
Perf book 9.3章节翻译(上)
作者:linuxer 发布于:2016-2-18 19:07 分类:内核同步机制
9.3 Read-Copy Update (RCU)
This section covers RCU from a number of different perspectives. Section 9.3.1 provides the classic introduction to RCU, Section 9.3.2 covers fundamental RCU concepts, Section 9.3.3 introduces some common uses of RCU, Section 9.3.4 presents the Linuxkernel API, Section 9.3.5 covers a sequence of “toy” implementations of user-level RCU, and finally Section 9.3.6 provides some RCU exercises.
这一节从几个不同的角度来描述RCU。9.3.1小节提供了RCU的一些简单的介绍,9.3.2小节给出了几个基础的RCU概念,9.3.3小节介绍了一些常用的RCU使用场景,9.3.4小节讲述了linux kernel中RCU的接口API,9.3.5小节给出一系列简陋的user-level的RCU实现方法,最后一节9.3.6提供了若干RCU的练习。
9.3.1 Introduction to RCU
Suppose that you are writing a parallel real-time program that needs to access data that is subject to gradual change, perhaps due to changes in temperature, humidity, and barometric pressure. The real-time response constraints on this program are so severe that it is not permissible to spin or block, thus ruling out locking, nor is it permissible to use a retry loop, thus ruling out sequence locks. Fortunately, the temperature and pressure are normally controlled, so that a default hard-coded set of data is usually sufficient.
我们首先假设一个场景:你在撰写一个并发的实时程序,该程序需要访问一个在缓慢变化的共享数据。而这个缓慢变化数据可能是反应温度、湿度或者气压的变化。由于有real time的需求,因此该程序对响应时间要求非常严格,这样任何使用spin lock或者block当前进程的方法都不行。使用锁的方法出局,当然retry loop也不行,这也就导致sequence lock也出局了。幸运的是温度和压力的变化基本不变,因此使用缺省的hard-coded的数据也是OK的。
However, the temperature, humidity, and pressure occasionally deviate too far from the defaults, and in such situations it is necessary to provide data that replaces the defaults. Because the temperature, humidity, and pressure change gradually, providing the updated values is not a matter of urgency, though it must happen within a few minutes. The program is to use a global pointer imaginatively named gptr that is normally NULL, which indicates that the default values are to be used. Otherwise, gptr points to a structure providing values imaginatively named a, b, and c that are to be used in the real-time calculations.
尽管大部分时间温度、湿度和气压都和缺省值保持一致,不过,偶尔这些值也会偏离缺省值。在这种情况下,就有必要使用当前值来代替缺省值。由于变化缓慢,因此使用新的当前值来替代缺省值并不着急,没有realtime的需求,基本上在几分钟内完成更新就可以了。程序使用一个全局指针变量gptr来访问温度、湿度和气压的数据,如果等于NULL就意味着使用缺省值,如果gptr指向一个成员分别是a、b、c的数据结构(应该分别表示温度、湿度和大气压力的值),那么说明缺省值失效,需要使用当前值。
How can we safely provide updated values when needed without impeding real-time readers?
A classic approach is shown in Figure 9.10. The first row shows the default state, with gptr equal to NULL. In the second row, we have allocated a structure which is uninitialized, as indicated by the question marks. In the third row, we have initialized the structure. Next, we assign gptr to reference this new element. On modern general purpose systems, this assignment is atomic in the sense that concurrent readers will see either a NULL pointer or a pointer to the new structure p, but not some mash-up containing bits from both values. Each reader is therefore guaranteed to either get the default value of NULL or to get the newly installed non-default values, but either way each reader will see a consistent result. Even better, readers need not use any expensive synchronization primitives, so this approach is quite suitable for real-time use.
面对这也的场景,我们在具体的程序设计的时候,如何做到安全的进行数据的更新而又不影响reader一侧的实时性呢?
一个经典的方法如下:
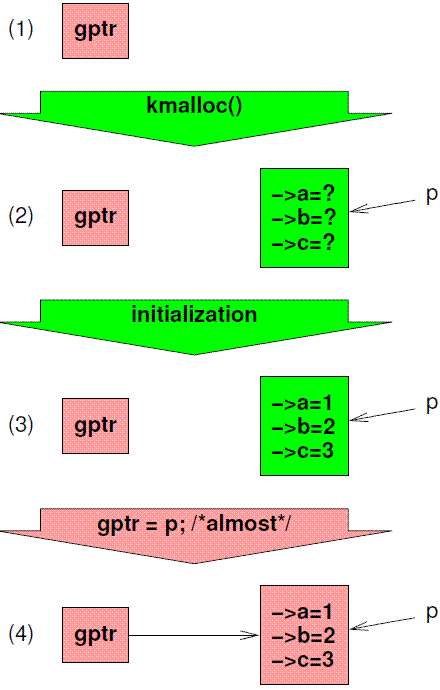
(1)展示了缺省状态,gptr等于NULL。(2)通过kmalloc分配了一个未初始化的数据结构,成员分别是a、b、c,由于没有初始化,我们用?来表示其值。(3)给各个成员赋初始值。(4)让gptr指向这个新的数据。在现代的通用的计算机系统中,步骤(4)中的赋值是原子性的,也就是说并发的reader要么看到gptr的值是NULL,要么看到的gptr指向新分配的那个数据块p,而不是把两个混杂在一起。因此,每一个reader线程通过gptr来访问共享数据,要么是发现gptr是NULL,从而获取缺省数据,要么是发现gptr不是NULL,从而访问了新分配的那个数据块p的内容。不管哪一个状况,对于一个reader thread而言,其结果是一致性的。更令人兴奋的是:reader thread不需要使用任何开销大的内核同步原语,因此,这样的方法对于实时应用而言非常的适合。
But sooner or later, it will be necessary to remove data that is being referenced by concurrent readers. Let us move to a more complex example where we are removing an element from a linked list, as shown in Figure 9.11. This list initially contains elements A, B, and C, and we need to remove element B. First, we use list_del() to carry out the removal, at which point all new readers will see element B as having been deleted from the list. However, there might be old readers still referencing this element. Once all these old readers have finished, we can safely free element B, resulting in the situation shown at the bottom of the figure.
But how can we tell when the readers are finished?
但是,你知道的,分配的数据块p仅仅适用偶尔偏移缺省值的情况,在恢复使用缺省值之后,被那些并发的reader threads访问的数据块p最终会被始乱终弃,当全部reader threads不再访问数据块p的时候,它会被释放掉。我们再来看一个更复杂的例子,这个例子是从链表中移除一个node,如下图所示:
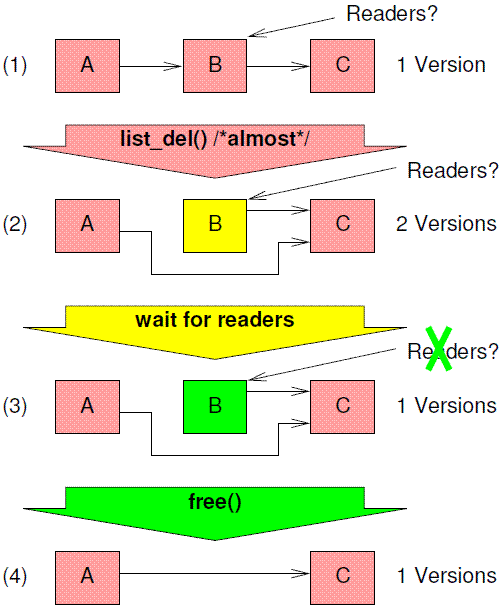
刚开始的时候,链表中有A、B、C三个node,我们准备删除B,因此调用list_del()函数来完成这个删除动作。一旦完成了这个动作,所有后续的reader看到的链表都是只有A、C两个Node,B被移除。不过,也需要还有其他旧的reader thread仍然在访问B node中的数据,一旦所有的旧的reader threads完成了对B的访问,我们就可以安全的释放B node的内存。
关键的问题来了:我们怎么才能知道所有的threader完成了对B的访问呢?
It is tempting to consider a reference-counting scheme, but Figure 5.3 in Chapter 5 shows that this can also result in long delays, just as can the locking and sequencelocking approaches that we already rejected.
Let’s consider the logical extreme where the readers do absolutely nothing to announce their presence. This approach clearly allows optimal performance for readers (after all, free is a very good price), but leaves open the question of how the updater can possibly determine when all the old readers are done. We clearly need some additional constraints if we are to provide a reasonable answer to this question.
一般大家很容易想到reference-couning机制,不过,在第五章的Figure 5.3中已经说明了,这种方法也会导致很长的delay,就像使用锁或者顺序锁机制一样,较长的delay让我们在real time场景中拒绝使用。
既然想让reader的delay尽量短些,何不让我们思考一个走极端逻辑,就是让reader根本不做任何事情,不声明自己是否存在于reader side临界区。这种方法显然大大优化了reader的性能(当然,自由是需要代价的),不过把检测旧的reader是否离开临界区的任务交给了updater。updater如何解决这个问题呢?显然,如果想提出一个合理的解决方法,我们需要一些额外的限制条件。
One constraint that fits well with some types of real-time operating systems (as well as some operating-system kernels) is to consider the case where threads are not subject to preemption. In such non-preemptible environments, each thread runs until it explicitly and voluntarily blocks. This means that an infinite loop without blocking will render a CPU useless for any other purpose from the start of the infinite loop onwards. Non-preemptibility also requires that threads be prohibited from blocking while holding spinlocks. Without this prohibition, all CPUs might be consumed by threads spinning attempting to acquire a spinlock held by a blocked thread. The spinning threads will not relinquish their CPUs until they acquire the lock, but the thread holding the lock cannot possibly release it until one of the spinning threads relinquishes a CPU. This is a classic deadlock situation.
有一个非常适合RTOS(也适合某些OS kernel)的限制就是禁止thread被抢占。在这样的非抢占的环境中,每一个线程都是持续运行,直到它显式的、自愿的阻塞,让出CPU。这也就意味着thread中一个无限循环的操作将永远的霸占CPU,从而让CPU无法执行其他的任务。非抢占的特性也要求thread不能持有spinlock进入睡眠。如果没有这个限制,竞争spinlock的thread就会不停的spin and spin,空耗了CPU的资源,而实际上,持有自旋锁的thread处于阻塞状态。而不停spin试图获取spinlock的那个thread也不会让出CPU。但是持锁的thread又需求其他thread让出CPU才能释放锁,这也就是一个经典的deadlock的场景。
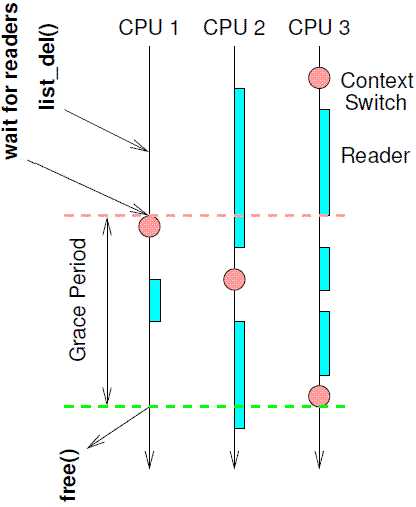
Let us impose this same constraint on reader threads traversing the linked list: such threads are not allowed to block until after completing their traversal. Returning to the second row of Figure 9.11, where the updater has just completed executing list_del(), imagine that CPU 0 executes a context switch. Because readers are not permitted to block while traversing the linked list, we are guaranteed that all prior readers that might have been running on CPU 0 will have completed. Extending this line of reasoning to the other CPUs, once each CPU has been observed executing a context switch, we are guaranteed that all prior readers have completed, and that there are no longer any reader threads referencing element B. The updater can then safely free element B, resulting in the state shown at the bottom of Figure 9.11.
让我们把上节描述的这个限制施加在遍历链表的reader thread:这个thread不允许阻塞,直到完成对整个链表的遍历。让我们返回上面图片的step (2),这时候,updater刚刚完成了list_del()的执行。我们来考虑一个这样的问题:如果CPU0发生了进程切换会怎么样呢?由于reader在遍历链表的时候不允许阻塞,因此一旦观察到CPU0上有进程切换,那么说明CPU0上的reader thread已经完成对链表的遍历。把这个思路推广到其他CPU上,就可以得出结论:如果所有的CPU都观察到一个进程切换,那么说明所有旧的reader thread已经完成,离开临界区,不再有旧的read thread还在访问B node中的内容。这时候updater可以安全的释放B node所占用的内容,从而将系统状态迁移到上图中的step (4)。
A schematic of this approach is shown in Figure 9.12, with time advancing from the top of the figure to the bottom.
下图展示了这个方法的示意图,时间轴是从上到下:
Although production-quality implementations of this approach can be quite complex, a toy implementatoin is exceedingly simple:
尽管产品级别的实现可以非常的复杂,不过一个简陋的,玩具级别的实现可以非常的简单,如下:
1 for_each_online_cpu(cpu)
2 run_on(cpu);
The for_each_online_cpu() primitive iterates over all CPUs, and the run_on() function causes the current thread to execute on the specified CPU, which forces the destination CPU to execute a context switch. Therefore, once the for_each_online_cpu() has completed, each CPU has executed a context switch, which in turn guarantees that all pre-existing reader threads have completed.
Please note that this approach is not production quality. Correct handling of a number of corner cases and the need for a number of powerful optimizations mean that production-quality implementations have significant additional complexity. In addition, RCU implementations for preemptible environments require that readers actually do something. However, this simple non-preemptible approach is conceptually complete, and forms a good initial basis for understanding the RCU fundamentals covered in the following section.
for_each_online_cpu() 原语就是在系统中所有的online的CPU上执行run_on()函数,run_on()函数会导致当前thread在制定的CPU上执行,当然也就意味着该CPU需要进行一次上下文切换。一旦上面的代码执行完毕,每一个CPU都会进行了一次上下文切换,这也保证了所有的旧的reader thread已经完成。
当然,需要注意的是这种方法虽然简单,但是不是产品级别的。产品级别的实现需要正确的处理各种各种正常的、异常的分支路径,并且要进行大量的性能优化,因此,产品级别的实现实际上是相当复杂的。此外,抢占环境下的RCU实现还需要reader thread做一些附加的操作(reader side临界区需要禁止抢占),无论如何,这个简单的,在非抢占环境中概念正确的RCU实现方法是一个理解RCU的良好的开始,后面我们将描述理解RCU的基础知识。
9.3.2 RCU Fundamentals
Authors: Paul E. McKenney and Jonathan Walpole
Read-copy update (RCU) is a synchronization mechanism that was added to the Linux kernel in October of 2002. RCU achieves scalability improvements by allowing reads to occur concurrently with updates. In contrast with conventional locking primitives that ensure mutual exclusion among concurrent threads regardless of whether they be readers or updaters, or with reader-writer locks that allow concurrent reads but not in the presence of updates, RCU supports concurrency between a single updater and multiple readers. RCU ensures that reads are coherent by maintaining multiple versions of objects and ensuring that they are not freed up until all pre-existing read-side critical sections complete. RCU defines and uses efficient and mechanisms for publishing and reading new versions of an object, and also for deferring the collection of old versions. These mechanisms distribute the work among read and update paths in such a way as to make read paths extremely fast. In some cases (non-preemptible kernels), RCU’s read-side primitives have zero overhead.
RCU是一种内核同步机制,在2002年10月份加入内核。由于允许多个reader thread和一个updater thread并发,因此RCU增强了scalability。与之不同的是传统的锁机制(例如spin lock)根本不区分reader和updater,只允许一个thread进入临界区。读写锁(rwlock)有所改进,允许多个read thread并发,但是仍然做不到reader和updater的并发。RCU可以支持一个updater和多个reader的并发。听起来有点神奇,实际上RCU是通过维护多个版本的数据来保证reader thread的数据访问一致性的(要么访问旧的,要么访问新的数据对象,不会mix up),并且保证旧的数据在现存的读临界区离开之后才释放掉。RCU定义了一套高效的、可扩展性非常优秀的机制来进行新版本数据对象的发布和访问,以及旧版本数据的延迟回收。这些机制分布在了read和update的控制路径中,并且确保reader一侧的性能非常的高,在某些情况下(非抢占式内核中),RCU的reader一侧的lock和unlock没有任何的开销。
This leads to the question “what exactly is RCU?”, and perhaps also to the question “how can RCU possibly work?” (or, not infrequently, the assertion that RCU cannot possibly work). This document addresses these questions from a fundamental viewpoint; later installments look at them from usage and from API viewpoints. This last installment also includes a list of references.
RCU is made up of three fundamental mechanisms, the first being used for insertion, the second being used for deletion, and the third being used to allow readers to tolerate concurrent insertions and deletions. Section 9.3.2.1 describes the publish-subscribe mechanism used for insertion, Section 9.3.2.2 describes how waiting for pre-existing RCU readers enabled deletion, and Section 9.3.2.3 discusses how maintaining multiple versions of recently updated objects permits concurrent insertions and deletions. Finally, Section 9.3.2.4 summarizes RCU fundamentals.
RCU有这么优秀的表现,相信你禁不住想问一句:那么什么是RCU呢,如何准确的定义它呢?它的工作原理是怎样的呢?适用哪些场景?哪些场景不能使用?不要着急,这份文档会首先从一些基本原理的角度为你一一解答,随后,本文会使用者的角度,或者说RCU API的角度来描述RCU提供的接口。文章的最后部分会给出一系列的示意性的参考实现。
理解RCU需要参透其三大基础机制:第一个用于插入新的数据,第二个用于删除旧的数据,第三个是reader如何游刃有余的穿梭在(来自updater thread)新数据的插入和旧数据的删除过程中,并且能够全身而退。9.3.2.1小节描述了publish-subscribe 机制,该机制用于新数据的插入。9.3.2.2小节描述了如何等待现存的RCU reader离开临界区,所有现存RCU reader飘然而去之时就是允许删除旧的数据之日。9.3.2.3小节描述了如何维护多个版本的受RCU保护的数据对象。最后,9.3.2.4小节进行了总结。
9.3.2.1 Publish-Subscribe Mechanism
One key attribute of RCU is the ability to safely scan data, even though that data is being modified concurrently. To provide this ability for concurrent insertion, RCU uses what can be thought of as a publish-subscribe mechanism. For example, consider an initially NULL global pointer gp that is to be modified to point to a newly allocated and initialized data structure. The code fragment shown in Figure 9.13 (with the addition of appropriate locking) might be used for this purpose.
RCU机制有一个很重要的特点就是在有并发修改的情况下仍然允许reader thread对数据进行遍历扫描。为了实现这一个关键的特点,RCU使用了publish-subscribe的机制。我们举一个例子:有一个初始化为NULL的全局指针gp,我们分配了一段内存并初始化它,然后让gp指向这段新分配的内存,代码如下:
1 struct foo {
2 int a;
3 int b;
4 int c;
5 };
6 struct foo *gp = NULL;
7
8 /* . . . */
9
10 p = kmalloc(sizeof(*p), GFP_KERNEL);
11 p->a = 1;
12 p->b = 2;
13 p->c = 3;
14 gp = p;
Unfortunately, there is nothing forcing the compiler and CPU to execute the last four assignment statements in order. If the assignment to gp happens before the initialization of p fields, then concurrent readers could see the uninitialized values. Memory barriers are required to keep things ordered, but memory barriers are notoriously difficult to use. We therefore encapsulate them into a primitive rcu_assign_pointer() that has publication semantics. The last four lines would then be as follows:
很不幸,由于没有对编译器和CPU施加任何的强制措施,上面的程序中的最后四句的赋值语句并不能保证顺序,如果gp的赋值发生在了对p的各个成员赋值之前,那么并发的reader thread可能会看到没有初始化的内存。我们可以使用memory barrier来保证内存访问顺序,不过由于memory barrier灰常的难于使用,因此这里对其进行了封装,并且提供了一个RCU原语rcu_assign_pointer(),这个原语有公布天下之语义。这样,最后四行代码被修改为:
1 p->a = 1;
2 p->b = 2;
3 p->c = 3;
4 rcu_assign_pointer(gp, p);
The rcu_assign_pointer() would publish the new structure, forcing both the compiler and the CPU to execute the assignment to gp after the assignments to the fields referenced by p.
However, it is not sufficient to only enforce ordering at the updater, as the reader must enforce proper ordering as well. Consider for example the following code fragment:
rcu_assign_pointer()原语可以将新分配的内存(并且已经初始化)公布于众,并且强制编译器和CPU进行内存访问顺序的保证:首先对p指向的各个数据成员进行赋值,之后再对gp赋值。当然,只是在updater一侧保证顺序是不够的,reader一侧也要有顺序保证,下面是一段示例代码:
1 p = gp;
2 if (p != NULL) {
3 do_something_with(p->a, p->b, p->c);
4 }
Although this code fragment might well seem immune to misordering, unfortunately, the DEC Alpha CPU [McK05a, McK05b] and value-speculation compiler optimizations can, believe it or not, cause the values of p->a, p->b, and p->c to be fetched before the value of p. This is perhaps easiest to see in the case of value-speculation compiler optimizations, where the compiler guesses the value of p fetches p->a, p->b, and p->c then fetches the actual value of p in order to check whether its guess was correct. This sort of optimization is quite aggressive, perhaps insanely so, but does actually occur in the context of profile-driven optimization.
Clearly, we need to prevent this sort of skullduggery on the part of both the compiler and the CPU. The rcu_dereference() primitive uses whatever memory-barrier instructions and compiler directives are required for this purpose:
尽管上面的代码可能看起来不会乱序,但是,很不幸,在DEC Alpha CPU 上以及支持value-speculation优化的编译器的情况下,对p->a, p->b, 以及 p->c的数据访问(第三行)会在对p的访问(第一行)之前完成。听起来有些神奇,但是事实就是如此,可能用编译器value-speculation优化的例子更好理解一些:对于上面的程序片段,编译器会猜测p值并且通过p访问其成员(p->a, p->b, p->c ),然后读取p值,以便检测猜测是否正确。这种优化的力度非常大,甚至是有点过了头,不过的确是存在于profile-driven的优化场景中(这里我也是不太理解,我猜测这里的profile是性能剖析的意思,profile-driven optimization就是以性能剖析为导向的优化)。
毫无疑问,我们必须阻止编译器以及CPU的这部分的诡计得逞,为了达到这个目的,我们提供了rcu_dereference()原语(具体该原语使用了什么底层的memory barrier的指令,或者使用哪一种编译器优化屏障我们就不深究了),修改后的代码如下:
1 rcu_read_lock();
2 p = rcu_dereference(gp);
3 if (p != NULL) {
4 do_something_with(p->a, p->b, p->c);
5 }
6 rcu_read_unlock();
The rcu_dereference() primitive can thus be thought of as subscribing to a given value of the specified pointer, guaranteeing that subsequent dereference operations will see any initialization that occurred before the corresponding rcu_assign_pointer() operation that published that pointer. The rcu_read_lock() and rcu_read_unlock() calls are absolutely required: they define the extent of the RCU read-side critical section. Their purpose is explained in Section 9.3.2.2, however, they never spin or block, nor do they prevent the list_add_rcu() from executing concurrently. In fact, in non-CONFIG_PREEMPT kernels, they generate absolutely no code.
rcu_dereference()可以被认为是指针变量赋值的操作,针对上面的代码片段,p就是后续需要操作的指针变量,通过对该变量进行dereference操作,可以访问RCU protected data。rcu_dereference()原语可以保证后续通过p进行的dereference操作可以看到rcu_assign_pointer()之前对RCU protected data初始化的值,这里,rcu_assign_pointer()也就是传说中的将指针公之于众(publish)的操作。rcu_read_lock() 和 rcu_read_unlock() 操作当然也是需要的,它们定义了读侧的RCU临界区。这部分的内容将在9.3.2.2小节描述,这里简单过一下。rcu_read_lock() 和 rcu_read_unlock() 的操作不会spin,也不会block当前thread,当然更不会阻碍list_add_rcu() 这样操作的并发执行。实际上,在非抢占式内核中,这些原语实际上是空的,不包括任何的代码。
Although rcu_assign_pointer() and rcu_dereference() can in theory be used to construct any conceivable RCU-protected data structure, in practice it is often better to use higher-level constructs. Therefore, the rcu_assign_pointer() and rcu_dereference() primitives have been embedded in special RCU variants of Linux’s list-manipulation API. Linux has two variants of doubly linked list, the circular struct list_head and the linear struct hlist_head/struct hlist_node pair. The former is laid out as shown in Figure 9.14, where the green (leftmost) boxes represent the list header and the blue (rightmost three) boxes represent the elements in the list. This notation is cumbersome, and will therefore be abbreviated as shown in Figure 9.15, which shows only the non-header (blue) elements.
Adapting the pointer-publish example for the linked list results in the code shown in Figure 9.16.
尽管rcu_assign_pointer() 和 rcu_dereference() 这两个原语理论上可以使用在任何的需要RCU保护的数据,不过,在实际中还是推荐使用更高层一些的接口。因此,如果你的场景中受RCU保护的数据是链表,那么rcu_assign_pointer() 和 rcu_dereference() 这对原语被隐藏在Linux 链表操作API中,当然不是普通的链表操作API,是RCU变种类型的链表操作。Linux中有两种双向链表,一种是环形结构的list_head,另外一种是线性结构的hlist_head/struct hlist_node对。环形结构如下图所示:
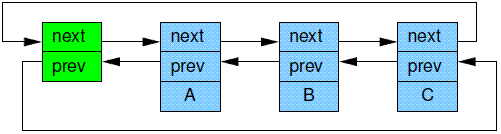
绿色的是链表头(最左边的那个),右边3个蓝色的block是链表上的一个个的节点。这样的表示方法有点笨重,我们简化如下:

由于省略了链表头,这个链表结构看起来简洁多了。
下面我们修改一下上面的pointer-publish示例代码,如下:
1 struct foo {
2 struct list_head *list;
3 int a;
4 int b;
5 int c;
6 };
7 LIST_HEAD(head);
8
9 /* . . . */
10
11 p = kmalloc(sizeof(*p), GFP_KERNEL);
12 p->a = 1;
13 p->b = 2;
14 p->c = 3;
15 list_add_rcu(&p->list, &head);
Line 15 must be protected by some synchronization mechanism (most commonly some sort of lock) to prevent multiple list_add_rcu() instances from executing concurrently. However, such synchronization does not prevent this list_add() instance from executing concurrently with RCU readers.
Subscribing to an RCU-protected list is straightforward:
上面第15行的代码必须使用某种同步机制来保护(一般会使用某种锁的机制),以便防止多个list_add_rcu()并发执行。当然,这种同步机制不会阻止并发的RCU reader thread。
上面描述了如何公布于众(publish),我们再来看看如果derefence,代码如下:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, head, list) {
3 do_something_with(p->a, p->b, p->c);
4 }
5 rcu_read_unlock();
The list_add_rcu() primitive publishes an entry, inserting it at the head of the specified list, guaranteeing that the corresponding list_for_each_entry_rcu() invocation will properly subscribe to this same entry.
list_add_rcu() 这个原语将新的节点公布于众,插入到了指定链表的头部。保证了在list_for_each_entry_rcu()接口中遍历链表操作的时候,看到的新节点数据是有初始化后的内容。
Linux’s other doubly linked list, the hlist, is a linear list, which means that it needs only one pointer for the header rather than the two required for the circular list, as shown in Figure 9.17. Thus, use of hlist can halve the memory consumption for the hash-bucket arrays of large hash tables. As before, this notation is cumbersome, so hlists will be abbreviated in the same way lists are, as shown in Figure 9.15.
hlist是linux kernel中的另外一种双向链表,是一种线性链表,其header只有一个指针指向第一个节点,而不是两个,形成环状结构。具体结构如下:
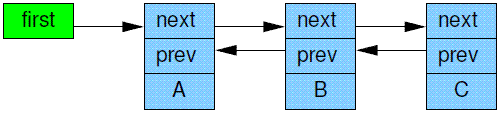
这种链表在构建大型哈希表的时候可以节省内存。同样的,这样的表示方法有点笨重,我们可以做类似环状结构链表的简化。
Publishing a new element to an RCU-protected hlist is quite similar to doing so for the circular list, as shown in Figure 9.18.
As before, line 15 must be protected by some sort of synchronization mechanism, for example, a lock.
Subscribing to an RCU-protected hlist is also similar to the circular list:
向一个受RCU保护的线性链表中插入一个新的节点并公布于众,其代码类似环形链表,代码如下:
1 struct foo {
2 struct hlist_node *list;
3 int a;
4 int b;
5 int c;
6 };
7 HLIST_HEAD(head);
8
9 /* . . . */
10
11 p = kmalloc(sizeof(*p), GFP_KERNEL);
12 p->a = 1;
13 p->b = 2;
14 p->c = 3;
15 hlist_add_head_rcu(&p->list, &head);
和上面的环形链表类似,第15行的代码必须需要某种同步机制的保护。遍历受RCU保护的线性链表操作也类似:
1 rcu_read_lock();
2 hlist_for_each_entry_rcu(p, q, head, list) {
3 do_something_with(p->a, p->b, p->c);
4 }
5 rcu_read_unlock();
The set of RCU publish and subscribe primitives are shown in Table 9.2, along with additional primitives to “unpublish”, or retract.
Note that the list_replace_rcu(), list_del_rcu(), hlist_replace_rcu(), and hlist_del_rcu() APIs add a complication. When is it safe to free up the data element that was replaced or removed? In particular, how can we possibly know when all the readers have released their references to that data element?
These questions are addressed in the following section.
完整的RCU publish(将新分配的数据公布于众)、retract(删除一个节点,也就是unpublish)和subscribe(获取指向新分配数据的指针并dereference) 原语可以参考下面的表格:
| Category | Publish | Retract | Subscribe |
| Pointers | rcu_assign_pointer() | rcu_assign_pointer(..., NULL) | rcu_dereference() |
| Lists |
list_add_rcu() list_add_tail_rcu() list_replace_rcu() |
list_del_rcu() | list_for_each_entry_rcu() |
| Hlists |
hlist_add_after_rcu() hlist_add_before_rcu() hlist_add_head_rcu() hlist_replace_rcu() |
hlist_del_rcu() | hlist_for_each_entry_rcu() |
这里list_replace_rcu(), list_del_rcu(), hlist_replace_rcu(), 和hlist_del_rcu() 接口API稍微复杂一些:什么时候释放被删除或者被替换的节点内存才是安全的呢?换句话就是说:我们怎么知道所有的RCU reader不再访问这些节点内存(如果RCU reader在释放后还访问这些内存,会造成严重的后果)?这些问题我们将在后续的章节中描述。
9.3.2.2 Wait For Pre-Existing RCU Readers to Complete
In its most basic form, RCU is a way of waiting for things to finish. Of course, there are a great many other ways of waiting for things to finish, including reference counts, reader-writer locks, events, and so on. The great advantage of RCU is that it can wait for each of (say) 20,000 different things without having to explicitly track each and every one of them, and without having to worry about the performance degradation, scalability limitations, complex deadlock scenarios, and memory-leak hazards that are inherent in schemes using explicit tracking.
In RCU’s case, the things waited on are called “RCU read-side critical sections”. An RCU read-side critical section starts with an rcu_read_lock() primitive, and ends with a corresponding rcu_read_unlock() primitive. RCU read-side critical sections can be nested, and may contain pretty much any code, as long as that code does not explicitly block or sleep (although a special form of RCU called SRCU [McK06] does permit general sleeping in SRCU read-side critical sections). If you abide by these conventions, you can use RCU to wait for any desired piece of code to complete.
RCU accomplishes this feat by indirectly determining when these other things have finished [McK07f, McK07a].
RCU的基本的形式其实就是等待某些事情(RCU reader离开临界区)完成,当然,实际上我们有很多的机制可以达到这样的功能,包括:reference counts, reader-writer locks, events等等。而RCU的最大的好处是它可以等待非常多个(例如:20000)不同的事情结束,并且不需要显式的跟踪每一个事情,从而不会担心性能降低、可扩展性的限制、复杂的死锁场景、内存泄露,对于那些显式跟踪机制,这些噩梦般的问题如影随形。
对于RCU而言,它等待的事情就是RCU read-side临界区。该临界区开始于rcu_read_lock()原语,结束于rcu_read_unlock() 原语。RCU读侧临界区可以嵌套,也可以包括非常多的代码,只要这些代码不会阻塞或者睡眠(有一个特别的RCU叫做SRCU,它的临界区的确是允许睡眠的)。只要你遵守这些规则,你就可以使用RCU机制来等待任何你想要等待其完成的代码片段。
看起来RCU的等待机制非常困难,但是,RCU通过一些间接的手段来判断某些事情已经结束,从而完成了这个精巧的设计。
In particular, as shown in Figure 9.19, RCU is a way of waiting for pre-existing RCU read-side critical sections to completely finish, including memory operations executed by those critical sections. However, note that RCU read-side critical sections that begin after the beginning of a given grace period can and will extend beyond the end of that
grace period.
就像下图展示的那样,RCU是一个等待之前存在的RCU读侧临界区完成的机制,这包括了临界区中的代码对内存的访问操作。不过,需要注意的是:如果一个读侧临界区在某个Grace Period的开始点之后才开始,那么这些读临界区可以在grace period之后完成(也就是说不需要等待这些读临界区,它们不是pre-existing的临界区)。
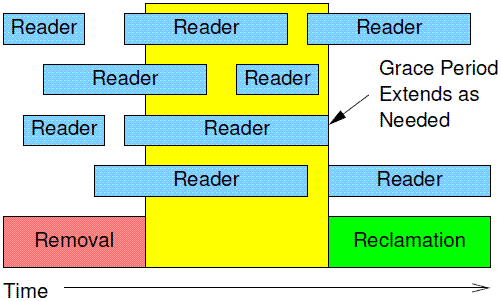
The following pseudocode shows the basic form of algorithms that use RCU to wait for readers:
1. Make a change, for example, replace an element in a linked list.
2. Wait for all pre-existing RCU read-side critical sections to completely finish (for example, by using the synchronize_rcu() primitive). The key observation here is that subsequent RCU read-side critical sections have no way to gain a reference to the newly removed element.
3. Clean up, for example, free the element that was replaced above.
下面的伪代码展示了RCU等待读临界区的基本算法:
(1)writer thread执行任务,比如:替换一个链表上的节点
(2)等待所有pre-existing的读侧临界区完成(例如通过调用synchronize_rcu()接口API)。这里的关键点就是:随后进入读临界区的reader thread没有办法访问那个被替换掉的节点,它看到的是新的链表数据。
(3)清理工作。例如释放掉被替换掉的那个节点的内存
The code fragment shown in Figure 9.20, adapted from those in Section 9.3.2.1, demonstrates this process, with field a being the search key. Lines 19, 20, and 21 implement the three steps called out above. Lines 16-19 gives RCU (“read-copy update”) its name: while permitting concurrent reads, line 16 copies and lines 17-19 do an update.
下面的代码片段是修改自Section 9.3.2.1的代码,如下:
1 struct foo {
2 struct list_head *list;
3 int a;
4 int b;
5 int c;
6 };
7 LIST_HEAD(head);
8
9 /* . . . */
10
11 p = search(head, key);
12 if (p == NULL) {
13 /* Take appropriate action, unlock, & return. */
14 }
15 q = kmalloc(sizeof(*p), GFP_KERNEL);
16 *q = *p;
17 q->b = 2;
18 q->c = 3;
19 list_replace_rcu(&p->list, &q->list);
20 synchronize_rcu();
21 kfree(p);
上面的代码展示了RCU等待读临界区结束的过程。在代码中,struct foo的a成员是做为search key出现的。第19,20,21行的代码实现了上文中描述的三个步骤。16~19行分别执行了read copy update的操作,这也是RCU名字的源由:在允许read的同时,16行程序进行了copy,17~19执行了update的操作。
As discussed in Section 9.3.1, the synchronize_rcu() primitive can be quite simple (see Section 9.3.5 for additional “toy” RCU implementations). However, production-quality implementations must deal with difficult corner cases and also incorporate powerful optimizations, both of which result in significant complexity. Although it is good to know that there is a simple conceptual implementation of synchronize_rcu(), other questions remain. For example, what exactly do RCU readers see when traversing a concurrently updated list? This question is addressed in the following section.
我们在9.3.1小节说过,synchronize_rcu() 原语可以非常的简单(可以参考Section 9.3.5 中那个类似玩具的RCU实现),不过,产品级别的实现必须考虑各种边边角角的case,同时也要兼顾功耗方面的考量,这些才是RCU实现变得异常复杂的原因。尽管,我们了解synchronize_rcu()简单的,概念性的实现是有好处的,不过要知道,这个实现还是存在很多其他的问题。例如:在并发进行update操作的时候,不断进入临界区的RCU reader们看到的受RCU保护的数据是怎样的呢?这个问题我们会在下面的小节中描述。
9.3.2.3 Maintain Multiple Versions of Recently Updated Objects
This section demonstrates how RCU maintains multiple versions of lists to accommodate synchronization-free readers. Two examples are presented showing how an element that might be referenced by a given reader must remain intact while that reader remains in its RCU read-side critical section. The first example demonstrates deletion of a list element, and the second example demonstrates replacement of an element.
这一个小节主要描述RCU如何维护多个版本的链表数据,正因为如此,RCU reader们才能不需要和writer进行同步,任意的杀入临界区。这里会提供两个例子,这些例子可以展示当某个reader在访问一个节点数据的时候,该数据如何能够做到毫发无伤(不会被释放),直到reader离开读侧临界区。第一个例子是说节点删除的场景,第二个例子说明了节点替换的场景。
Example 1: Maintaining Multiple Versions During Deletion We can now revisit the deletion example from Section 9.3.1, but now with the benefit of a firm understanding of the fundamental concepts underlying RCU. To begin this new version of the deletion example, we will modify lines 11-21 in Figure 9.20 to read as follows:
例子1:在删除节点的时候维护多个版本的链表数据
既然现在我们已经对RCU的基本原理和概念有了一定的理解,那么可以一起来review 9.3.1小节中的删除节点的代码。为了更好的贴近这个小节的主题,我们对代码的11~21行进行了修改,如下:
1 p = search(head, key);
2 if (p != NULL) {
3 list_del_rcu(&p->list);
4 synchronize_rcu();
5 kfree(p);
6 }
This code will update the list as shown in Figure 9.21. The triples in each element represent the values of fields a, b, and c, respectively. The red-shaded elements indicate that RCU readers might be holding references to them, so in the initial state at the top of the diagram, all elements are shaded red. Please note that we have omitted the backwards pointers and the link from the tail of the list to the head for clarity.
上面的代码会按照下图的方式对链表进行更新:
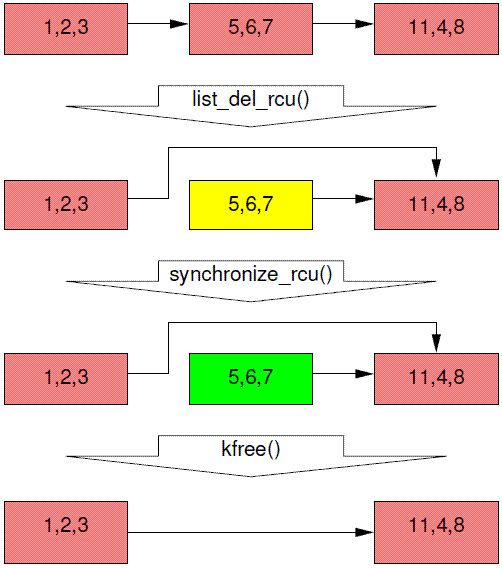
每个节点上的三个数字是表示foo结构体的a b c三个成员的值。红色block表示的节点说明RCU reader仍然保持了对该节点数据的访问。第一行展示的是链表的初始状态,所有的节点都是红色的。另外需要说明的是:上图中,为了让图片变得简洁,我们省略了双向链表的后向箭头。
After the list_del_rcu() on line 3 has completed, the 5,6,7 element has been removed from the list, as shown in the second row of Figure 9.21. Since readers do not synchronize directly with updaters, readers might be concurrently scanning this list. These concurrent readers might or might not see the newly removed element, depending on timing. However, readers that were delayed (e.g., due to interrupts, ECC memory errors, or, in CONFIG_PREEMPT_RT kernels, preemption) just after fetching a pointer to the newly removed element might see the old version of the list for quite some time after the removal. Therefore, we now have two versions of the list, one with element 5,6,7 and one without. The 5,6,7 element in the second row of the figure is now shaded yellow, indicating that old readers might still be referencing it, but that new readers cannot obtain a reference to it.
在程序中的第三行,list_del_rcu()执行完毕之后,标着5,6,7的那个节点被从链表中删除,我们可以用上面图片中的第二行示意图表示。由于updater并没有阻止各个reader的乱入,因此reader可以并发的scan这个链表,这时候,乱入的reader可能看到标注5,6,7的那个节点被删除,也可能看不到,看到或者看不到是和时序相关。然而,在获取了指向标着5,6,7的那个节点的指针之后,reader可能会呆在临界区中较长的时间(例如:终端、ECC memory errors或者配置了CONFIG_PREEMPT_RT的情况下,reader thread在临界区内被抢占),从而有可能在调用list_del_rcu删除该节点之后的较长的时间内,都可能会访问该节点的数据。因此,这时候,整个系统中有两个版本的链表数据:一个是有5、6、7节点的链表,一个是没有5、6、7节点的链表。第二行的5、6、7节点被标注为黄色,表示之前的RCU reader有可能仍然保持对该节点的访问,不过,新来的reader不可能看到它。
Please note that readers are not permitted to maintain references to element 5,6,7 after exiting from their RCU read-side critical sections. Therefore, once the synchronize_rcu() on line 4 completes, so that all pre-existing readers are guaranteed to have completed, there can be no more readers referencing this element, as indicated by its green shading on the third row of Figure 9.21. We are thus back to a single version of the list.
At this point, the 5,6,7 element may safely be freed, as shown on the final row of Figure 9.21. At this point, we have completed the deletion of element 5,6,7. The following section covers replacement.
需要注意的是,即便reader持有了访问5、6、7节点的指针,一旦离开了临界区,该reader将不允许再次访问该节点。因此,第四行的synchronize_rcu() 执行完毕后,所有之前存在的reader保证已经离开临界区,因此就没有任何的reader会访问那个被删除的5、6、7节点,这时候,我们把把标注为绿色,可以参考上图的第三行。至此,系统中又恢复了只有一个版本链表数据的状态。
因此,这时候我们可以安全的将5、6、7节点的数据释放掉,就像上图中最后一行显示的那样。最终我们完成了删除5、6、7节点的全部过程,下面我们进入节点替换的例子。
Example 2: Maintaining Multiple Versions During Replacement
To start the replacement example, here are the last few lines of the example shown in Figure 9.20:
例子2:在节点替换的时候维护多个版本的链表数据
为了说明节点替换的例子,我们仍然需要对上一小节中程序中的最后几行进行修改:
1 q = kmalloc(sizeof(*p), GFP_KERNEL);
2 *q = *p;
3 q->b = 2;
4 q->c = 3;
5 list_replace_rcu(&p->list, &q->list);
6 synchronize_rcu();
7 kfree(p);
The initial state of the list, including the pointer p, is the same as for the deletion example, as shown on the first row of Figure 9.22.
就像删除节点的例子那样,下图中的第一行也是显示的是链表的初始状态:
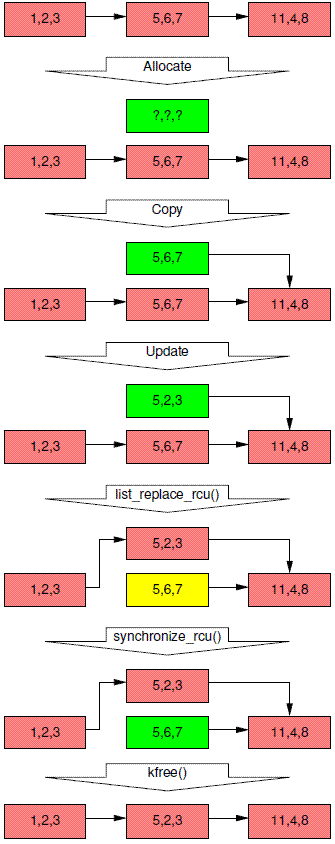
As before, the triples in each element represent the values of fields a, b, and c, respectively. The red-shaded elements might be referenced by readers, and because readers do not synchronize directly with updaters, readers might run concurrently with this entire replacement process. Please note that we again omit the backwards pointers and the link from the tail of the list to the head for clarity.
The following text describes how to replace the 5,6,7 element with 5,2,3 in such a way that any given reader sees one of these two values.
和上面的例子一样,节点block上的三个数字表示foo结构体的a b c三个成员的值。红色表示该节点数据有可能被reader访问到。同样的,在替换节点的时候,各个reader可以自由的进入临界区,和updater并发进行。同样的,表述简洁,我们也省略了双向链表的后向指针。下面的文字将描述5、6、7那个节点是如何被5、2、3节点替换掉的,在这种情况下,乱入的reader会看到两个版本链表数据中的一个。
Line 1 kmalloc()s a replacement element, as follows, resulting in the state as shown in the second row of Figure 9.22. At this point, no reader can hold a reference to the newly allocated element (as indicated by its green shading), and it is uninitialized (as indicated by the question marks).
Line 2 copies the old element to the new one, resulting in the state as shown in the third row of Figure 9.22. The newly allocated element still cannot be referenced by readers, but it is now initialized.
Line 3 updates q->b to the value “2”, and line 4 updates q->c to the value “3”, as shown on the fourth row of Figure 9.22.
第一行的kmalloc分配了新节点的内存,对应上图中的第二行。在这个时间点,没有reader能够对该节点的内容进行访问(因此用绿色表示),不过该节点的内容都还没有初始化,因此用?表示。第二行把旧的数据copy到新分配的这个节点内存中,可以参考上图中第三行的block diagram。同样的,reader仍然无法访问该节点,因此,仍然是绿色block,只不过其内容已经初始化。程序中的第三行和第四行是对新节点的成员变量进行赋值,可以参考上图中的第四行。
Now, line 5 does the replacement, so that the new element is finally visible to readers, and hence is shaded red, as shown on the fifth row of Figure 9.22. At this point, as shown below, we have two versions of the list. Pre-existing readers might see the 5,6,7 element (which is therefore now shaded yellow), but new readers will instead see the 5,2,3 element. But any given reader is guaranteed to see some well-defined list.
第五行程序是执行具体的替换动作,因此,新的节点最终被广大的reader们看到,因此,该节点的颜色也变成红色,如上图中的第五行所示。在这个时间点上,系统中有两个版本的链表数据,之前存在的reader可以看到包含5、6、7节点(因此用黄色标识)的链表数据,,而新的reader看到的则是包括5、2、3节点的链表数据,同样的,一个指定的reader只能看到其一。
After the synchronize_rcu() on line 6 returns, a grace period will have elapsed, and so all reads that started before the list_replace_rcu() will have completed. In particular, any readers that might have been holding references to the 5,6,7 element are guaranteed to have exited their RCU read-side critical sections, and are thus prohibited from continuing to hold a reference. Therefore, there can no longer be any readers holding references to the old element, as indicated its green shading in the sixth row of Figure 9.22. As far as the readers are concerned, we are back to having a single version of the list, but with the new element in place of the old.
After the kfree() on line 7 completes, the list will appear as shown on the final row of Figure 9.22.
Despite the fact that RCU was named after the replacement case, the vast majority of RCU usage within the Linux kernel relies on the simple deletion case shown in Section 9.3.2.3.
在程序第六行的synchronize_rcu() 调用返回之后,grace period已经过去,因此所有的在list_replace_rcu() 调用之前进入临界区的reader都已经离开了临界区,任何的reader都不会再访问5、6、7节点的数据了,因此,该节点又变成绿色,参考上图中的第六行。从reader的角度看,系统又回到了一个版本链表数据的状态,不过是用了新的节点数据(5、2、3节点)而不是旧的那个节点(5、6、7节点)。第七行的kfree之后,旧的节点内存被释放,如上图中的最后一行所示。尽管,RCU的名字是由于在节点替换这个场景而出给的,不过linux内核中使用更多的是删除(上面的例子1)。
Discussion These examples assumed that a mutex was held across the entire update operation, which would mean that there could be at most two versions of the list active at a given time。
Quick Quiz 9.23: How would you modify the deletion example to permit more than two versions of the list to be active?
Quick Quiz 9.24: How many RCU versions of a given list can be active at any given time?
This sequence of events shows how RCU updates use multiple versions to safely carry out changes in presence of concurrent readers. Of course, some algorithms cannot gracefully handle multiple versions. There are techniques for adapting such algorithms to RCU [McK04], but these are beyond the scope of this section.
讨论:这些例子中,我们都是假设在整个的更新过程中都是持有互斥锁,也就是说,这意味着在系统中,在一个给定的时间点上,最多只有两个版本的链表数据。我们可以扩展一下思维:能否修改代码让系统中存在多于2个版本的链表数据的情况呢?在这种情况下,系统最多有多少个版本的数据呢?
其实,如果synchronize_rcu没有包含在互斥锁保护的write临界区内,更多版本(而不是新旧两个版本)的链表数据也是可能的,考虑下面的操作序列:
(1)R1 reader 正在访问D1节点的数据,并且在读临界区内
(2)W1 updater thread删除了D1节点数据,阻塞在synchronize_rcu中,注意:这时候W1 thread离开了write临界区
(3)R2 reader 正在访问D2节点的数据,并且在读临界区内
(4)W2 updater thread删除了D2节点数据,阻塞在synchronize_rcu中
上面的操作可以不断重复,从而可以让给定的时间点上,系统中的链表数据可以有任意多个。上面的操作序列事件展示了在并发reader的情况下,RCU的updater如何利用多个版本的链表数据来执行更新链表的任务。当然,有些算法不能优雅的处理多个版本的数据,这时候,我们可以修改其算法,把保护策略转到RCU上来(具体参考文献[McK04]),不过这不是本文要关注的事情。
9.3.2.4 Summary of RCU Fundamentals
This section has described the three fundamental components of RCU-based algorithms:
1. a publish-subscribe mechanism for adding new data,
2. a way of waiting for pre-existing RCU readers to finish, and
3. a discipline of maintaining multiple versions to permit change without harming or unduly delaying concurrent RCU readers.
本小节描述了RCU机制的三个基本基础算法:
(1)updater如何将新的数据公布于众,各个reader们如何去访问共享的数据。
(2)如何等待之前已经存在的RCU reader离开临界区
(3)为了不会影响并发的reader线程,系统维护了多个版本的数据。
These three RCU components allow data to be updated in face of concurrent readers, and can be combined in different ways to implement a surprising variety of different types of RCU-based algorithms, some of which are described in the following section.
这三个基本的算法允许在reader并发的情况下修改数据,并且它们三个可以组合起来形成各种各样的各具特色的RCU算法,我们会在后续的章节中描述。
9.3.3 RCU Usage
This section answers the question “what is RCU?” from the viewpoint of the uses to which RCU can be put. Because RCU is most frequently used to replace some existing mechanism, we look at it primarily in terms of its relationship to such mechanisms, as listed in Table 9.3. Following the sections listed in this table, Section 9.3.3.8 provides a summary.
本节从RCU能够应用到哪些场合的角度上,回答了什么是RCU这个问题。由于RCU主要是用来替换现存的一些算法或者机制的,因此,本节我们重点是比对这些被替换的算法和RCU直接有什么不同的,有什么联系。我们把这些替换的情况罗列在下面的表格中:
| Mechanism RCU Replaces | Section |
|
Reader-writer locking Section Restricted reference-counting mechanism Section Bulk reference-counting mechanism Section Poor man’s garbage collector Section Existence Guarantees Section Type-Safe Memory Section Wait for things to finish Section |
9.3.3.1 9.3.3.2 9.3.3.3 9.3.3.4 9.3.3.5 9.3.3.6 9.3.3.7 |
9.3.3.8小节是最后的总结陈词。
9.3.3.1 RCU is a Reader-Writer Lock Replacement
Perhaps the most common use of RCU within the Linux kernel is as a replacement for reader-writer locking in read-intensive situations. Nevertheless, this use of RCU was not immediately apparent to me at the outset, in fact, I chose to implement a lightweight reader-writer lock [HW92] before implementing a general-purpose RCU implementation back in the early 1990s. Each and every one of the uses I envisioned for the lightweight reader-writer lock was instead implemented using RCU. In fact, it was more than three years before the lightweight reader-writer lock saw its first use. Boy, did I feel foolish!
也许在linux kernel中,RCU最常用的场景就是用来替换读多写少的rwlock。不过,在一开始我并没有意识到这一点,实际上,回到1990年底初期,在实现通用RCU机制之前,我选择了实现一个轻量级的rwlock(参考文献[HW92])的方法来解决rwlock scalability比较差的问题。不过任何一个想到的轻量级读写锁最后都是使用RCU的替代实现而已。实际上,在轻量级读写锁有了第一次应用之前,我大概在上面折腾了3年的时间,OMG,我多么的傻啊。
The key similarity between RCU and reader-writer locking is that both have readside critical sections that can execute in parallel. In fact, in some cases, it is possible to mechanically substitute RCU API members for the corresponding reader-writer lock API members. But first, why bother?
Advantages of RCU include performance, deadlock immunity, and realtime latency. There are, of course, limitations to RCU, including the fact that readers and updaters run concurrently, that low-priority RCU readers can block high-priority threads waiting for a grace period to elapse, and that grace-period latencies can extend for many milliseconds. These advantages and limitations are discussed in the following sections.
RCU和读写锁之间最主要的相同点就是:它们两个都允许reader可以在读侧临界区内并发执行,实际上,在某些场合下,可以机械的用RCU的API来替换对应的rwlock API。那么,问题来了,我们为何要如此麻烦做这样的替换呢?
RCU的优势就是:性能、不会死锁,realtime需要的各种延迟比较低。当然,RCU也有其使用局限,例如:reader和updater并发执行的时候,高优先级的线程在等待grace period结束,这时候,游荡在读临界区的低优先级的RCU reader可以阻止高优先级线程的执行,在比较恶劣的情况下,grace period的时间可以长达若干个毫秒。我们在下面的小节中就会讨论这些优点和限制。
Performance The read-side performance advantages of RCU over reader-writer locking are shown in Figure 9.23
RCU性能分析:
下面的图片展示了RCU和rwlock在读侧性能对比:
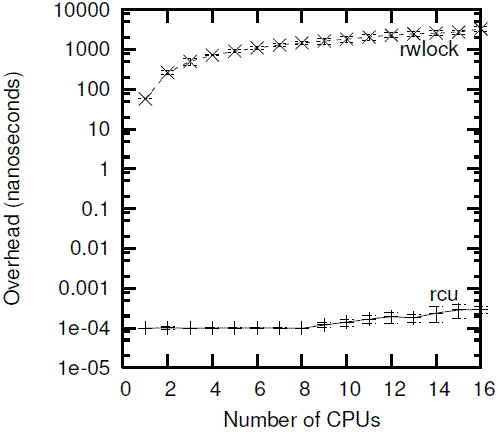
Note that reader-writer locking is orders of magnitude slower than RCU on a single CPU, and is almost two additional orders of magnitude slower on 16 CPUs. In contrast, RCU scales quite well. In both cases, the error bars span a single standard deviation in either direction.
A more moderate view may be obtained from a CONFIG_PREEMPT kernel, though RCU still beats reader-writer locking by between one and three orders of magnitude, as shown in Figure 9.24. Note the high variability of reader-writer locking at larger numbers of CPUs. The error bars span a single standard deviation in either direction.
Of course, the low performance of reader-writer locking in Figure 9.24 is exaggerated by the unrealistic zero-length critical sections. The performance advantages of RCU become less significant as the overhead of the critical section increases, as shown in Figure 9.25 for a 16-CPU system, in which the y-axis represents the sum of the overhead of the read-side primitives and that of the critical section.
在一个CPU的情况下,rwlock比RCU慢了几个数量级,在16个CPU的情况下,差距进一步扩大了2个数量级。因此,和rwlock比起来,RCU的可扩展性非常好。无论是rwlock还是RCU,实际的测量都是一组数据,图中的性能曲线都是取的平均值,error bar(曲线上下有两个小横线)则展示了标准差的情况。
对于配置了CONFIG_PREEMPT内核而言,尽管RCU仍然能秒杀rwlock(1~3个数量级),性能对比已经没有象上面那么惨烈了,具体参考下图:
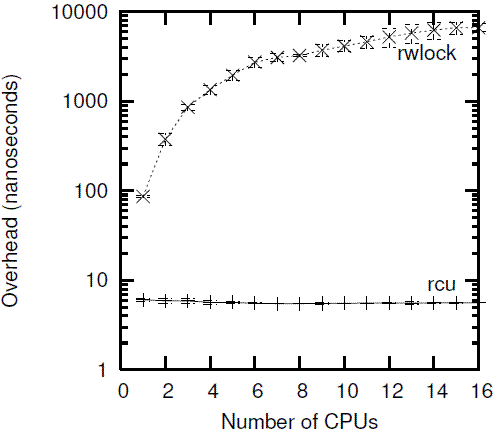
我们需要特别关注一下rwlock在CPU数目比较多的时候读侧的性能变化,通用的error bar展示了标准差的大小(CPU数目少的时候,标准差也小,CPU数目变多之后,标准差变大了,说明统计数据的离散程度在加剧)。
当然,上面图片中rwlock的低下的读性能由于读侧临界区size等于0(没有代码)而被夸大了,随着临界区的加大,RCU性能优势会慢慢降低,如下图所示:
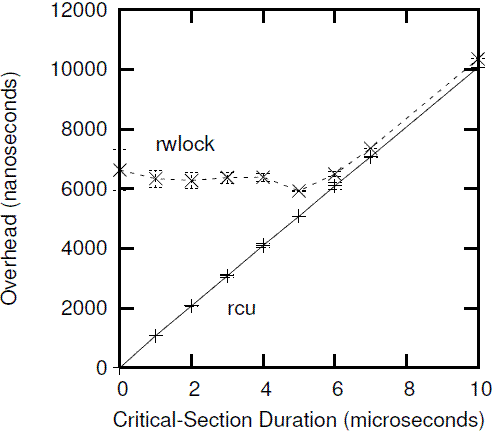
上图展示的是在16个CPU的情况下,随着读临界区的加大,rwlock和RCU的性能对比。
However, this observation must be tempered by the fact that a number of system calls (and thus any RCU read-side critical sections that they contain) can complete within a few microseconds.
In addition, as is discussed in the next section, RCU read-side primitives are almost entirely deadlock-immune.
看起来,当临界区大于5微妙的时候,RCU没有什么优势,不过要知道大部分的系统调用(该系统调用会包含RCU读侧临界区)都是在几个微秒内完成,因此,我们对上面图片的观察应该focus在左半部分。此外,就像我们下一节要讨论的,RCU的读侧的原语是不会造成死锁的。
Deadlock Immunity Although RCU offers significant performance advantages for read-mostly workloads, one of the primary reasons for creating RCU in the first place was in fact its immunity to read-side deadlocks. This immunity stems from the fact that RCU read-side primitives do not block, spin, or even do backwards branches, so that their execution time is deterministic. It is therefore impossible for them to participate in a deadlock cycle.
RCU如何避免了死锁问题:
你以为kernel hacker发明了RCU是为了提升读侧性能吗?非也,其实一个主要的目的是误了解决读侧死锁问题。之所以能做到这一点主要是因为RCU读侧的API根本不会block,也不会spin,也不会向后跳转,因此,它们的执行时间是确定的,因此,不可能会造成死锁。
An interesting consequence of RCU’s read-side deadlock immunity is that it is possible to unconditionally upgrade an RCU reader to an RCU updater. Attempting to do such an upgrade with reader-writer locking results in deadlock. A sample code fragment that does an RCU read-to-update upgrade follows:
RCU读侧临界区不会死锁的一个有趣的好处是:RCU的reader可以无条件的升级为updater。对于rwlock而言,这样的操作会导致死锁。一个简单的reader到updater升级的示例代码如下:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, &head, list_field) {
3 do_something_with(p);
4 if (need_update(p)) {
5 spin_lock(my_lock);
6 do_update(p);
7 spin_unlock(&my_lock);
8 }
9 }
10 rcu_read_unlock();
Note that do_update() is executed under the protection of the lock and under RCU read-side protection.
Another interesting consequence of RCU’s deadlock immunity is its immunity to a large class of priority inversion problems. For example, low-priority RCU readers cannot prevent a high-priority RCU updater from acquiring the update-side lock. Similarly, a low-priority RCU updater cannot prevent high-priority RCU readers from entering an RCU read-side critical section.
需要注意的是:do_update是被spin lock保护,同时也是位于RCU读侧临界区内。RCU读侧临界区不会死锁也会造成另外一个有趣的结果:可以解决一大类优先级翻转问题。例如:低优先级的RCU reader不会阻止高优先级的updater获取更新侧的锁。同样的,低优先级的RCU updater也不会阻止高优先级的reader进入读侧临界区。
Realtime Latency Because RCU read-side primitives neither spin nor block, they offer excellent realtime latencies. In addition, as noted earlier, this means that they are immune to priority inversion involving the RCU read-side primitives and locks. However, RCU is susceptible to more subtle priority-inversion scenarios, for example, a high-priority process blocked waiting for an RCU grace period to elapse can be blocked by low-priority RCU readers in -rt kernels. This can be solved by using RCU priority boosting [McK07c, GMTW08].
RCU的实时延迟:
由于RCU读侧原语既不spin也不会阻塞,因此它提供了非常好的实时延迟的特性。而且,就像上一段说的,这也意味着涉及RCU读侧的原语和锁不会存在优先级翻转问题。不过,RCU会造成更精巧的,不容易发现的优先级翻转的问题,例如:一个高优先级的线程在等待grace period过去,但是低优先级的reader在临界区内可以被抢占(在rt kernel中)从而导致其在读侧临界区内会花费较长的时间,从而阻塞了高优先级的线程的执行。解决这个问题的方法是提供RCU reader线程的优先级。
RCU Readers and Updaters Run Concurrently Because RCU readers never spin nor block, and because updaters are not subject to any sort of rollback or abort semantics, RCU readers and updaters must necessarily run concurrently. This means that RCU readers might access stale data, and might even see inconsistencies, either of which can render conversion from reader-writer locking to RCU non-trivial.
However, in a surprisingly large number of situations, inconsistencies and stale data are not problems. The classic example is the networking routing table. Because routing updates can take considerable time to reach a given system (seconds or even minutes), the system will have been sending packets the wrong way for quite some time when the update arrives milliseconds. Furthermore, because RCU updaters can make changes without waiting for RCU readers to finish, the RCU readers might well see the change more quickly than would batch-fair reader-writer-locking readers, as shown in Figure 9.26.
RCU Readers 和Updater可以并发执行:
由于RCU reader既不spin也不会block,而且updater也不会有任何的回退执行或者abort机制,因此,RCU的reader和updater一定是可以并发执行的。这也意味着reader有可能读到旧的数据,甚至有和其他reader看到数据不一致的情况发生。这些问题都会造成从rwlock转换成RCU不是一件简单的事情。
然而,很多场合下,看到旧数据或者reader之间看到数据不一致都不是什么大事,经典的例子就是网络路由表。因为路由信息的更新需要比较长的时间才能到达指定的系统(秒级甚至是几分钟),在真正更新路由之前,系统都是按照旧的路由表转发数据包。而且,由于修改路由表的update不需要等待reader就可以直接修改,实际上,RCU reader可以比batch-fair rwlock reader更快的看到更新后的结果,具体可以参考下面的图片:
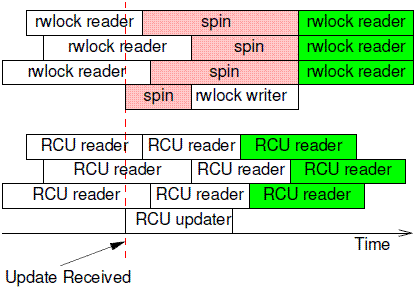
Once the update is received, the rwlock writer cannot proceed until the last reader completes, and subsequent readers cannot proceed until the writer completes. However, these subsequent readers are guaranteed to see the new value, as indicated by the green shading of the rightmost boxes. In contrast, RCU readers and updaters do not block each other, which permits the RCU readers to see the updated values sooner. Of course, because their execution overlaps that of the RCU updater, all of the RCU readers might well see updated values, including the three readers that started before the update. Nevertheless only the green-shaded rightmost RCU readers are guaranteed to see the updated values.
一旦收到update的操作,如果临界区内有reader,那么rwlock writer线程不能进入,需要等待最后一个reader离开之后才可以执行更新操作。这时候,其他的reader也不得入内,直到writer完成了更新操作。虽然这些reader无聊的在等待writer的完成,但是这种机制可以保证后续的reader都是可以看到更新之后的结果的,我们用绿色标识这些reader。与rwlock不同,RCU的reader们和updater不会互相阻塞,这样也使得RCU reader可以更快的看到更新后的结果。当然,由于各个reader们和updater在临界区内混战(对共享数据交叠进行读写操作),这些reader们或许可以看到更新后的值,但是不保证,因此,上图中,只要后面的三个reader可以看到更新后的数据,而之前的三个看到的仍然是旧数据。
Reader-writer locking and RCU simply provide different guarantees. With readerwriter locking, any reader that begins after the writer begins is guaranteed to see new values, and any reader that attempts to begin while the writer is spinning might or might not see new values, depending on the reader/writer preference of the rwlock implementation in question. In contrast, with RCU, any reader that begins after the updater completes is guaranteed to see new values, and any reader that completes after the updater begins might or might not see new values, depending on timing.
其实也没有那么神秘,rwlock和RCU只不过是提供了不同的保证。对于rwlock,在writer之后的reader可以保证看到更新后的数据,在writer之前的reader可以保证看到旧的数据。如果reader进入临界区的时候,writer已经spin,并且等待reader退出,这种reader可能看到新的数据,也可能看到旧的数据,这和rwlock的具体实现相关(看看更偏向reader还是writer)。而对于RCU而言,任何在updater完成操作之后的进入临界区的reader都保证可以看到更新后的数据,而对于那些在updater开始执行更新操作之后才离开临界区的reader,有可能看到新数据,也有可能看到旧数据,和timing相关。
The key point here is that, although reader-writer locking does indeed guarantee consistency within the confines of the computer system, there are situations where this consistency comes at the price of increased inconsistency with the outside world. In other words, reader-writer locking obtains internal consistency at the price of silently stale data with respect to the outside world.
Nevertheless, there are situations where inconsistency and stale data within the confines of the system cannot be tolerated. Fortunately, there are a number of approaches that avoid inconsistency and stale data [McK04, ACMS03], and some methods based on reference counting are discussed in Section 9.1.
理解RCU和rwlock的不同之处的关键点在于:尽管在计算机这个小系统中,rwlock确实是保证了数据的一致性,但是,代价是牺牲了整个系统的数据一致性。换句话说,rwlock获得了局部小系统内的数据一致性,不过,从整个系统的角度看,虽然数据已经更新,但是我们还是不得不默默承受旧数据。(下面是我自己的理解,仅供参考:还是以温度采集为例:如果使用rwlock,温度数据在计算机系统内部虽然是一致的,但是,整个系统包括地球表面的空气,温度采集模块、计算机系统,显示当前温度的LCD屏幕,观察温度变化的人。从整个系统角度看,虽然地球表面的空气温度发生了变化,但是由于使用了rwlock,虽然计算机系统可以保证reader thread数据一致性,但是,人通过LCD屏幕观察到的温度变化却没有及时体现出来,这样就是所谓的整个系统的数据一致性无法保证。)
不管怎样,总是有这样的应用场景:从系统的角度看,无法容忍数据不一致或者无法及时获取更新后的数据。幸运的是我们有很多方法可以解决这个问题(可以参考[McK04, ACMS03]),有些使用了9.1小节介绍的reference counting的方法。
Low-Priority RCU Readers Can Block High-Priority Reclaimers In Realtime RCU [GMTW08], SRCU [McK06], or QRCU [McK07e] (see Section 12.1.4), a preempted reader will prevent a grace period from completing, even if a high-priority task is blocked waiting for that grace period to complete. Realtime RCU can avoid this problem by substituting call_rcu() for synchronize_rcu() or by using RCU priority boosting [McK07c, GMTW08], which is still in experimental status as of early 2008. It might become necessary to augment SRCU and QRCU with priority boosting, but not before a clear real-world need is demonstrated.
优先级翻转问题:
在realtime RCU、SRCU或者QRCU中,reader的临界区可以被抢占,这也就意味着读侧的临界区会拉长,从而导致grace period变长,即便是一个高优先级的任务由于等待Grace Period而阻塞。Realtime RCU可以通过用call_rcu() 来替代synchronize_rcu() 的方法,或者通过提升RCU reader进程的优先级的方法来解决优先级翻转问题,不过,这些方法在2008年初仍然处于实验状态。在SRCU和QRCU中使用提升进程优先级的方法是需要仔细讨论的,当然,必须要明确的应用场景的需求。
RCU Grace Periods Extend for Many Milliseconds With the exception of QRCU and several of the “toy” RCU implementations described in Section 9.3.5, RCU grace periods extend for multiple milliseconds. Although there are a number of techniques to render such long delays harmless, including use of the asynchronous interfaces where available (call_rcu() and call_rcu_bh()), this situation is a major reason for the rule of thumb that RCU be used in read-mostly situations.
超长grace period的问题:
除了QRCU和9.3.5小节几个示例性的玩具RCU实现版本,其他的RCU的grace period可以长达几个毫秒。虽然有很多方法降低超长宽限期(grace period)的影响,例如:尽量使用异步的RCU api(call_rcu() 和 call_rcu_bh()),但是超长的grace period也是RCU应用于读多写少的场景的主要原因。
Comparison of Reader-Writer Locking and RCU Code In the best case, the conversion from reader-writer locking to RCU is quite simple, as shown in Figures 9.27, 9.28, and 9.29, all taken from Wikipedia [MPA+06].More-elaborate cases of replacing reader-writer locking with RCU are beyond the scope of this document.
rwlock和RCU代码对比:
理想状况下,用RCU代码rwlock非常简单,就想下面的代码示例这么简单(注:下面的代码来自wiki,更复杂的如何用RCU替换rwlock超出本文的范围):
|
1 struct el { |
1 struct el { |
上面是数据结构的对比。
|
1 int search(long key, int *result) |
1 int search(long key, int *result) |
上面是搜索函数代码的对比。
|
1 int delete(long key) |
1 int delete(long key) |
上面是删除函数代码的对比。
原创翻译文章,转发请注明出处。蜗窝科技
评论:
2016-02-26 11:27
Fortunately, the temperature and pressure are normally controlled
幸运的是温度和压力的变化缓慢
结合后面作者说可以写hard-code,这里翻译成 固定的(被程序员牢牢控制住) 会不会好一点?
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2016-02-29 08:24