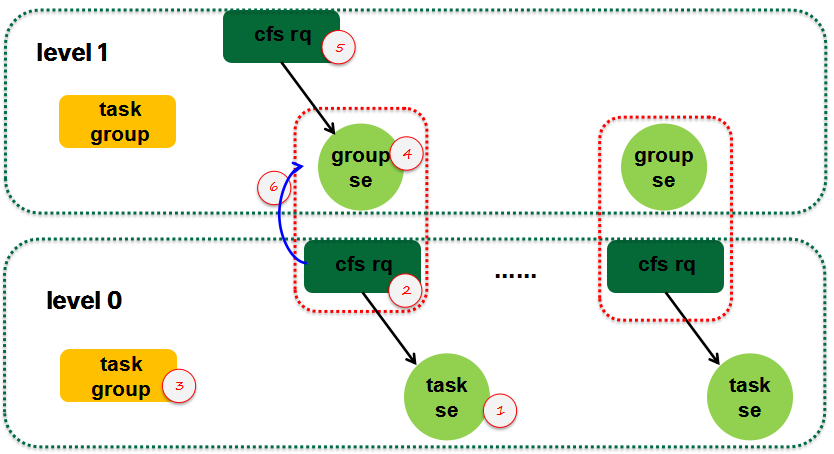
具体负载传播的过程如下:
(1)确定task se的负载,如果需要的话可以执行负载更新动作(唤醒迁移场景不需要)。后续需要把这个新增se负载在整个PELT层级结构中向上传播。
(2)找到该task se所挂入的cfs rq,更新其负载,把task se的负载更新到cfs rq,并记录需要向上传播的负载(add_tg_cfs_propagate)
(3)把task se的负载更新到其所属的task group(update_tg_load_avg)
(4)至此底层level的负载更新完成,现在要进入上一层进行负载更新。首先要更新group se的负载
(5)更新cfs rq的负载,同时要把记录该group se所属的cfs rq上的负载传播到本层级,具体参考propagate_entity_load_avg函数:
|
static inline int propagate_entity_load_avg(struct sched_entity *se) { ...... add_tg_cfs_propagate(cfs_rq, gcfs_rq->prop_runnable_sum);-----a update_tg_cfs_util(cfs_rq, se, gcfs_rq);-----b update_tg_cfs_runnable(cfs_rq, se, gcfs_rq);-----c update_tg_cfs_load(cfs_rq, se, gcfs_rq);-----d ...... } |
这里把level 0 cfs rq的prop_runnable_sum传递到level 1 cfs rq的prop_runnable_sum,以便后续可以继续向上传递。
(6)由于task se的加入,level 0的cfs rq的负载和level 1的group se的负载也已经有了偏差,这里需要更新。通过update_tg_cfs_util函数让group se的utility和其所属的group cfs rq保持同步。通过update_tg_cfs_runnable函数让group se的runnable load和其所属的group cfs rq保持同步。通过update_tg_cfs_load函数让group se的负载和其所属的group cfs rq保持同步。
|
static inline int propagate_entity_load_avg(struct sched_entity *se) { ...... update_tg_cfs_util(cfs_rq, se, gcfs_rq);-----A update_tg_cfs_runnable(cfs_rq, se, gcfs_rq);-----B update_tg_cfs_load(cfs_rq, se, gcfs_rq);-----C ...... } |
A、Group se的util跟随其所属cfs rq的util,同时把新增的util加到group se所挂入的cfs rq
B、Group se的runnable load跟随其所属cfs rq的runnable load,同时把新增的runnable load加到group se所挂入的cfs rq
C、Group se的load跟随其所属cfs rq的load,同时把新增的load加到group se所挂入的cfs rq
(7)更新level 1 task group的负载。然后不断重复上面的过程,直到顶层cfs rq。
七、PELT源代码细节
1、update_load_avg
update_load_avg函数用来更新调度实体及其cfs rq的平均调度负载。
|
static inline void update_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags) { u64 now = cfs_rq_clock_pelt(cfs_rq); int decayed; if (se->avg.last_update_time && !(flags & SKIP_AGE_LOAD)) __update_load_avg_se(now, cfs_rq, se);-------A decayed = update_cfs_rq_load_avg(now, cfs_rq);------B decayed |= propagate_entity_load_avg(se); if (!se->avg.last_update_time && (flags & DO_ATTACH)) {-------C attach_entity_load_avg(cfs_rq, se); update_tg_load_avg(cfs_rq); } else if (decayed) {-----------D cfs_rq_util_change(cfs_rq, 0); if (flags & UPDATE_TG) update_tg_load_avg(cfs_rq); } } |
A、当last_update_time等于0的时候,基本上不需要更新其se负载,因为都已经设定好了。例如新fork出来的task se,其last_update_time等于0,表示不需要更新se的load avg,是缺省设定好的。此外,当任务迁移到新的cpu的时候,该se过去的负载已经在原CPU更新并且会移动到新CPU上,因此会将last_update_time等于0,这样,在加入到新CPU cfs rq时该se的负载不需要更新,但是需要sync到新的cfs rq上来。SKIP_AGE_LOAD表示丢弃旧的load。例如当一个CFS任务短暂的设置为rt,然后又从rt切换成cfs的时候,那么原来的负载是否可以忽略?SKIP_AGE_LOAD就是用来控制如何处理过去负载的。函数__update_load_avg_se是用来更新se的平均调度负载的,下面会详细描述。
B、函数update_cfs_rq_load_avg用来更新cfs rq的平均调度负载的,函数propagate_entity_load_avg是用来在整个PELT hierarchy中传播新加入se带来的负载,下面会详细描述。这里的delay用来跟踪负载更新的状态。我们知道,PELT是按照1ms的窗口来更新平均调度负载的,delay就是表示本次负载更新涉及几个1ms的PELT周期全窗口,如果窗口没有rollover,那么平均调度负载不会更新(仅更新sum值),也就不需要去驱动调频。类似的,如果有传播负载,那么说明CPU上的平均调度负载一定是会发生变化,否则也不需要去驱动调频。
C、当调用enqueue_entity函数将一个Se入队cfs rq时(唤醒或者迁移等)需要附加DO_ATTACH的flag。如果同时满足last_update_time等于0那么说明是任务迁移场景,需要执行attach操作,即把se的平均调度负载加到cfs rq中并在PELT hierarchy中传播。
D、如果需要驱动调频,那么调用cfs_rq_util_change通知cpufreq模块平均调度负载发生变化,看看是否需要进行频率调整。UPDATE_TG这个标记用来控制是否更新task group的平均负载,如果调用者在外部会调用update_tg_load_avg来更新task group负载,那么在update_load_avg则不需要进行task group负载的更新。
2、__update_load_avg_se和__update_load_avg_cfs_rq
__update_load_avg_se和__update_load_avg_cfs_rq这两个函数的逻辑基本一样,都是先调用___update_load_sum来求*_sum值,然后调用___update_load_avg求平均值*_avg。不过,在计算se和cfs rq的平均调度负载的时候传递的参数是不一样的。具体的参数设置如下:
|
参数 |
调度实体se |
调度实体队列cfs rq |
|
load |
se->on_rq,对于task se而言,表示计算任务的Running + runnable时间。对于group se而言,也是计算其Running+runnable时间,不过group se所属cfs rq上只要一个任务是Running或者Runnable的,那么group se就是处于Running or Runnable的。 |
cfs_rq->load.weight 计算的时间是cfs_rq->load.weight x Running+runnable时间。对于cfs rq,sum值包括了load weight,因此调用函数___update_load_avg来计算*_avg的时候,负载参数load传递的是1。 |
|
runnable |
se_runnable(se),对于task se而言,和load计算方法是一样的。对于group se,计算的是处于Running+runnable的任务个数 x Running+runnable的时间 |
cfs_rq->h_nr_running 等于其对应的group se的runnable load |
|
running |
cfs_rq->curr == se。当前正在执行,计算的是running time |
cfs_rq->curr != NULL 只要有属于该cfs rq的任务有在运行就计算其running time |
在计算sum值的时候,runnable和running sum都是进行了scale操作(左移10bit),因此在计算avg的时候,直接除以序列最大值就OK了。通过get_pelt_divider可以获得PELT几何序列的最大值。
3、accumulate_sum
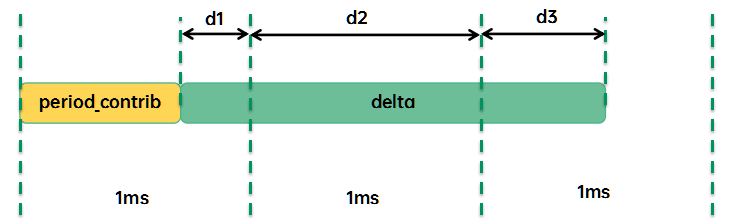
accumulate_sum函数主要用于计算:
(1)调度实体(包括task se和group se两种)的各种load sum(即sched_avg数据结构中的*_sum成员)
(2)Cfs rq的load sum
(3)rt、dl、irq和thermal pressure的load sum
为了方便表述,我们以调度实体为例说明该函数的逻辑。当一个se历经了delta时间的某个状态(load,runnable和running说明了该se的状态),这段时间delta需要累计算入该se平均负载sched_avg的*_sum成员中。
delta时间被分成3段,包括d1、d2、d3:
(1)period_contrib是上次更新负载,没有凑足一个周期(1024us)的剩余时间(即上一次delta中的d3),加上本次的d1将合并成一个完整的1ms PELT窗口。
(2)d2是本次更新,跨越整数个周期的时间段
(3)d3是本次更新,最后那个没有凑足一个周期(1024us)的剩余时间,赋值给period_contrib,它会在下一次更新负载的时候进行计算
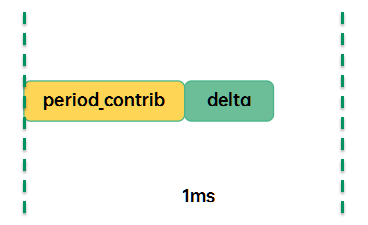
如果本次accumulate_sum没有跨越PELT窗口,那么仅仅累计本次的delta到period_contrib即可,这是accumulate_sum函数返回值是0,表示PELT窗口没有rollover,不需要计算更新load avg。
如果accumulate_sum本次负载更新跨越了一个或者多个PELT窗口,那么运算逻辑要复杂一些,要包括衰减过去的sum值的部分,我们以跨越一个窗口为例:
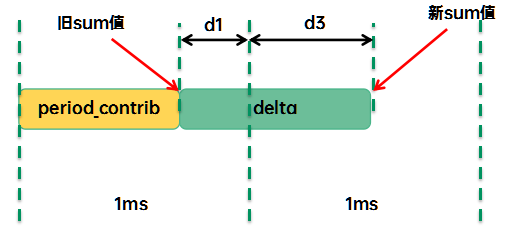
这种情况下,accumulate_sum会把sum值更到新的时间点,具体的运算逻辑是:
(1)调用decay_load,对旧的sum值衰减1个PELT窗口
(2)调用__accumulate_pelt_segments处理delta(d1+d3)
a) 对d1衰减1个PELT窗口
b) d1+d3就是新增的sum值
当跨越n(n>1)个PELT窗口的计算逻辑是类似的,如下:
(1)调用decay_load,对旧的sum值衰减n个PELT窗口
(2)调用__accumulate_pelt_segments处理delta(d1+d2+d3)
a) 对d1衰减n个PELT窗口
b) 计算d2的sum值,即计算(n-1)个满窗sum值
c) d1+d2+d3就是新增的sum值
4、decay_load
decay_load接收两个参数:负载值val和衰减周期n,具体的逻辑如下:
(1)LOAD_AVG_PERIOD(目前设定为32)x 63个周期之后,负载32ms之后衰减一半。(0.5)^63足够小可以直接忽略,因此衰减的结果就是0
(2)如果n没有那么大,那么我们分成两步衰减,一步是LOAD_AVG_PERIOD的整数倍的时间窗口衰减,即每32个周期,通过左移衰减一半。
(3)第二步是非LOAD_AVG_PERIOD的整数倍的时间窗口衰减,这部分可以通过查表获得。
实际上,在decay_load中并没有正面计算几何序列,而是通过优化让decay_load非常的轻盈。
参考文献:
1、内核源代码
2、linux-5.10.61\Documentation\scheduler\*
本文首发在“内核工匠”微信公众号,欢迎扫描以下二维码关注公众号获取最新Linux技术分享:
标签: PELT
评论:
2022-07-17 22:01
有一个疑问希望能得到博主的解答。
在通过 *sum 计算 *avg 的时候,为什么是除以几何级数的最大值?
按照linux中源码注释以及各处看到的公式,这里貌似除1024就可以了?:(
static __always_inline void
___update_load_avg(struct sched_avg *sa, unsigned long load)
{
u32 divider = get_pelt_divider(sa);
/*
* Step 2: update *_avg.
*/
sa->load_avg = div_u64(load * sa->load_sum, divider);
sa->runnable_avg = div_u64(sa->runnable_sum, divider);
WRITE_ONCE(sa->util_avg, sa->util_sum / divider);
}
看了博文这里的解释,还是一头雾水:在计算sum值的时候,runnable和running sum都是进行了scale操作(左移10bit),因此在计算avg的时候,直接除以序列最大值就OK了。通过get_pelt_divider可以获得PELT几何序列的最大值。
博主能详细解答一下么?非常感谢。
2022-07-26 11:14
如果理解错了,请博主指正。
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2022-07-28 10:02
*_avg 就是在 [1024us, 1024us, ...] 这个时间序列的对应指标统计的加权平均.
*_avf 的分母完全是由它的数学定义推导而来的,其原始定义其实就是一个 Exponential Moving Average,分母的推导可以看http://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average.