
slub分配器
作者:itrocker 发布于:2015-12-21 18:51 分类:内存管理
Linux的物理内存管理采用了以页为单位的buddy
system(伙伴系统),但是很多情况下,内核仅仅需要一个较小的对象空间,而且这些小块的空间对于不同对象又是变化的、不可预测的,所以需要一种类似用户空间堆内存的管理机制(malloc/free)。然而内核对对象的管理又有一定的特殊性,有些对象的访问非常频繁,需要采用缓冲机制;对象的组织需要考虑硬件cache的影响;需要考虑多处理器以及NUMA架构的影响。90年代初期,在Solaris
2.4操作系统中,采用了一种称为“slab”(原意是大块的混凝土)的缓冲区分配和管理方法,在相当程度上满足了内核的特殊需求。
多年以来,SLAB成为linux kernel对象缓冲区管理的主流算法,甚至长时间没有人愿意去修改,因为它实在是非常复杂,而且在大多数情况下,它的工作完成的相当不错。但是,随着大规模多处理器系统和 NUMA系统的广泛应用,SLAB 分配器逐渐暴露出自身的严重不足:
1). 缓存队列管理复杂;
2). 管理数据存储开销大;
3). 对NUMA支持复杂;
4). 调试调优困难;
5). 摒弃了效果不太明显的slab着色机制;
针对这些SLAB不足,内核开发人员Christoph Lameter在Linux内核2.6.22版本中引入一种新的解决方案:SLUB分配器。SLUB分配器特点是简化设计理念,同时保留SLAB分配器的基本思想:每个缓冲区由多个小的slab 组成,每个 slab 包含固定数目的对象。SLUB分配器简化kmem_cache,slab等相关的管理数据结构,摒弃了SLAB
分配器中众多的队列概念,并针对多处理器、NUMA系统进行优化,从而提高了性能和可扩展性并降低了内存的浪费。为了保证内核其它模块能够无缝迁移到SLUB分配器,SLUB还保留了原有SLAB分配器所有的接口API函数。
(注:本文源码分析基于linux-4.1.x)
整体数据结构关系如下图所示:
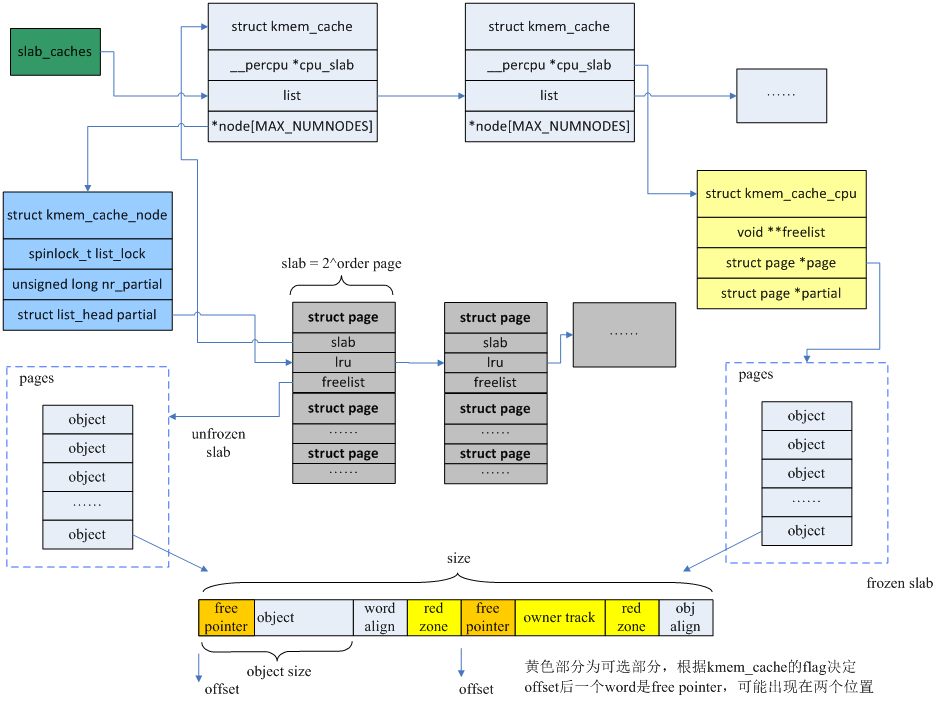
1
SLUB分配器的初始化
SLUB初始化有两个重要的工作:第一,创建用于申请struct kmem_cache和struct kmem_cache_node的kmem_cache;第二,创建用于常规kmalloc的kmem_cache。
1.1 申请kmem_cache的kmem_cache
第一个工作涉及到一个“先有鸡还是先有蛋”的问题,因为创建kmem_cache需要从kmem_cache的缓冲区申请,而这时候还没有创建kmem_cache的缓冲区。kernel的解决办法是先用两个静态变量boot_kmem_cache和boot_kmem_cache_node来保存struct kmem_cach和struct kmem_cache_node缓冲区管理数据,以两个静态变量为基础申请大小为struct kmem_cache和struct kmem_cache_node对象大小的slub缓冲区,随后再从这些缓冲区中分别申请两个kmem_cache,然后把boot_kmem_cache和boot_kmem_cache_node中的内容拷贝到新申请的对象中,从而完成了struct kmem_cache和struct kmem_cache_node管理结构的bootstrap(自引导)。
void __init kmem_cache_init(void)
{
//声明静态变量,存储临时kmem_cache管理结构
static __initdata struct kmem_cache boot_kmem_cache,
boot_kmem_cache_node;
•••
kmem_cache_node = &boot_kmem_cache_node;
kmem_cache = &boot_kmem_cache;
//申请slub缓冲区,管理数据放在临时结构中
create_boot_cache(kmem_cache_node, "kmem_cache_node",
sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN);
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN);
//从刚才挂在临时结构的缓冲区中申请kmem_cache的kmem_cache,并将管理数据拷贝到新申请的内存中
kmem_cache = bootstrap(&boot_kmem_cache);
//从刚才挂在临时结构的缓冲区中申请kmem_cache_node的kmem_cache,并将管理数据拷贝到新申请的内存中
kmem_cache_node = bootstrap(&boot_kmem_cache_node);
•••
}
1.2 创建kmalloc常规缓存
原则上系统会为每个2次幂大小的内存块申请一个缓存,但是内存块过小时,会产生很多碎片浪费,所以系统为96B和192B也各自创建了一个缓存。于是利用了一个size_index数组来帮助确定小于192B的内存块使用哪个缓存
void __init create_kmalloc_caches(unsigned long flags)
{
•••
/*使用SLUB时KMALLOC_SHIFT_LOW=3,KMALLOC_SHIFT_HIGH=13
也就是说使用kmalloc能够申请的最小内存是8B,最大内存是8KB
申请内存是向上对其2的n次幂,创建对应大小缓存保存在kmalloc_caches [n]*/
for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {
if (!kmalloc_caches[i]) {
kmalloc_caches[i] = create_kmalloc_cache(NULL,
1 << i, flags);
}
/*
* Caches that are not of the two-to-the-power-of size.
* These have to be created immediately after the
* earlier power of two caches
*/
/*有两个例外,大小为64~96B和128B~192B,单独创建了两个缓存
保存在kmalloc_caches [1]和kmalloc_caches [2]*/
if (KMALLOC_MIN_SIZE <= 32 && !kmalloc_caches[1] && i == 6)
kmalloc_caches[1] = create_kmalloc_cache(NULL, 96, flags);
if (KMALLOC_MIN_SIZE <= 64 && !kmalloc_caches[2] && i == 7)
kmalloc_caches[2] = create_kmalloc_cache(NULL, 192, flags);
}
•••
}
2 缓存的创建与销毁
2.1 缓存的创建
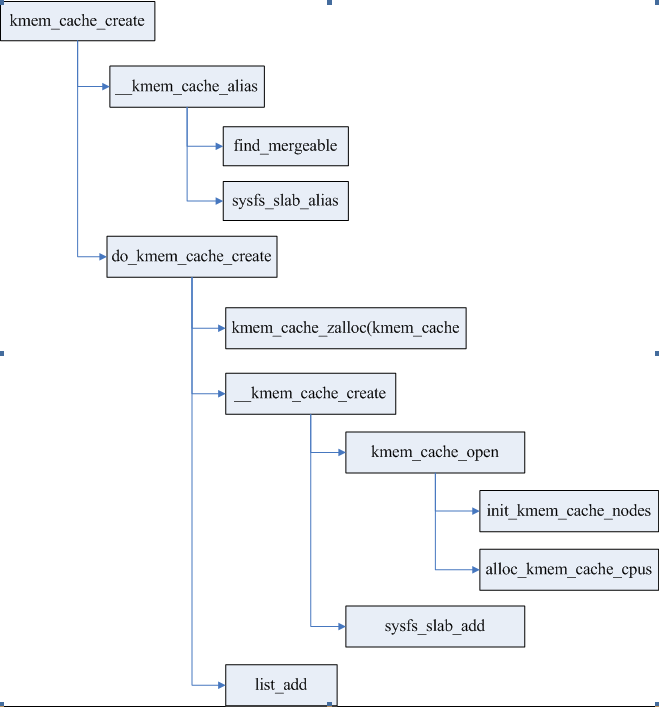
创建缓存通过接口kmem_cache_create进行,在创建新的缓存以前,尝试找到可以合并的缓存,合并条件包括对对象大小以及缓存属性的判断,如果可以合并则直接返回已存在的kmem_cache,并创建一个kobj链接指向同一个节点。
创建新的缓存主要是申请管理结构暂用的空间,并初始化,这些管理结构包括kmem_cache、kmem_cache_nodes、kmem_cache_cpu。同时在sysfs创建kobject节点。最后把kmem_cache加入到全局cahce链表slab_caches中。
2.2 缓存的销毁
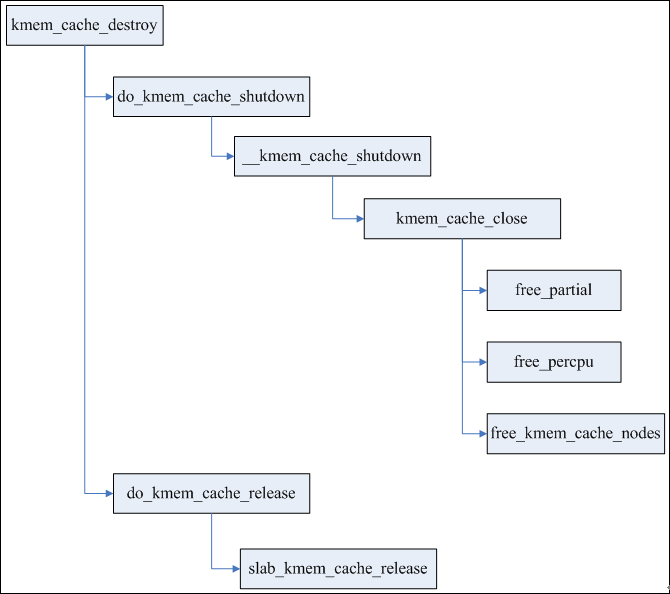
销毁过程比创建过程简单的多,主要工作是释放partial队列所有page,释放kmem_cache_cpu,释放每个node的kmem_cache_node,最后释放kmem_cache本身。
3 申请对象
对象是SLUB分配器中可分配的内存单元,与SLAB相比,SLUB对象的组织非常简洁,申请过程更加高效。SLUB没有任何管理区结构来管理对象,而是将对象之间的关联嵌入在对象本身的内存中,因为申请者并不关心对象在分配之前内存的内容是什么。而且各个SLUB之间的关联,也利用page自身结构进行处理。
每个CPU都有一个slab作为本地高速缓存,只要slab所在的node与申请者要求的node匹配,同时该slab还有空闲对象,则直接在cpu_slab中取出空闲对象,否则就进入慢速路径。
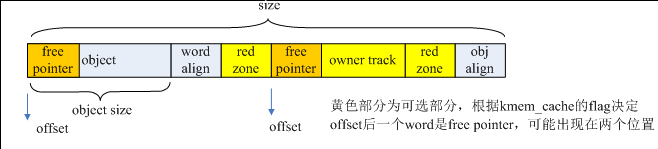
每个对象内存的offset偏移位置都存放着下一个空闲对象,offset通常为0,也就是复用对象内存的第一个字来保存下一个空闲对象的指针,当满足条件(flags & (SLAB_DESTROY_BY_RCU | SLAB_POISON)) 或者有对象构造函数时,offset不为0,每个对象的结构如下图。
cpu_slab的freelist则保存着当前第一个空闲对象的地址。
如果本地CPU缓存没有空闲对象,则申请新的slab;如果有空闲对象,但是内存node不相符,则deactive当前cpu_slab,再申请新的slab。
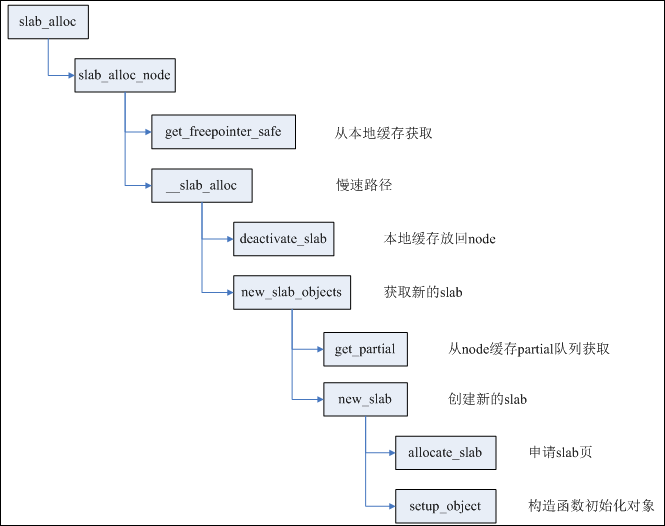
deactivate_slab主要进行两步工作:
第一步,将cpu_slab的freelist全部释放回page->freelist;
第二部,根据page(slab)的状态进行不同操作,如果该slab有部分空闲对象,则将page移到kmem_cache_node的partial队列;如果该slab全部空闲,则直接释放该slab;如果该slab全部占用,而且开启了CONFIG_SLUB_DEBUG编译选项,则将page移到full队列。
page的状态也从frozen改变为unfrozen。(frozen代表slab在cpu_slub,unfroze代表在partial队列或者full队列)。
申请新的slab有两种情况,如果cpu_slab的partial队列不为空,则取出队列中下一个page作为新的cpu_slab,同时再次检测内存node是否相符,还不相符则循环处理。
如果cpu_slab的partial队列为空,则查看本node的partial队列是否为空,如果不空,则取出page;如果为空,则看一定距离范围内其它node的partial队列,如果还为空,则需要创建新slab。
创建新slab其实就是申请对应order的内存页,用来放足够数量的对象。值得注意的是其中order以及对象数量的确定,这两者又是相互影响的。order和object数量同时存放在kmem_cache成员kmem_cache_order_objects中,低16位用于存放object数量,高位存放order。order与object数量的关系非常简单:((PAGE_SIZE << order) - reserved) / size。
下面重点看calculate_order这个函数
static inline int calculate_order(int size, int reserved)
{
•••
//尝试找到order与object数量的最佳配合方案
//期望的效果就是剩余的碎片最小
min_objects = slub_min_objects;
if (!min_objects)
min_objects = 4 * (fls(nr_cpu_ids) + 1);
max_objects = order_objects(slub_max_order, size, reserved);
min_objects = min(min_objects, max_objects);
//fraction是碎片因子,需要满足的条件是碎片部分乘以fraction小于slab大小
// (slab_size - reserved) % size <= slab_size / fraction
while (min_objects > 1) {
fraction = 16;
while (fraction >= 4) {
order = slab_order(size, min_objects,
slub_max_order, fraction, reserved);
if (order <= slub_max_order)
return order;
//放宽条件,容忍的碎片大小增倍
fraction /= 2;
}
min_objects--;
}
//尝试一个slab只包含一个对象
order = slab_order(size, 1, slub_max_order, 1, reserved);
if (order <= slub_max_order)
return order;
//使用MAX_ORDER且一个slab只含一个对象
order = slab_order(size, 1, MAX_ORDER, 1, reserved);
if (order < MAX_ORDER)
return order;
return -ENOSYS;
}
4 释放对象
从上面申请对象的流程也可以看出,释放的object有几个去处:
1)cpu本地缓存slab,也就是cpu_slab;
2)放回object所在的page(也就是slab)中;另外要处理所在的slab:
2.1)如果放回之后,slab完全为空,则直接销毁该slab;
2.2)如果放回之前,slab为满,则判断slab是否已被冻结;如果已冻结,则不需要做其他事;如果未冻结,则将其冻结,放入cpu_slab的partial队列;如果cpu_slab partial队列过多,则将队列中所有slab一次性解冻到各自node的partial队列中。
值得注意的是cpu partial队列的功能是个可选项,依赖于内核选项CONFIG_SLUB_CPU_PARTIAL,如果没有开启,则不使用cpu partial队列,直接使用各个node的partial队列。
评论:
2017-08-08 14:14
这个注释已经说的很明白了:
* We should guarantee that tid and kmem_cache are retrieved on
* the same cpu. It could be different if CONFIG_PREEMPT so we need
* to check if it is matched or not.
就是要保证tid和kmem_cache属于同一个CPU。
无论此时发生了多少抢占,一直等到相同,再配合后面的barrier(),就能达到目的。
2017-08-08 14:54
原来它的目的是为了解决slab_alloc_node中Fastpath下进程迁移的问题.
对于Slowpath则用另一套方案:关中断并重新读取当前CPU的kmem_cache.
但是 while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid))); 中,
tid != READ_ONCE(c->tid)不同的CPU也可能相等啊,也就是说此While循环并不能百分百的保证tid和kmem_cache属于同一个CPU吧?
2017-08-08 16:13
mm/slub.c
#ifdef CONFIG_PREEMPT
/*
* Calculate the next globally unique transaction for disambiguiation
* during cmpxchg. The transactions start with the cpu number and are then
* incremented by CONFIG_NR_CPUS.
*/
#define TID_STEP roundup_pow_of_two(CONFIG_NR_CPUS)
#else
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2017-08-08 11:01
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
//钩子函数 可以做一些事情 比如测试和mmcgroup?
s = slab_pre_alloc_hook(s, gfpflags);
if (!s)
return NULL;
redo:
/*
* Must read kmem_cache cpu data via this cpu ptr. Preemption is
* enabled. We may switch back and forth between cpus while
* reading from one cpu area. That does not matter as long
* as we end up on the original cpu again when doing the cmpxchg.
*
* We should guarantee that tid and kmem_cache are retrieved on
* the same cpu. It could be different if CONFIG_PREEMPT so we need
* to check if it is matched or not.
*/
//看了一段时间 看不懂这里为何这么写
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
这个问题是不是可以归纳为:内核是如何解决在slab函数期间发生中断导致抢占与进程迁移的问题?