
perfbook memory barrier(14.2章节)的中文翻译(上)
作者:linuxer 发布于:2015-12-25 12:18 分类:内核同步机制
perfbook是一本值得反复阅读的好书,这一点是毋庸置疑的,不过你是选择阅读中文版本还是英文版本呢?当然,阅读中文版本相对要简单一些,毕竟是母语,而且最重要的是阅读速度快(注:perfbook已经有了中文版本的翻译,叫做《深入理解并行编程V2.0》,多谢谢宝友/鲁阳/陈渝的辛苦劳动),其实,每次遇到“快”的时候,我都本能的都要停下来再思考一下,我担心欲速则不达。知识的获取不可能是快的,就像看电影,当时的愉快的记忆不久就会被时间抹去。因此,最终我选择了阅读英文版(参考中文版本),并顺便将我阅读的部分翻译出来。与其说是翻译给大家看,不如说是翻译给自己看,让自己对memory barrier的理解更深入一些。
本文是对perfbook 14.2章节的中文翻译的上半部分,包括14.2.1小节到14.2.6小节。
14.2 Memory Barriers
Causality and sequencing are deeply intuitive, and hackers often tend to have a much stronger grasp of these concepts than does the general population. These intuitions can be extremely powerful tools when writing, analyzing,
and debugging both sequential code and parallel code that makes use of standard mutual-exclusion mechanisms,
such as locking and RCU.
什么是“Causality ”?其实就是因果关系,例如:A事件发生了(因)必然导致B事件(果)的发生,逻辑角度讲,我们称A是B的充分条件(sufficient condition)。如果B事件(果)发生了,必然可以推导出A事件的发生(因),那么我们称A是B的必要条件(necessary condition)。sequencing是定序的意思,简单的讲(这里的定义绝非专业,也许只适合本文的场景)就是定义一系列事件在时间值上的顺序。推导因果关系和事件排序都是非常直觉的东西,黑客往往比我们普通人更好的掌握了这些概念,因此他们可以纵横于江湖,仅留下传说。无论是顺序执行的代码或者并行执行的代码,都会使用标准的互斥机制来进行临界区的保护,比如锁或者RCU。如果我们象黑客那样拥有了对因果关系、事件排序等逻辑分析能力之后,就等于掌握了强大的工具,因而可以在撰写、分析或者调试这些使用互斥机制的代码的时候,做到气定神闲,游刃有余。
Unfortunately, these intuitions break down completely in face of code that makes direct use of explicit memory barriers for data structures in shared memory (driver writers making use of MMIO registers can place greater trust in their intuition, but more on this later). The following sections show exactly where this intuition breaks down, and then puts forward a mental model of memory barriers that can help you avoid these pitfalls.
如果你想一直编写仅仅使用标准互斥机制的代码的话,生活还是很美好的,你直觉上的逻辑推理都是成立的。然而,不幸的是:当你显式的使用memory barrier来保护共享内存中的数据结构的时候,直觉被打破了(驱动程序员在通过MMIO寄存器的访问实现驱动逻辑的时候可以对这种直觉多一些信任,我们随后会描述)。我们随后的章节会告诉你,直觉上的逻辑推导和操作顺序为何被打破了,同时也会推出memory barrier的思维模型,一旦建立这个思维模型,你就可以避免出现程序逻辑上的缺陷。
Section 14.2.1 gives a brief overview of memory ordering and memory barriers. Once this background is in place, the next step is to get you to admit that your intuition has a problem. This painful task is taken up by Section 14.2.2, which shows an intuitively correct code fragment that fails miserably on real hardware, and by Section 14.2.3, which presents some code demonstrating that scalar variables can take on multiple values simultaneously. Once your intuition has made it through the grieving process, Section 14.2.4 provides the basic rules that memory barriers follow, rules that we will build upon. These rules are further refined in Sections 14.2.5 through 14.2.14.
14.2.1小节简单的介绍了memory order和memory barrier。一旦建立了相关的背景知识,那么我们下一步就会带你去看看你的直觉为何会存在问题。14.2.2小节会展示这个痛苦的过程:当你看到一个你直觉上逻辑是正确的代码片段,在真实的硬件上却得到错误的结果,我相信你的内心是崩溃的。不过,请坚持住,我们在14.2.3小节中给出示例代码,详细的展示为何变量会在某个一个具体的时刻有多个值,它是造成逻辑混乱的主要原因。一旦你明白了这个道理,你就可以穿越痛苦,拥抱真理。14.2.4小节给出了使用memory barrier需要遵守的基本规则,这些规则会在14.2.5到14.2.14这些小节中给出进一步的解析。
14.2.1 Memory Ordering and Memory Barriers
But why are memory barriers needed in the first place? Can’t CPUs keep track of ordering on their own? Isn’t that why we have computers in the first place, to keep track of things?
我们需要首先搞明白一个问题:为什么memory barrier会存在?难道CPU自己不能跟踪memory order并搞定它吗?难道我们使用计算机不就是为了能够跟踪各种事情吗?
Many people do indeed expect their computers to keep track of things, but many also insist that they keep track of things quickly. One difficulty that modern computer-system vendors face is that the main memory cannot keep up with the CPU – modern CPUs can execute hundreds of instructions in time required to fetch a single variable from memory. CPUs therefore sport increasingly large caches, as shown in Figure 14.1. Variables that are heavily used by a given CPU will tend to remain in that CPU’s cache, allowing high-speed access to the corresponding data.
当然,大部分的人的确是期待自己游手好闲(不用管什么memory barrier),而是让他们的计算机忙于跟踪各种事情,不过更多的人也希望计算机能够高性能的跟踪各种事情。为了达成这个目标,现代的计算机系统提供商遇到一个问题:memory的速度无法跟上CPU的速度,而且速度差别很大,计算机从memory读取一个变量的时间足够CPU执行几百条指令了。为了解决memory速度瓶颈的问题,在系统设计的时候增加了cache这样的组件,具体如下图所示:
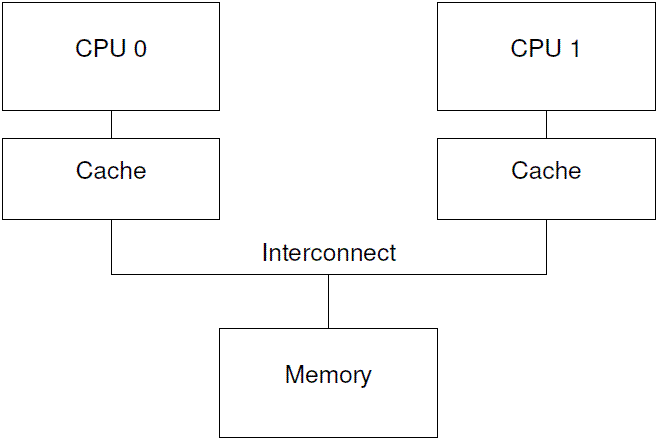
在这样的结构下,某个CPU经常使用的变量会保存在该CPU的cache中,从而让CPU在访问变量的时候可以高速执行。
Unfortunately, when a CPU accesses data that is not yet in its cache will result in an expensive “cache miss”, requiring the data to be fetched from main memory. Doubly unfortunately, running typical code results in a significant number of cache misses. To limit the resulting performance degradation, CPUs have been designed to execute other instructions and memory references while waiting for a cache miss to fetch data from memory. This clearly causes instructions and memory references to execute out of order, which could cause serious confusion, as illustrated in Figure 14.2. Compilers and synchronization primitives (such as locking and RCU) are responsible for maintaining the illusion of ordering through use of “memory barriers” (for example, smp_mb() in the Linux kernel). These memory barriers can be explicit instructions, as they are on ARM, POWER, Itanium, and Alpha, or they can be implied by other instructions, as they are on x86.
不幸的是CPU在访问数据的时候,数据不一定总是在cache中,如果不在的话讲遭遇cache miss,这时候数据访问的开销很大,因为这需要从main memory中加载数据到cache中。更不幸的是在典型的代码执行过程中,CPU会遭遇非常多的cache miss。为了让CPU性能下降在一个限定的范围内,CPU的设计者采用了一个大胆的做法:即让CPU去执行其他的指令和内存访问而不需要等待cache miss的那条指令。这个方法虽然提高的CPU的性能,但是毫无疑问导致了指令的执行和memory的访问变得和program order不一致了,我们可以通过下面这幅图片来描述CPU的这种乱序(out of order)行为:

图中,小企鹅(代表linux kernel)眼神迷茫,因为CPU说的话不是按照顺序表述的。不过没有关系,编译器和同步原语(例如锁或者RCU)可以使用memory barrier(例如linux kernel中的smp_mb())来保持CPU的代码执行以及内存访问顺序是和program order一致的。这些memory barrier可以是一条CPU的汇编指令,比如在ARM, POWER, Itanium, 和Alpha CPU上都有相关的指令。memory barrier也可以是隐含在其他指令中,例如X86(操作IO port的指令都隐含了memory barrier的功能)。
Since the standard synchronization primitives preserve the illusion of ordering, your path of least resistance is to stop reading this section and simply use these primitives.
However, if you need to implement the synchronization primitives themselves, or if you are simply interested in understanding how memory ordering and memory barriers work, read on!
The next sections present counter-intuitive scenarios that you might encounter when using explicit memory barriers.
你也许面对CPU的这种out of order的行为有本能的抵抗,没有关系,放轻松,你的抵抗之路可以到此结束,只要你愿意使用各种同步原语来保护你程序中的共享资源,因为透过这些标准的同步原语,你看到的是一个顺序执行的世界。当然,这会引入一些小小的遗憾:你不知道底层到底是如何把“乱序”变成“有序”的。不过,实现同步原语的那些软件工程师没有这个豁免权,他们必须要深入理解memory order和memory barrier。此外,那些想要“打破沙锅问到底”以及想要“知其然知其所以然”的工程师也可以跟随我们继续。下一节我们将向您展示几个直觉不靠谱的场景。
14.2.2 If B Follows A, and C Follows B, Why Doesn’t C Follow A?
Memory ordering and memory barriers can be extremely counter-intuitive. For example, consider the functions shown in Figure 14.3 executing in parallel where variables A, B, and C are initially zero:
Intuitively, thread0() assigns to B after it assigns to A, thread1() waits until thread0() has assigned to B before assigning to C, and thread2() waits until thread1() has assigned to C before referencing A. Therefore, again intuitively, the assertion on line 21 cannot possibly fire.
真实CPU上运行的程序逻辑可能会由于Memory ordering和memory barriers 而变得诡异,和我们通常的直觉相悖。例如下面的这个程序片段的执行情况:
1 thread0(void)
2 {
3 A = 1;
4 smp_wmb();
5 B = 1;
6 }
7
8 thread1(void)
9 {
10 while (B != 1)
11 continue;
12 barrier();
13 C = 1;
14 }
15
16 thread2(void)
17 {
18 while (C != 1)
19 continue;
20 barrier();
21 assert(A != 0);
22 }
开始,变量A,B,C的初始值都是0。根据程序逻辑:thread0中,A先于B赋值,thread1中,程序逻辑是一直等到B变量被赋值为1之后,再给C赋值。这里,人类的直觉告诉我们,如果变量C已经被赋值为1的时候(第13行程序),A一定已经被赋值为1了。同样的,在thread2中,第21行程序的assert一定是不会被触发的。
This line of reasoning, intuitively obvious though it may be, is completely and utterly incorrect. Please note that this is not a theoretical assertion: actually running this code on real-world weakly-ordered hardware (a 1.5GHz 16-CPU POWER 5 system) resulted in the assertion firing 16 times out of 10 million runs. Clearly, anyone who produces code with explicit memory barriers should do some extreme testing – although a proof of correctness might be helpful, the strongly counter-intuitive nature of the behavior of memory barriers should in turn strongly limit one’s trust in such proofs. The requirement for extreme testing should not be taken lightly, given that a number of dirty hardware-dependent tricks were used to greatly increase the probability of failure in this run.
上一节的推理从直觉上看是对的,但是在实际的CPU上运行的结果确是完全错误的。特别需要指出的是这个结果不是理论推导得出来的,是在真实的1.5GHz 16核的POWER 5系统(该cpu的内存模型属于weakly order)上观测得到的,平均每1千万次执行会有16次在21行代码处出现assert失败。很显然,当我们撰写显式调用memory barrier的代码的时候,必须进行非常大量的实际测试。在理论上进行正确性的推导是否有意义呢?也许有帮助,但是,你知道的,在使用memory barrier的时候会发生很多和你的直觉相悖的东西,这让理论的推导变得不那么确定。别小看那些看起来愚蠢的、非常重复性的大量测试,要知道不同的CPU会使用不同的硬件设计方法,因此在memory order和memory barrier方面表现各不相同,你的程序想要在各种硬件上,每次都运行成功不是一件容易的事情。
注:下面一段是我自己添加的,属于自己的理解。
到底发生了什么让程序在21行的assert上失败?我们一起分析一下。我们假设CPU0、CPU1和CPU2分别执行thread0、thread1和thread2。对于thread 1,我们假设A在CPU0的local cache中,但是状态是shared,因此当执行A=1的语句的时候,不能立刻执行,需要和其他CPU cache进行沟通(发送invalidate message去其他CPU),当然,cpu不会停下其脚步,将A的新值1放入store buffer,继续执行。smp_wmb可以mark store buffer中A值,并且阻止后续的store操作进入cache,这时候,即便B在CPU0的local cache中,B=1的赋值也不能操作到cache,而是要进入store buffer,当然状态是unmarked。由于存在Invalidate Queue这中东西,因此,CPU 0很快就可以收到来自其他CPU的相应,这时候,CPU0可以越过write memory barrier,完成对B的赋值。因此,对于thread1,很快可以感知B的新值“1”并执行了对C变量的赋值。来到thread2,同样的,对C变量的load操作也可以感知到thread1中的赋值因此跳出while循环。最关键的来了,第20行的barrier这个优化屏障不能阻止CPU对A变量的访问,但是,可能由于这时CPU cache操作非常繁忙,A变量的invalidate message还在其invalidate queue中,因此load A得到了旧的值0。
当然,要修正这个问题非常简单,修改20行代码为smp_rmb即可。一旦执行了smp_rmb,就会mark invalidate queue中的entry,这时候,CPU执行后续的load操作都必须要等到Invalidate queue中的所有缓存的invalidate message(当然,状态必须是marked)被处理并体现到cache中。因此,使用smp_rmb即可以在21行的load A操作中总是获取A的新值“1”从而避免了assert fail。
顺便说一句,在翻译这一节中,上面的程序把我搞惨了。我有一本打印版的perfbook,但是是2014.4.3版本(我计算机中的是2015.1.31号的版本,不过我不喜欢看计算机,喜欢看纸版),其中上面的程序片段中的第20行是smp_mb。如果在20行是smp_mb这样的全功能的memory barrier,整个程序的逻辑是不会错的啊,我怎么想都觉得不对劲,整个周末都在想哪里出问题了,我甚至又回头重新阅读了why memory barrier那一章,仍然觉得程序是对的。最终,在星期一,我决定写一封信给Paul E. McKenney,告诉他我的困惑。在写邮件的时候,我从2015.1.31版本perfbook中copy程序片段的时候才发现,新版本已经修正了,呵呵,虚惊一场。
So what should you do? Your best strategy, if possible, is to use existing primitives that incorporate any needed memory barriers, so that you can simply ignore the rest of this chapter.
Of course, if you are implementing synchronization primitives, you don’t have this luxury. The following discussion of memory ordering and memory barriers is for you.
肿么办?memory barrier的坑很深呐,你真的想要跳下去吗?也许你最好的选择是使用目前的同步原语(包含你需要的memory barrier操作),这样的话,你就可以忽略掉本章剩余的内容了。当然,如果你的工作就是实现这些同步原语,那么生活没有你想像的那么美好(我儿子最近经常使用这句话,^_^),下面关于memory order和memory barrier的讨论都是为您准备的。
14.2.3 Variables Can Have More Than One Value
It is natural to think of a variable as taking on a well-defined sequence of values in a well-defined, global order. Unfortunately, it is time to say “goodbye” to this sort of comforting fiction.
To see this, consider the program fragment shown in Figure 14.4. This code fragment is executed in parallel by several CPUs. Line 1 sets a shared variable to the current CPU’s ID, line 2 initializes several variables from a gettb() function that delivers the value of fine-grained hardware “timebase” counter that is synchronized among all CPUs (not available from all CPU architectures, unfortunately!), and the loop from lines 3-8 records the length of time that the variable retains the value that this CPU assigned to it. Of course, one of the CPUs will “win”, and would thus never exit the loop if not for the check on lines 7-8.
程序员很自然的认为在程序的执行过程中,变量按照一个明确的全局顺序赋一系列明确定义的数值。也许曾经是这样的,但是,现在必须要和美好的过去说byebye了。为了看清这个“残酷”的现实,我们给出一段代码来,如下:
1 state.variable = mycpu;
2 lasttb = oldtb = firsttb = gettb();
3 while (state.variable == mycpu) {
4 lasttb = oldtb;
5 oldtb = gettb();
6 if (lasttb - firsttb > 1000)
7 break;
8 }
这段代码被多个cpu并行执行。第一行代码是将自己的CPU ID赋值给一个全局共享变量,第二行用gettb() 这个函数的返回值来初始化几个局部变量,gettb() 这个函数是干什么的呢?一般而言,多核CPU都有一个全局的HW counter(当然,不是所有的CPU arch都支持,反正ARM是有),这个HW counter是所有CPU Core共享的,因此可以做全局的timeline。gettb() 这个函数就是读取这个counter的函数接口,通过读取该counter,每个CPU上的程序都可以获得当前时刻在该timeline上的投影。3~8行的代码用来记录全局变量state.variable维持mycpu这个值的时间长度(在第一行被赋值,但终究会被其他CPU改写)。当然,最后一个CPU会赢得比赛,并且state.variable一直维持其cpu id的值,这时候,通过7~8行的代码可以让该CPU从无限循环中解脱出来(这时候state.variable == mycpu总是成立)。
Upon exit from the loop, firsttb will hold a timestamp taken shortly after the assignment and lasttb will hold a timestamp taken before the last sampling of the shared variable that still retained the assigned value, or a value equal to firsttb if the shared variable had changed before entry into the loop. This allows us to plot each CPU’s view of the value of state.variable over a 532-nanosecond time period, as shown in Figure 14.5. This data was collected on 1.5GHz POWER5 system with 8 cores, each containing a pair of hardware threads. CPUs 1, 2, 3, and 4 recorded the values, while CPU 0 controlled the test. The timebase counter period was about 5.32ns, sufficiently fine-grained to allow observations of intermediate cache states.
退出循环的时候,根据程序逻辑,我们可以得出下面的结论:在firsttb时刻,CPU看到state.variable这个全局变量保存了本cpu的ID值,在lasttb时刻,state.variable仍然保存本CPU 的ID值,但是,这已经是最后一个感知本CPU id值采样点了,在下一次采样的时候,state.variable将被赋值为其他CPU的ID值,从而退出循环。当然也有可能lasttb等于firsttb,这种场景出现在第一次执行while (state.variable == mycpu)就退出循环的时候。因此,从firsttb时刻到lasttb时刻这段时间就是CPU感知到state.variable的值是自己CPU id的时间,其他时间,state.variable的值就是最后胜出那个CPU id值(当然,真实的硬件上,CPU应该能感知到一些中间值,不过这里做了简化)。根据上面的结论,我们可以画出下面的图:

上面的这幅图片描述了state.variable值的变化情况(最后胜出的是CPU 2)。真实的数据是来自1.5GHz 8核(每核2线程)的POWER5 系统上,CPU 0用来控制测试,CPU 1~4用来收集数据。HW counter的精度是5.23ns,这个精度对于观测中间状态的cache state是足够了。
Each horizontal bar represents the observations of a given CPU over time, with the black regions to the left indicating the time before the corresponding CPU’s first measurement. During the first 5ns, only CPU 3 has an opinion about the value of the variable. During the next 10ns, CPUs 2 and 3 disagree on the value of the variable, but thereafter agree that the value is “2”, which is in fact the final agreed-upon value. However, CPU 1 believes that the value is “1” for almost 300ns, and CPU 4 believes that the value is “4” for almost 500ns.
横轴是时间轴,各种颜色的彩条描述了指定cpu上对state.variable的值的观测情况。最左边的黑色条表示cpu尚未对state.variable变量发起访问的“黑暗”时间,在最初的5ns过程中,只有CPU 3观测到state.variable的值是本cpu id,随后的10ns的时间里,cpu 2和cpu3在state.variable的值的观测上达到一致,都是cpu 2的ID值(由于cpu 2和cpu3的affinity level级别比较高,比较亲近,因此很快达成一致)。虽然,在最后,所有的CPU都认为state.variable的值等于2(即CPU2胜出),不过,在这个时刻,CPU 1和4并没有感知到state.variable的值被CPU2修改。在将近300ns的时间里,CPU 1始终认为state.variable的值等于自己的cpu id,同样的,CPU 4直到500ns的时刻,才意识到state.variable的值等于2,至此,所有的CPU在state.variable的值上达成一致。
We have entered a regime where we must bid a fond farewell to comfortable intuitions about values of variables and the passage of time. This is the regime where memory barriers are needed.
通过上面的分析,我们知道,在对全局变量的值的观测中,在指定的时间点上(例如第200ns时刻),各个cpu的意见并不一致,因此,变量有了多个值。我相信此刻你的内心几乎是崩溃的,但是,骚年们,收拾下心情,跟单纯美好的过去告别,一起迎接“惨淡的人生”,而这里才是memory barrier的用武之地。
14.2.4 What Can You Trust?
You most definitely cannot trust your intuition. What can you trust?
It turns out that there are a few reasonably simple rules that allow you to make good use of memory barriers. This section derives those rules, for those who wish to get to the bottom of the memory-barrier story, at least from the viewpoint of portable code. If you just want to be told what the rules are rather than suffering through the actual derivation, please feel free to skip to Section 14.2.6.
The exact semantics of memory barriers vary wildly from one CPU to another, so portable code must rely only on the least-common-denominator semantics of memory barriers. Fortunately, all CPUs impose the following rules:
1. All accesses by a given CPU will appear to that CPU to have occurred in program order.
2. All CPUs’ accesses to a single variable will be consistent with some global ordering of stores to that variable.
3. Memory barriers will operate in a pair-wise fashion.
4. Operations will be provided from which exclusive locking primitives may be constructed.
Therefore, if you need to use memory barriers in portable code, you can rely on all of these properties.1 Each of these properties is described in the following sections.
当你不能相信自己的直觉推理的时候,你能信任什么呢?
当然,事情也没有那么糟糕,有几个关于如何更好的使用memory barrier的规则,如果你掌握好这几个规则,那么就可以轻松的运用memory barrier这个工具。对于那些不仅注重结果,更在意过程的工程师,这一节就是为你们准备的,本节会推导出这些规则,让你了解memory barrier底层的方方面面(至少可以深入了解可移植代码的细节)。对于那些讨厌繁琐的、痛苦的推导过程,希望直接看到结果的工程师,越过随后的几个小节,直接阅读14.2.6是你最好的选择,那里会直接列出使用memory barrier的规则。
memory barrier的语义在不同CPU上是不同的,因此,想要实现一个可移植的memory barrier的代码需要对形形色色的CPU上的memory barrier进行总结,形成一个能够覆盖所有的CPU memory barrier语义的最小公分母(least-common-denominator)。幸运的是,无论哪一种cpu都遵守下面的规则:
1、从CPU自己的视角看,它自己的memory order是服从program order的
2、从包含所有cpu的sharebility domain的角度看,所有cpu对一个共享变量的访问应该服从若干个全局存储顺序
3、memory barrier需要成对使用
4、memory barrier的操作是构建互斥锁原语的基石
因此,如果你需要直接使用memory barrier在你的代码中,同时,你希望你的代码是可移植的,你必须依赖这些memory barrier的特性,我们会在下面的各个小节中详细描述每一个特性。
14.2.4.1 Self-References Are Ordered
A given CPU will see its own accesses as occurring in “program order”, as if the CPU was executing only one instruction at a time with no reordering or speculation. For older CPUs, this restriction is necessary for binary compatibility, and only secondarily for the sanity of us software types. There have been a few CPUs that violate this rule to a limited extent, but in those cases, the compiler has been responsible for ensuring that ordering is explicitly enforced as needed. Either way, from the programmer’s viewpoint, the CPU sees its own accesses in program order.
某一个具体的CPU看自己的内存访问都是严格服从program order的顺序,就好象CPU在顺序的一次执行一条指令,没有重排指令或者speculation(实在找不到很好的中文描述这个词)。对于比较老的CPU,这个限制主要是为了二进制兼容,其次才是为了软件的正常运行。有几个CPU arch在一定程度上违背了这个规则,在这种情况下,编译器会提供一些手段保证从本cpu上看到memory order符合program order。但是无论如何,从程序员的角度来看,执行代码的CPU看到自己的内存访问顺序是和program order一致的。
14.2.4.2 Single-Variable Memory Consistency
Because current commercially available computer systems provide cache coherence, if a group of CPUs all do concurrent non-atomic stores to a single variable, the series of values seen by all CPUs will be consistent with at least one global ordering. For example, in the series of accesses shown in Figure 14.5, CPU 1 sees the sequence {1,2}, CPU 2 sees the sequence {2}, CPU 3 sees the sequence {3,2}, and CPU 4 sees the sequence {4,2}. This is consistent with the global sequence {3,1,4,2}, but also with all five of the other sequences of these four numbers that end in “2”. Thus, there will be agreement on the sequence of values taken on by a single variable, but there might be ambiguity.
目前市面上能够买到的商业计算机系统都是提供cache coherence功能的,如果多个CPU对一个全局变量并发执行非原子的store操作,那么每个CPU观测这个全局变量的值应该是一个序列,而这个序列应该是符合一个全局的顺序。比如我们上图中的例子:cpu 1看到的序列是{1,2},cpu 2看到的序列是{2},cpu 3看到的序列是{3,2},cpu 4看到的序列是{4,2},所有的cpu看到的顺序都是符合一个全局的顺序{3,1,4,2},当然也不是说每次都是符合这个全局顺序,也可能和其他5个以2结尾的全局顺序保持一致。因此,所有cpu对一个变量值的认知会符合一个全局序列,该序列的最后那个值是最后胜出CPU的赋值,全局序列的其他中间值是不明确的,具体是和当时系统的硬件环境相关(local cache line的状态什么的)。
In contrast, had the CPUs used atomic operations (such as the Linux kernel’s atomic_inc_return() primitive) rather than simple stores of unique values, their observations would be guaranteed to determine a single globally consistent sequence of values. One of the atomic_inc_return() invocations would happen first, and would change the value from 0 to 1, the second from 1 to 2, and so on. The CPUs could compare notes afterwards and come to agreement on the exact ordering of the sequence of atomic_inc_return() invocations. This does not work for the non-atomic stores described earlier because the non-atomic stores do not return any indication of the earlier value, hence the possibility of ambiguity.
做为对比,我们来看看使用原子操作(例如linux kernel中的atomic_inc_return原语)而不是简单的赋值操作的情况。在这种情况下,cpu对共享变量值的观测应该是符合一个确定的、一致的全局序列。我们假设一个全局变量A,初始值是0.某个cpu首先执行atomic_inc_return,将值从0变成1(同时获取旧值0),第二个CPU将值从1变成2(同时获取旧值1),然后依次进行。由于是原子操作,各个cpu是按照一个确定的顺序来执行atomic_inc_return,因此,各个cpu读到的全局变量的值也是一个明确的顺序。上一段描述的简单赋值操作的例子不是这样严格按照一个确定的顺序执行的,因此其一致的全局序列中有些中间值是不明确的。之所以这样是因为非原子的赋值操作不会返回之前旧的值,因此带来了不确定性。
Please note well that this section applies only when all CPUs’ accesses are to one single variable. In this single-variable case, cache coherence guarantees the global ordering, at least assuming that some of the more aggressive compiler optimizations are disabled via the Linux kernel’s ACCESS_ONCE() directive or C++11’s relaxed atomics [Bec11]. In contrast, if there are multiple variables, memory barriers are required for the CPUs to consistently agree on the order for current commercially available computer systems.
需要注意的是:这一节的结论适用的场景是系统中的多个CPU访问一个变量。在这种情况下,系统中有cache coherence的硬件来保证cache一致性,从而保证了那个一致的全局顺序。当然,程序中需要使用类似linux kernel中的ACCESS_ONCE或者C++11中的“relaxed atomics ”(这时什么鬼我也不知道)来阻止编译器对该变量访问的优化。如果是多个CPU访问多个变量的情况呢?这时候,可以使用memory barrier这个强大工具来确保CPUs之间对多个变量访问顺序的认知。
14.2.4.3 Pair-Wise Memory Barriers
Pair-wise memory barriers provide conditional ordering semantics. For example, in the following set of operations, CPU 1’s access to A does not unconditionally precede its access to B from the viewpoint of an external logic analyzer (see Appendix C for examples). However, if CPU 2’s access to B sees the result of CPU 1’s access to B, then CPU 2’s access to A is guaranteed to see the result of CPU 1’s access to A. Although some CPUs’ memory barriers do in fact provide stronger, unconditional ordering guarantees, portable code may rely only on this weaker if-then conditional ordering guarantee.
成对使用的memory barrier提供了有条件的顺序保证,我们用下面的例子来描述什么是有条件的顺序保证:
| CPU1 | CPU2 |
| access(A); | access(B); |
| smp_mb(); | smp_mb(); |
| access(B); | access(A) |
在上面的CPU1上执行的代码中,虽然使用了smp_mb()这个全功能的memory barrier,而且,从CPU1的角度看,对A的访问是先于B执行(即便没有smp_mb也是如此),但是,潜伏在总线上的其他CPU(例如CPU2)是如何看呢?其实从其他observer的角度看,即便使用了smp_mb这个memory barrier,也不能无条件的保证CPU1上对A的访问先于对B的访问。也就是,观察者必须满足一定条件才能保证这个memory访问顺序,这也就是“有条件的顺序保证”的含义。那么具体的条件是什么呢?如果从CPU2的角度观测B,cpu 1对B变量的访问结果已经被CPU2感知到,在这种条件下,cpu 1对A变量的访问结果那么确定会被CPU2观察到。尽管有些CPU的确是提供更强大的memory barrier来保证了无条件的的memory访问顺序的保证,但是可移植代码不能依赖这种强大工具,而只能是使用较弱的if-then类型的有条件的顺序保证,这才是被所有CPU支持的工具。
Of course, accesses must be either loads or stores, and these do have different properties. Table 14.1 shows all possible combinations of loads and stores from a pair of CPUs. Of course, to enforce conditional ordering, there must be a memory barrier between each CPU’s pair of operations.
当然,内存访问包括load和store,这两种操作有不同的特性。下面的表格展示了load和store在一对CPU上的不同组合。为了保证有条件的内存访问顺序,每个CPU上的那一对内存操作必须使用memory barrier进行分隔。

不同的组合共计有16个,这些组合又可以分成3个类别:Portable Combinations(通杀所有CPU)、Semi-Portable Combinations(新CPU可以work,但是不适应在比较旧的那些CPU)和Dubious Combinations(基本是不可移植的),下面都会详细介绍。
14.2.4.4 Pair-Wise Memory Barriers: Portable Combinations
The following pairings from Table 14.1, enumerate all the combinations of memory barrier pairings that portable software may depend on.
上面的表格枚举了所有的成对使用memory barrier的场景,这些是可移植代码必须要考虑的。
Pairing 1. In this pairing, one CPU executes a pair of loads separated by a memory barrier, while a second CPU executes a pair of stores also separated by a memory barrier, as follows (both A and B are initially equal to zero)
首先看看表格中的Pairing 1。CPUs执行的代码如下表所示(A和B的初值都是0):
| CPU1 | CPU2 |
| A = 1; | Y = B; |
| smp_mb(); | smp_mb(); |
| B = 1; | X = A; |
CPU2执行一对load操作,中间间隔了一个memory barrier的操作。CPU1执行一对store操作,同样的,中间间隔了一个memory barrier的操作。
After both CPUs have completed executing these code sequences, if Y==1, then we must also have X==1. In this case, the fact that Y==1 means that CPU 2’s load prior to its memory barrier has seen the store following CPU 1’s memory barrier. Due to the pairwise nature of memory barriers, CPU 2’s load following its memory barrier must therefore see the store that precedes CPU 1’s memory barrier, so that X==1. On the other hand, if Y==0, the memory-barrier condition does not hold, and so in this case, X could be either 0 or 1.
在两个CPU都执行完上面的代码之后,如果Y等于1,那么我们可以断定X也等于1。在这个执行场景中,Y等于1也就是意味着在CPU2在执行Y = B这行代码的时候(该代码在memory barrier之前),已经观察到B等于1这个事件(也就是说CPU1对B的store操作被CPU2感知到了,注意:B=1的代码在memory barrier之后)。OK,前面描述的都是后续推论的条件,也就是说,在上述条件成立的前提下,我们可以作出如下的推论:CPU2上的memory barrier之后的,对A的load操作,一定可以感知到CPU1上memory barrier之前的内存访问(即给A赋值1这个操作)。
另一方面,如果Y等于0,那么memory barrier的条件不存在(即CPU2尚未在自己执行的memory barrier代码之前观察到CPU2上memory barrier之后的对B的load操作),在这种情况下,X可能等于0或者1。
Pairing 2. In this pairing, each CPU executes a load followed by a memory barrier followed by a store, as follows (both A and B are initially equal to zero):
我们继续来看看表格中的Pairing 2。CPUs执行的代码如下表所示(A和B的初值都是0):
| CPU1 | CPU2 |
| X = A; | Y = B; |
| smp_mb(); | smp_mb(); |
| B = 1; | A = 1; |
CPU1首先执行load操作,然后执行一个store操作,load和store之间有一个memory barrier的操作。CPU2执行的动作和CPU1一样,也是load、memory barrier,然后是store。
After both CPUs have completed executing these code sequences, if X==1, then we must also have Y==0. In this case, the fact that X==1 means that CPU 1’s load prior to its memory barrier has seen the store following CPU 2’s memory barrier. Due to the pairwise nature of memory barriers, CPU 1’s store following its memory barrier must therefore see the results of CPU 2’s load preceding its memory barrier, so that Y==0. On the other hand, if X==0, the memory-barrier condition does not hold, and so in this case, Y could be either 0 or 1. The two CPUs’ code sequences are symmetric, so if Y==1 after both CPUs have finished executing these code sequences, then we must have X==0.
在两个CPU都执行完上面的代码之后,如果X等于1,那么我们一定可以得到Y等于0。在这个例子中,X等于1意味着CPU1在memory barrier之前已经观察到了CPU2上的memory barrier之后的对A的store操作,根据成对使用的memory barrier的特性,如果CPU1在执行memory barrier之前的X=A操作的时候观察到了CPU2上memory barrier之后的A=1的赋值操作,那么也就意味着CPU2上memory barrier之前的Y=B操作在CPU1上的B=1赋值操作(memory barrier之后)之前完成,因此Y等于0。另一方面,如果X等于0,那么memory barrier的条件不存在,在这种情况下,Y的值可能是0,也可能是1。由于代码在两个CPU上是对称的,因此,在两个CPU都执行完上面的代码之后,如果Y等于1,那么我们一定可以得到X等于0的结论。
Pairing 3. In this pairing, one CPU executes a load followed by a memory barrier followed by a store, while the other CPU executes a pair of stores separated by a memory barrier, as follows (both A and B are initially equal to zero):
我们继续来看看表格中的Pairing 3。CPUs执行的代码如下表所示(A和B的初值都是0):
| CPU1 | CPU2 |
| X = A; | B = 2; |
| smp_mb(); | smp_mb(); |
| B = 1; | A = 1; |
CPU1首先执行load操作,然后执行一个store操作,load和store之间有一个memory barrier的操作。CPU2执行的动作是store、memory barrier,然后是store。
After both CPUs have completed executing these code sequences, if X==1, then we must also have B==1. In this case, the fact that X==1 means that CPU 1’s load prior to its memory barrier has seen the store following CPU 2’s memory barrier. Due to the pairwise nature of memory barriers, CPU 1’s store following its memory barrier must therefore see the results of CPU 2’s store preceding its memory barrier. This means that CPU 1’s store to B will overwrite CPU 2’s store to B, resulting in B==1. On the other hand, if X==0, the memory-barrier condition does not hold, and so in this case, B could be either 1 or 2.
在两个CPU都执行完上面的代码之后,如果X等于1,那么我们一定可以得到B等于1。在这个例子中,X等于1意味着CPU1在memory barrier之前已经观察到了CPU2上的memory barrier之后的对A的store操作,根据成对使用的memory barrier的特性,如果CPU1在执行memory barrier之前的X=A操作的时候观察到了CPU2上memory barrier之后的A=1的赋值操作,那么也就意味着CPU2上memory barrier之前的B=2操作在CPU1上的B=1赋值操作(memory barrier之后)之前完成,因此CPU1上的赋值操作会覆盖CPU2上的对B的赋值。
另一方面,如果X等于0,那么memory barrier的条件不存在,在这种情况下,B的值可能是1,也可能是2。
14.2.4.5 Pair-Wise Memory Barriers: Semi-Portable Combinations
The following pairings from Table 14.1 can be used on modern hardware, but might fail on some systems that were produced in the 1900s. However, these can safely be used on all mainstream hardware introduced since the year 2000. So if you think that memory barriers are difficult to deal with, please keep in mind that they used to be a lot harder on some systems!
本节要描述的组合能够使用在现代的CPU上,不过对于一些20世纪的“老家伙”就有可能产生问题(这也是我们为什么成它为Semi-Portable的原因,毕竟不能应用在所有的处理器上)。不过,别担心,对于2000之后的主流的计算机系统,本节的memory barrier对可以放心使用。如果你觉得memory barrier很难搞,其实memory barrier在某些系统中曾经更加难搞,想想过去,骚年,还是勇敢面对吧。
Ears to Mouths. Since the stores cannot see the results of the loads (again, ignoring MMIO registers for the moment), it is not always possible to determine whether the memory-barrier condition has been met. However, 21st-century hardware would guarantee that at least one of the loads saw the value stored by the corresponding store (or some later value for that same variable).
对于Semi-Portable 的memory barrier对,我们先看看表格中的Ears to Mouths。CPUs执行的代码如下表所示(A和B的初值都是0):
| CPU1 | CPU2 |
| A = 1; | B = 1; |
| smp_mb(); | smp_mb(); |
| X = B; | Y = A; |
CPU1首先执行store操作,然后执行load操作,load和store之间有一个memory barrier的操作。CPU2执行的动作和CPU1类似,具体的操作是store、memory barrier,然后是load。在继续前行之前,我们先思考这样的问题?为何这个组合叫做Ears to Mouths呢?正常的顺序是Mouths to Ears,嘴说然后耳朵听,这是一个顺理成章的过程。但是这里是Ears to Mouths,耳朵能给嘴巴传递什么信息呢?当然不能,就象store操作不能感知load操作的结果一样。在我们这个场景中,无论是cpu1还是cpu2都是先执行store操作,因此无法感知对端的load操作(在这一刻,请忽略MMIO)。我们知道,一对memory barrier的操作并不能提供无条件的memory order,都是在某些条件成立的情况下,才能保证其他的memory的操作顺序。在Ears to Mouths的case中,我们无法判定memory barrier的条件是否成立,因此,无法保证什任何的memory访问顺序。不过,在21世纪的硬件平台上,至少可以保证两个load操作中的一个可以观察到对端CPU的store操作或者是随后对该变量的赋值操作(或者说,X和Y不可能同时等于A和B的初值0,必然有一个能感知到对端CPU的store操作,有兴趣的话可以自己分析一下)。
Stores “Pass in the Night”. In the following example, after both CPUs have finished executing their code sequences, it is quite tempting to conclude that the result {A==1,B==2} cannot happen.
perfbook的作者对不同场景的memory barrier组合的起名非常有意思,这也给枯燥的翻译带来了乐趣。我们常常形容两个人不来电,就像是ships that pass in the night(黑夜里交错而过的船,感知不到对方的轨迹)。两个CPU上执行的store操作会不会互生情愫,还是pass in the night呢?呵呵~~~
OK,还是回到表格中的Stores “Pass in the Night”这个条目好了,CPUs执行的代码如下表所示(A和B的初值并不重要了):
| CPU1 | CPU2 |
| A = 1; | B = 2; |
| smp_mb(); | smp_mb(); |
| B = 1; | A = 2; |
CPU1和CPU2都是执行两个store操作,两个store之间有一个memory barrier的操作。如果CPU1先于CPU2执行完代码,那么最后变量的值应该是{A==2,B==2},如果CPU2先于CPU1执行完代码,那么最后变量的值应该是{A==1,B==1},如果并发执行,那么可能A和B两个变量都是第二个赋值覆盖了第一个赋值的结果,因此,最后变量的值应该是{A==2,B==1},但是无论如何,在两个CPU都执行完上面的代码之后,{A==1,B==2} 这种情况不可能发生。
Unfortunately, although this conclusion is correct on 21st-century systems, it does not necessarily hold on all antique 20th-century systems. Suppose that the cache line containing A is initially owned by CPU 2, and that containing B is initially owned by CPU 1. Then, in systems that have invalidation queues and store buffers, it is possible for the first assignments to “pass in the night”, so that the second assignments actually happen first. This strange effect is explained in Appendix C.
This same effect can happen in any memory-barrier pairing where each CPU’s memory barrier is preceded by a store, including the “ears to mouths” pairing.
However, 21st-century hardware does accommodate these ordering intuitions, and do permit this combination to be used safely.
很不幸,这个推论在大部分21世纪的计算机系统中都是正确的,不过对于20世纪的古董系统,这个推论就不正确了,我们来一起看看{A==1,B==2}这种执行结果是如何发生的 。我们假设CPU 2的local cache中有A的值,而B在CPU 1的cacheline中。对于有Invalidate queue和store buffer的系统,CPU1的执行序列是这样的(CPU2是类似的,就不再描述了):
1、对于A的store操作引发了CPU1发起invalidate message,当然,CPU不会停下它的脚步,将A的新值“1”放入store buffer,它就飘然而去
2、smp_mb使得CPU对store buffer中的entry进行标注(当然也对Invalidate Queue进行标注,不过和本场景无关),store A的操作变成marked状态
3、对B的赋值操作也进入store buffer,但是状态是unmarked
4、由于Invalidate Queue的存在,CPU1很快收集了对invalidate message的response,因此,store buffer的操作被flush进入cache。
综合考虑CPU1和CPU2上的执行序列,你就会发现,第一个赋值(对于CPU1而言是A = 1,对于CPU2而言是B = 2)其实是pass in the night,静悄悄的走过,没有带走一片云彩。而第二个赋值(对于CPU1而言是B = 1,对于CPU2而言是A = 2)则会后发先至,从而导致其执行结果被第一个赋值操作覆盖。
其实,只要符合下面的使用模式,上面描述的操作顺序(第二个store的结果被第一个store覆盖)都是有可能发生的:
| CPU1 | CPU2 |
| store | store |
| smp_mb(); | smp_mb(); |
| xxxx | xxxx |
需要注意的是:“ears to mouths”也符合上述模式,因此也会存在上面描述的操作顺序。
不过,对于21世纪的硬件系统而言,硬件工程师已经帮忙解决了上面的问题,因此,软件工程师可以安全的使用Stores “Pass in the Night”。
14.2.4.6 Pair-Wise Memory Barriers: Dubious Combinations
In the following combinations from Table 14.1, the memory barriers have very limited use in portable code, even on 21st-century hardware. However, “limited use” is different than “no use”, so let’s see what can be done! Avid readers will want to write toy programs that rely on each of these combinations in order to fully understand how this works.
本节介绍的这些memory barrier组合,如果想应用在可移植的代码中那么会有些困难,因为即便是在21世纪的那些新的CPU硬件平台上,这些memory barrier组合也不能保证都OK,因此,其应用场景非常受限。当然“应用场景非常受限”并非一无是处,因此,让我们一起看看它们能干什么?热心的读者也可以考虑动手写一些示例程序来加上对这些memory barrier组合的理解。
Ears to Ears. Since loads do not change the state of memory (ignoring MMIO registers for the moment), it is not possible for one of the loads to see the results of the other load. However, if we know that CPU 2’s load from B returned a newer value than CPU 1’s load from B, the we also know that CPU 2’s load from A returned either the same value as CPU 1’s load from A or some later value.
先分析Ears to Ears这种组合情况。由于load操作不能改变memory的状态(这一刻,再次忽略MMIO),因此,一个CPU上的load是无法感知到另外一侧CPU的load操作的。不过,如果CPU2上的load B操作返回的值比CPU 1上的load B返回的值新的话(即CPU2上load B晚于CPU1的load B执行),那么可以推断CPU2的load A返回的值要么和CPU1上的load A返回值一样新,要么加载更新的值。
Mouth to Mouth, Ear to Ear. One of the variables is only loaded from, and the other is only stored to. Because (once again, ignoring MMIO registers) it is not possible for one load to see the results of the other, it is not possible to detect the conditional ordering provided by the memory barrier.
However, it is possible to determine which store happened last, but this requires an additional load from B. If this additional load from B is executed after both CPUs 1 and 2 complete, and if it turns out that CPU 2’s store to B happened last, then we know that CPU 2’s load from A returned either the same value as CPU 1’s load from A or some later value.
Mouth to Mouth, Ear to Ear这个组合的特点是一个变量只是执行store操作,而另外一个变量只是进行load操作。执行序列如下:
| CPU1 | CPU2 |
| load A | store B |
| smp_mb(); | smp_mb(); |
| store B | load A |
在这种情况下(又一次忽略MMIO,咦,为什么说“又”呢),load B无法感知对端CPU的load B,我们知道,memory barrier是在某些条件成立的情况下,才保证某些操作顺序,这里memory barrier的条件不成立,因此也就无从保证顺序了。
不过,执行一个额外的load B的操作,我们还是有可能知道store的操作顺序(哪一个最后发生)。在CPU1和CPU2执行完毕上述代码之后,我们再来一个load B,如果是CPU2上的store B最后发生,那么我们作出这样的推论:CPU2的load A返回的值要么和CPU1上的load A返回值一样新,要么加载更新的值(用比较好理解的话是CPU2上的load A后发生,有可能感知更新的值)。
Only One Store. Because there is only one store, only one of the variables permits one CPU to see the results of the other CPU’s access. Therefore, there is no way to detect the conditional ordering provided by the memory barriers.
At least not straightforwardly. But suppose that in combination 1 from Table 14.1, CPU 1’s load from A returns the value that CPU 2 stored to A. Then we know that CPU 1’s load from B returned either the same value as CPU 2’s load from A or some later value.
Only One Store这个组合说明在CPU1和CPU2执行的4个memory操作中只有一个是store。由于只有一个store,因此变量A和变量B中必定有一个是两个load操作,一个是load store操作。也就是说只有一个变量的store操作可以被另外的CPU上的load操作观察到。假设执行序列如下:
| CPU1 | CPU2 |
| load A | load B |
| smp_mb(); | smp_mb(); |
| load B | store A |
如果在CPU1上运行的load A感知到了在CPU2上对A的赋值,那么,CPU1上的load B必然能观察到和CPU2上load B一样的值或者更新的值。
14.2.4.7 Semantics Sufficient to Implement Locking
Suppose we have an exclusive lock (spinlock_t in the Linux kernel, pthread_mutex_t in pthreads code) that guards a number of variables (in other words, these variables are not accessed except from the lock’s critical sections). The following properties must then hold true:
假设我们现在使用互斥锁(例如linux kernel中的spinlock_t或者线程库中的pthread_mutex_t)来保护几个变量(换句话说,这些变量只能在锁保护的临界区内被访问),那么下面这些结论是成立的:
1. A given CPU or thread must see all of its own loads and stores as if they had occurred in program order. 特定的CPU或者线程在观察自己的内存访问情况的时候,其观察到的顺序和program order一致。
2. The lock acquisitions and releases must appear to have executed in a single global order. 从全局来看,持有锁和释放锁的操作顺序应该是一个全局的顺序(所有的CPU观察到的都是那个全局的操作顺序)。
3. Suppose a given variable has not yet been stored to in a critical section that is currently executing. Then any load from a given variable performed in that critical section must see the last store to that variable from the last previous critical section that stored to it. 我们假设全局的临界区的操作顺序是C0,C1,C2……(具体在哪一个CPU我们就不纠结了),我们假设在C2临界区中(临界区代码正在执行),但是某一个受保护的变量A还没有执行store的操作。那么我们可以得出这样的结论:在临界区C2中(尚未执行对A的store),任何对A变量的load操作都是能够观察到C1临界区中最后一个store的结果。
The difference between the last two properties is a bit subtle: the second requires that the lock acquisitions and releases occur in a well-defined order, while the third requires that the critical sections not “bleed out” far enough to cause difficulties for other critical section.
Why are these properties necessary?
Suppose the first property did not hold. Then the assertion in the following code might well fail!
后面两个锁的特性有一些微妙的差异,第二个特性是要求锁的持有和释放要有一个确定的全局顺序,而第三个特性需要每个临界区之间有清楚的界线。假设全局的临界区的操作顺序是C0,C1,C2……,那么C0中对A变量的store操作,必须在C1临界区的开始的load A指令中体现出来。
为什么规定锁必须要拥有这些特性呢?如果第一条特性不能满足的话,那么下面的代码将会发生assert fail:
a = 1;
b = 1 + a;
assert(b == 2);
如果第二行代码不能感知第一行代码中对a的store操作,那么b = 1 + a就无法正确的计算b的值从而导致程序逻辑错误。
Suppose that the second property did not hold. Then the following code might leak memory!
如果第二条特性不能满足的话,那么下面的代码将会发生内存泄露:
spin_lock(&mylock);
if (p == NULL)
p = kmalloc(sizeof(*p), GFP_KERNEL);
spin_unlock(&mylock);
上面的代码逻辑中,我们知道,只有第一个临界区可以看到P==NULL,从而分配内存,如果所有的CPU看到的都是一个确定的,依次执行的临界区序列,那么毫无疑问,这里第一个执行的临界区是确定的。如果不同的CPU看到的是不同的临界区执行序列,那么如何确定那个第一个执行的临界区呢?如果两个thread都认为自己是第一个执行的临界区,实际上p执行的memory会分配两次,从而导致了内存泄漏。
Suppose that the third property did not hold. Then the counter shown in the following code might well count backwards. This third property is crucial, as it cannot be strictly with pairwise memory barriers.
如果第三条特性不能满足的话,那么下面的代码中累加的ctr变量将会出现数值错误:
spin_lock(&mylock);
ctr = ctr + 1;
spin_unlock(&mylock);
假设初值是0,那么8个cpu跑这段代码,最终ctr = ctr + 1;被执行了8次,因此代码执行完毕,ctr的值应该是8。在第一条和第二天特性都满足的情况下,所有CPU都认为系统中存在一个确定的临界区执行顺序,也就是说ctr = ctr + 1;被顺序执行。假设临界区C0~C7被CPU0~CPU7依次执行,那么C0执行完毕,CPU0认为ctr的值是1,这个值必须在C1临界区开始的时候,被CPU1观察到。如果观察不到,那么C1执行完毕,本来应该是2的值,现在计算得到1,产生了错误。
If you are convinced that these rules are necessary, let’s look at how they interact with a typical locking implementation.
上面的这三条特性可以理解对互斥锁这种机制的需求,如果你确定已经理解了这些需求,并且认为它们是必要的,我们可以继续来看锁的实现。
14.2.5 Review of Locking Implementations
Naive pseudocode for simple lock and unlock operations are shown below. Note that the atomic_xchg() primitive implies a memory barrier both before and after the atomic exchange operation, and that the implicit barrier after the atomic exchange operation eliminates the need for an explicit memory barrier in spin_lock(). Note also that, despite the names, atomic_read() and atomic_set() do not execute any atomic instructions, instead, it merely executes a simple load and store, respectively. This pseudocode follows a number of Linux implementations for the unlock operation, which is a simple non-atomic store following a memory barrier. These minimal implementations must possess all the locking properties laid out in Section 14.2.4.
一个比较朴素的spin lock实现版本如下:
1 void spin_lock(spinlock_t *lck)
2 {
3 while (atomic_xchg(&lck->a, 1) != 0)
4 while (atomic_read(&lck->a) != 0)
5 continue;
6 }
7
8 void spin_unlock(spinlock_t lck)
9 {
10 smp_mb();
11 atomic_set(&lck->a, 0);
12 }
我们首先看看spin_lock的代码:在进入和退出atomic_xchg这个原语的地方实际上都隐含了memory barrier的操作,这个隐含的memory barrier操作可以让spin_lock不需要显式的调用memory barrier的操作。需要注意的是,虽然名字中有atomic,不过atomic_read() 和atomic_set() 都没有执行特定的CPU级别的原子汇编指令(对于ARM处理器,曾经是SWP指令,现在是load store exclusive指令),仅仅是简单的load和store操作。linux中的许多锁的释放操作都是遵循了本伪代码的逻辑:即先是一个memory barrier操作,然后是一个简单的,非原子的store操作。不管哪个锁的实现代码,都必须符合14.2.4小节给出的三点软件需求。
The spin_lock() primitive cannot proceed until the preceding spin_unlock() primitive completes. If CPU 1 is releasing a lock that CPU 2 is attempting to acquire, the sequence of operations might be as follows:
直到其他CPU的thread调用spin_unlock,完成对spin lock的释放动作,本CPU的spin_lock才能进入临界区,继续执行后续代码。不过如果CPU1在释放锁的时候CPU2又在试图获取锁,这时会怎么样呢?我们一起来看看下面的操作序列:
| CPU1 | CPU2 |
|
(上一个临界区的结束点) smp_mb(); lck->a=0; |
atomic_xchg(&lck->a, 1)->1----(a) |
In this particular case, pairwise memory barriers suffice to keep the two critical sections in place. CPU 2’s atomic_xchg(&lck->a, 1) has seen CPU 1’s lck->a=0, so therefore everything in CPU 2’s following critical section must see everything that CPU 1’s preceding critical section did. Conversely, CPU 1’s critical section cannot see anything that CPU 2’s critical section will do.
在这个场景中,一对memory barrier操作足够让两个临界区按照正确的顺序执行。我们重点关注CPU2上的执行。在step(a)上,atomic_xchg(&lck->a, 1)返回1,说明CPU1还没有释放锁,step (b)和step(c)中,CPU2不断的load lck->a,但是直到step (d)才发现CPU1释放了锁。于是CPU2赶紧调用atomic_xchg(&lck->a, 1)去抢锁资源(step (f)),如果返回1,说明抢失败了,重新回到step (a),如果返回0,说明顺利抢到锁,可以进入临界区。为了更好的理解memory barrier的操作,我们简化一下上面的表格:
| CPU1 | CPU2 |
| 临界区X | 感知到CPU1 将lck->a 的值修改为0 |
| smp_mb(); | smp_mb(); |
| store lck->a with 0 | 临界区X+1 |
这个表格是否熟悉多了吧,呵呵~~~。成对使用的memory barrier可以有条件的memory order。对应这个场景,在CPU2感知到CPU1 将lck->a 的值修改为0的条件下,临界区X+1可以观察到临界区X的memory操作,即满足了14.2.4小节的特性3。
14.2.6 A Few Simple Rules
Probably the easiest way to understand memory barriers is to understand a few simple rules:
也许理解下面几个简单的规则是通往掌握memory barrier最简单的道路了:
1. Each CPU sees its own accesses in order. 每个CPU看自己的内存访问序列都是遵循program order
2. If a single shared variable is loaded and stored by multiple CPUs, then the series of values seen by a given CPU will be consistent with the series seen by the other CPUs, and there will be at least one sequence consisting of all values stored to that variable with which each CPUs series will be consistent.
如果一个共享变量被多个CPU进行读写的操作,那么某个特定的CPU观察到的该变量的值序列应该是和其他CPU看到的值序列吻合的。当然,这里的“吻合”并不是说每个CPU看到的变量值序列是完全一致的,序列中的每个成员都相同,实际上,有可能不同CPU看到的变量值序列的长度都不一样。这里的“吻合”是指存在一个包括所有写入变量值的序列(我们称之全局序列),每个cpu观察到的变量值序列都是和这个全局序列吻合的。例如:全局序列是{a, b, c, d, e},那么可能cpu0看到的是{a, d, e},cpu3看到的是{a, b, c, e},但是无论是cpu0还是cpu3,其观察到的变量值序列都是和全局序列吻合。
3. If one CPU does ordered stores to variables A and B, and if a second CPU does ordered loads from B and A, then if the second CPU’s load from B gives the value stored by the first CPU, then the second CPU’s load from A must give the value stored by the first CPU.
如果在CPU1上顺序的执行了对变量A和变量B的写入操作(注意:由于CPU会out-of-order execution,因此如果program order是store A然后sotreB并不能保证对变量A和变量B的顺序写入,必须在store A和sotreB之间插入smp_wmb或者更强大的smp_mb),并且在CPU2上顺序的执行了对变量B和变量A的读出操作(注意:由于CPU会out-of-order execution,因此如果program order是load B然后load A并不能保证对变量B和变量A的顺序读出,必须在load B和load A之间插入smp_rmb或者更强大的smp_mb),那么,在CPU2上的load B能够感知到CPU1的store B的操作结果的条件下,CPU2的load A一定可以感知到CPU1上的store A的执行结果。
4. If one CPU does a load from A ordered before a store to B, and if a second CPU does a load from B ordered before a store from A, and if the second CPU’s load from B gives the value stored by the first CPU, then the first CPU’s load from A must not give the value stored by the second CPU.
假设CPU1执行的是load A---->smp_mb---->store B,CPU2执行的是load B---->smp_mb---->store A,在CPU2的load B能够观察到CPU1对B的写入值的条件下,CPU1的load A操作不可能观察到CPU2对A的store操作结果。
5. If one CPU does a load from A ordered before a store to B, and if a second CPU does a store to B ordered before a store to A, and if the first CPU’s load from A gives the value stored by the second CPU, then the first CPU’s store to B must happen after the second CPU’s store to B, hence the value stored by the first CPU persists.
假设CPU1执行的是load A---->smp_mb---->store B,CPU2执行的是store B---->smp_mb---->store A,在CPU1的load A能够观察到CPU2对A的写入值的条件下,CPU1的store B操作必定发生在CPU2的store B之后,因此覆盖CPU2对B的写入值(即CPU1的store B胜出)。
参考文献:
1、英文的原文来自perfbook-1c.2015.01.31a.pdf
2、翻译的过程,参考了《深入理解并行编程V2.0.pdf》,多谢谢宝友/鲁阳/陈渝的辛苦劳动。他们的翻译忠于原著,我的翻译都是满嘴跑舌头,^_^。
原创翻译文章,转发请注明出处。蜗窝科技
标签: 内存屏障
评论:
2017-09-08 16:31
hello linuxer,
上面的分析个人觉得是有问题的,内存屏障保证了cpu0不可能绕过A先对B赋值。个人认为这个问题的原因是20行的优化屏障不能阻止cpu2的乱序执行。假设CPU2 load A在 load C之前执行(此时获取了地址的数据,但指令还没有提交),获取了一个老的值0, 此后极短时间之内,cpu0完成了对A与B的更新,cpu1完成了对C的更新,这时CPU2 load C获取了C的最新值,进而完成提交,接下来load A完成提交,指令执行完毕,但A是旧值0
2016-11-01 14:58
2016-10-19 19:26
如果是多线程共同访问某一变量时,可以用内核中的一些同步原语,如spin_lock, mutex等保证共享变量不被乱序执行,按照自己的意图去执行。
但是往往有个场景,比如spin_lock 和spin_unlock等同步原语之间圈起来的不是一个变量,而是多个变量时,这种场景下,多个线程间对这个多个共享变量的读写有可能就会造成乱序,不按照自己设想的顺序去执行。
所以smp_mb这些规避的乱序执行的原语,还是大有用武之地。就是说不要以为用了内核态和用户态一些同步API(信号量,锁等),就不用考虑规避乱序执行的CPU行为了。
是不是这样理解的,谢谢指点 @Linuxer
2016-10-20 09:22
所幸的是并非每一个内核工程师都需要理解这些东西,除非你是内核同步机制的维护者,实际上,做为普通的驱动工程师,只要理解如何使用内核同步的原语就OK了,内核同步的原语可以保证只有一个线程进入临界区,这样也就不存在多个线程访问临界区的共享变量了,没有多个线程访问共享变量的场景,也就没有了乱序访问的隐忧了。换一句话说:一旦使用了标准的内核同步原语,那么不考虑cpu的乱序行为了,你看到的将是一个顺序执行的世界。
2016-10-20 13:03
不过要会灵活使用smp_mb的话,还真得在代码中某些场合下要考虑到CPU的乱序执行行为来。现在CPU基本上全是SMP架构,多核时代。
列举内核代码树中使用到smp_mb规避乱序执行的场合:
1:经典的Documention目录下,一个线程cond-> wake, 另一个线程prepare_to_wait-> if(cond) -> schedule;
2:drivers/usb/gadget/f_mtp.c 里面多个线程流会同时访问某个共享变量
3:fs/super.c, ext3/4.c 文件系统里面也很多。之前谷歌用ext4取代yaffs2,估计也是因为yaffs文件系统多线程并发情况下支持的不太好。
我说的意思是多核内核态编程,smp_mb的使用频率也应该不低吧。不是因为用了spin_lock,mutex这些同步原语,就可以把它忘了。你说呢 @Linuxer
2016-10-20 15:55
实际上,我永远都持有这样的一个观点:越简单越好,越简单越美。如果软件工程师需要了解过多底层CPU的细节,那么我认为这个设计是失败的,对于memory order问题,其实最好的设计就是软件工程师不需要了解cpu的乱序行为,但是由于性能问题,计算机硬件和软件接口才增加了约束memory order的指令。换句话说,CPU提供mb指令本身就是向性能妥协而已,一点也不优雅。
同样的,对于内核而言,memory barrier模块最好能够被内核同步模块封装起来,不被其他模块看到。做为内核工程师,我们也想生活轻松一些啊,干嘛要搞清楚memory order和memory barrier啊,有空喝喝茶,看看电影多好啊。可是,使用内核同步原语可能会造成性能问题,如果你负责的内核模块对性能非常的敏感,那么你可能是需要越过内核同步模块,直接使用memory barrier模块的接口。所以,是否选择忘记memory barrier,就看你想成为什么样的内核工程师了,哈哈~~~
2015-12-25 17:38
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2020-06-19 16:58
---》这里的barrier是个啥?一个读屏障加在这里可以保证后面读取的是最新的,那这个barrier既然起不到作用,放这里干嘛?