
perfbook memory barrier(14.2章节)中文翻译(下)
作者:linuxer 发布于:2016-1-11 19:26 分类:内核同步机制
终于完成了perfbook中所有关于memory barrier的内容了,站在当前的时间点上,回头看看翻译perfbook之前的我,那时候是多么的幼稚, 对memory barrier理解多么肤浅。当然,也许随着时间的流逝,5年之后才回头看看今天的我,也会发现:即便是通读了perfbook的memory barrier的内容,其实仍然肤浅,仍然没有理解其精髓。究其原因,一方面,学习的过程总是螺旋式上升的,在当前的技术背景下,我只能到达目前的状 态,要进一步提高,需要在计算机体系结构、编译原理……方面有所突破。另外一方面,技术在无情的进步,如果停在原地注定是会被淘汰的。
生命不息,奋斗不止,还是要象蜗牛一样慢慢前行……
14.2.7 Abstract Memory Access Model
Consider the abstract model of the system shown in Figure 14.6.
我们可以把系统抽象成下图所示的block diagram:
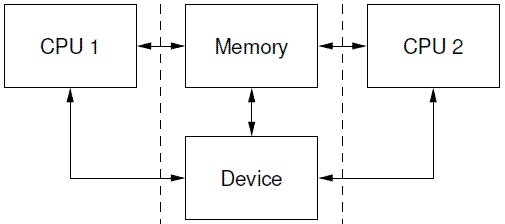
Each CPU executes a program that generates memory access operations. In the abstract CPU, memory operation ordering is very relaxed, and a CPU may actually perform the memory operations in any order it likes, provided program causality appears to be maintained. Similarly, the compiler may also arrange the instructions it emits in any order it likes, provided it doesn’t affect the apparent operation of the program.
系统中的每一个CPU都会执行程序,并根据程序逻辑产生内存访问的操作。在上图的抽象模型中,CPU和memory之间的顺序要求非常松散,只要能保证程序的因果性(causality),基本上CPU可以以任何它喜欢(CPU喜欢性能更快)的任意顺序来访问内存。同样的,只要能保证程序逻辑上的正确性,编译器也可以自由的安排汇编指令的顺序,当然,这也是为了获得更好的性能。
So in the above diagram, the effects of the memory operations performed by a CPU are perceived by the rest of the system as the operations cross the interface between the CPU and rest of the system (the dotted lines).
因此,在上面的结构图中,任何一个CPU执行的内存访问操作都会穿过连接CPU和系统的其他组件的总线(上图中的虚线),都会被系统其余的组件观察到。
For example, consider the following sequence of events given the initial values {A = 1, B = 2}:
我们举一个例子,考虑下面的操作序列,并且初始值设为{A = 1, B = 2}:
| CPU1 | CPU2 |
|
A = 3; B = 4; |
x = A; y = B; |
The set of accesses as seen by the memory system in the middle can be arranged in 24 different combinations, with loads denoted by “ld” and stores denoted by “st”:
上表中的CPU操作组合可以被上图中间部分的存储系统观察到,其结果可以有24中组合,如下(其中ld表示load,st表示store):
st A=3, st B=4, x=ld A!3, y=ld B!4
st A=3, st B=4, y=ld B!4, x=ld A!3
st A=3, x=ld A!3, st B=4, y=ld B!4
st A=3, x=ld A!3, y=ld B!2, st B=4
st A=3, y=ld B!2, st B=4, x=ld A!3
st A=3, y=ld B!2, x=ld A!3, st B=4
st B=4, st A=3, x=ld A!3, y=ld B!4
st B=4, ...
...
and can thus result in four different combinations of values:
最终导致的4种对x和y变量的赋值结果:
x == 1, y == 2
x == 1, y == 4
x == 3, y == 2
x == 3, y == 4
Furthermore, the stores committed by a CPU to the memory system may not be perceived by the loads made by another CPU in the same order as the stores were committed.
此外,需要注意的是:某个CPU的store操作未必会立刻会被其他CPU通过load观察到。
As a further example, consider this sequence of events given the initial values {A = 1, B = 2, C = 3, P = &A, Q = &C}:
再来一个例子,我们考虑下面的操作序列,初始值设置是{A = 1, B = 2, C = 3, P = &A, Q = &C}:
| CPU1 | CPU2 |
|
B = 4; P = &B; |
Q = P; D = *Q; |
There is an obvious data dependency here, as the value loaded into D depends on the address retrieved from P by CPU 2. At the end of the sequence, any of the following results are possible:
这里有一个明显的数据依赖关系:CPU2上对D对的赋值操作依赖于上一条对Q的赋值操作。当CPU执行完毕上表中的指令之后,下面任何一个结果都是有可能的:
(Q == &A) and (D == 1)
(Q == &B) and (D == 2)
(Q == &B) and (D == 4)
Note that CPU 2 will never try and load C into D because the CPU will load P into Q before issuing the load of *Q.
值得一提的是在CPU2上,永远不会取变量C的地址来完成对D的赋值,因为对于CPU2而言,它会先完成对将P赋值给Q的操作之后,再执行对D的赋值操作。
14.2.8 Device Operations
Some devices present their control interfaces as collections of memory locations, but the order in which the control registers are accessed is very important. For instance, imagine an Ethernet card with a set of internal registers that are accessed through an address port register (A) and a data port register (D). To read internal register 5, the following code might then be used:
在某些系统中,一些设备的控制接口被映射到了一组内存地址上来,通过对这组内存地址的访问可以控制设备的行为。但是这些设备相关的内存地址和普通memory不一样,需要特别注意其操作顺序。例如:一个以太网卡有若干的寄存器接口用来控制网卡的行为,而这寄存器可以通过内存地址来访问。我们假设有两个控制寄存器,分别是address port寄存器(通过A地址访问)和data port寄存器(通过D地址访问),为了访问网卡内部的5号寄存器,我们可以通过下面的方式进行:
*A = 5;
x = *D;
but this might show up as either of the following two sequences:
虽然代码如此,但是CPU有可能会打乱执行顺序,因此内存操作顺序有下面两种可能:
STORE *A = 5, x = LOAD *D
x = LOAD *D, STORE *A = 5
the second of which will almost certainly result in a malfunction, since it set the address after attempting to read the register.
毫无疑问,第二种操作序列是不对的,因为要正确的访问以太网的内部寄存器,必须首先设定号address port,然后再写入data port。
14.2.9 Guarantees
There are some minimal guarantees that may be expected of a CPU:
对于一个特定的CPU而言,它至少可以保证下面的操作顺序:
1. On any given CPU, dependent memory accesses will be issued in order, with respect to itself. This means that for:
Q = P; D = *Q;
the CPU will issue the following memory operations:
Q = LOAD P, D = LOAD *Q
and always in that order.
1、在任意一个给定的CPU上,互相依赖的内存访问一定是按照顺序进行的。也就是说,如果program order是先load变量地址,然后load该变量地址中的内容,那么对于执行该代码的CPU而言,其操作顺序必定是和program order一致的。
2. Overlapping loads and stores within a particular CPU will appear to be ordered within that CPU. This means that for:
a = *X; *X = b;
the CPU will only issue the following sequence of memory operations:
a = LOAD *X, STORE *X = b
And for:
*X = c; d = *X;
the CPU will only issue:
STORE *X = c, d = LOAD *X
(Loads and stores overlap if they are targetted at overlapping pieces of memory).
2、在任意一个给定的CPU上,有地址重叠的内存访问一定是按照顺序进行的。举一个例子:如果program order是先store A地址开始的2B memory,然后loadA地址开始4B的内容,那么对于执行该代码的CPU而言,其操作顺序必定是和program order一致的。
3. A series of stores to a single variable will appear to all CPUs to have occurred in a single order, though this order might not be predictable from the code, and in fact the order might vary from one run to another.
3、如果有一系列对某个变量的store操作,那么从所有的CPU角度来看,具体的store操作顺序应该符合一个全局的顺序,而且,这个顺序无法通过代码进行预测,而实际上,这个全局顺序并不固定,每次运行,这个全局顺序都会发生变化。
And there are a number of things that must or must not be assumed:
下面我们来看看不能保证的事情:
1. It must not be assumed that independent loads and stores will be issued in the order given. This means that for:
X = *A; Y = *B; *D = Z;
we may get any of the following sequences:
X = LOAD *A, Y = LOAD *B, STORE *D = Z
X = LOAD *A, STORE *D = Z, Y = LOAD *B
Y = LOAD *B, X = LOAD *A, STORE *D = Z
Y = LOAD *B, STORE *D = Z, X = LOAD *A
STORE *D = Z, X = LOAD *A, Y = LOAD *B
STORE *D = Z, Y = LOAD *B, X = LOAD *A
1、如果store和load操作没有任何的依赖关系,那么CPU有权利以任何的顺序来执行内存访问操作。
2. It must be assumed that overlapping memory accesses may be merged or discarded.
This means that for:
X = *A; Y = *(A + 4);
we may get any one of the following sequences:
X = LOAD *A; Y = LOAD *(A + 4);
Y = LOAD *(A + 4); X = LOAD *A;
{X, Y} = LOAD {*A, *(A + 4) };
And for:
*A = X; Y = *A;
we may get any of:
STORE *A = X; STORE *(A + 4) = Y;
STORE *(A + 4) = Y; STORE *A = X;
STORE {*A, *(A + 4) } = {X, Y};
Finally, for:
*A = X; *A = Y;
we may get either of:
STORE *A = X; STORE *A = Y;
STORE *A = Y;
2、对于有地址重复的load或者store操作,CPU有可能对多个load或者store操作进行合并,从而丢弃某些内存访问指令。
14.2.10 What Are Memory Barriers?
As can be seen above, independent memory operations are effectively performed in random order, but this can be a problem for CPU-CPU interaction and for I/O. What is required is some way of intervening to instruct the compiler and the CPU to restrict the order.
从上面文章的描述可知,互相独立的内存访问操作实际上是以随机的顺序执行的,而这样的CPU行为在I/O访问,或者有CPU-CPU互操作的时候会引入一些问题,在这种场景下,我们需要一种工具,通过这种工具我们可以限制编译器和CPU对内存访问的乱序操作。
Memory barriers are such interventions. They impose a perceived partial ordering over the memory operations on either side of the barrier.
memory barrier就象是一道篱笆,将内存访问操作分成两个部分,通过干涉编译器和CPU的行为,阻止两个部分的内存访问操作越过篱笆,产生乱序行为。
Such enforcement is important because the CPUs and other devices in a system can use a variety of tricks to improve performance - including reordering, deferral and combination of memory operations; speculative loads; speculative branch prediction and various types of caching. Memory barriers are used to override or suppress these tricks, allowing the code to sanely control the interaction of multiple CPUs and/or devices.
这种强制内存访问顺序的工具非常重要,因为系统中的CPU和其他的设备为了提高性能无所不用其极,使用的手段包括:优化内存访问顺序、推迟或者合并某些内存访问操作、speculative loads、分支预测以及各种cache。但是有些场合,例如操作IO设备的场景,需要CPU之间交互操作的场景,内存访问顺序会影响程序逻辑的正确性,因此,memory barrier就是用来对付这些优化手段的,保证内存访问顺序。
14.2.10.1 Explicit Memory Barriers
Memory barriers come in four basic varieties:
1. Write (or store) memory barriers,
2. Data dependency barriers,
3. Read (or load) memory barriers, and
4. General memory barriers.
Each variety is described below.
memory barrier的操作有下面四种基本形态,本小节的后续内容会为你一一道来。
Write Memory Barriers A write memory barrier gives a guarantee that all the STORE operations specified before the barrier will appear to happen before all the STORE operations specified after the barrier with respect to the other components of the system.
A write barrier is a partial ordering on stores only; it is not required to have any effect on loads.
A CPU can be viewed as committing a sequence of store operations to the memory system as time progresses. All stores before a write barrier will occur in the sequence before all the stores after the write barrier.
Note that write barriers should normally be paired with read or data dependency
barriers; see the “SMP barrier pairing” subsection.
Write Memory Barriers 可以约束store操作的顺序。首先要确定的一点是如何评判store操作顺序?应该是从系统中的所有的observer的角度来观察。因此,wmb实际上可以产生这样的效果:wmb将代码分成两个部分,wmb之前的store操作和wmb之后的store操作,从系统所有的observer的角度来看,看起来store的操作顺序都是这样的:即先完成了wmb之前的store操作,然后完成wmb之后的store操作。
wmb仅仅约束store的顺序,对load操作没有任何影响。
一个CPU可以被看成一个随着时间流逝,不断向内存系统提交store操作的组件,所有的store操作形成了时间轴上的序列,wmb可以保证wmb之前store操作在时间轴上先于wmb之后的store操作。
注意:wmb一般需要和rmb或者Data dependency barriers成对使用,具体参考“SMP barrier pairing”小节。
Data Dependency Barriers A data dependency barrier is a weaker form of read barrier. In the case where two loads are performed such that the second depends on the result of the first (e.g., the first load retrieves the address to which the second load will be directed), a data dependency barrier would be required to make sure that the target of the second load is updated before the address obtained by the first load is accessed.
A data dependency barrier is a partial ordering on interdependent loads only; it is not required to have any effect on stores, independent loads or overlapping loads.
As mentioned for write memory barriers, the other CPUs in the system can be viewed as committing sequences of stores to the memory system that the CPU being considered can then perceive. A data dependency barrier issued by the CPU under consideration guarantees that for any load preceding it, if that load touches one of a sequence of stores from another CPU, then by the time the barrier completes, the effects of all the stores prior to that touched by the load will be perceptible to any loads issued after the data dependency barrier.
See the “Examples of memory barrier sequences” subsection for diagrams showing the ordering constraints.
ddmb(data dependency memory barrier)是一种比rmb要弱一些的内存屏障(这里的弱是指对性能的杀伤力要弱一些)。rmb适用所有的load操作,而ddmb要求load之间有依赖关系,即第二个load操作依赖第一个load操作的执行结果(例如:先load地址,然后load该地址的内容)。ddmb被用来保证这样的操作顺序:在执行第一个load A操作的时候(A是一个地址变量),务必保证A指向的数据已经更新。只有保证了这样的操作顺序,在第二load操作的时候才能获取A地址上保存的新值。
ddmb仅仅约束有依赖关系的load的操作顺序,对于store操作、无依赖关系的load操作,有地址重合的load操作都没有任何影响。
我们在描述wmb的时候说到,系统中的其他CPU可以被看成一个随着时间流逝,不断向内存系统提交store操作的组件,而本CPU做为冷眼旁观者出现。本CPU发出data dependency barrier 可以将其执行的load操作分成两部分,data dependency barrier 之前的load操作和data dependency barrier 之后的load操作。如果data dependency barrier 之前的某个load操作(为了方便,我们称之load A)有和其他CPU上的store操作(我们称之store A)访问同一个内存地址(用程序语言就是访问同一个全局变量),关键的来了,呵呵~~,那么我们可以保证在data dependency barrier 执行完毕之后,其他CPU上的,store A之前的所有的store操作都可以被data dependency barrier 之后的load感知到。
可以参考Examples of memory barrier sequences这个小节获取关于顺序约束的图示。
Note that the first load really has to have a data dependency and not a control dependency. If the address for the second load is dependent on the first load, but the dependency is through a conditional rather than actually loading the address itself, then it’s a control dependency and a full read barrier or better is required. See the “Control dependencies” subsection for more information.
Note that data dependency barriers should normally be paired with write barriers; see the “SMP barrier pairing” subsection.
需要注意两点:
1、第一个load必须是有数据依赖关系的load,不能是控制依赖关系。如果第二个load虽然依赖第一个load的取值(获取第二个load的操作地址),但是依赖是通过条件判断而不是loading操作,那么这实际上是控制依赖关系。在这种情况下,需要适用rmb或者更强的mb来保证操作顺序。参考Control dependencies小节获取更多信息
2、ddmb一般需要和wmb成对使用,具体参考“SMP barrier pairing”小节。
Read Memory Barriers A read barrier is a data dependency barrier plus a guarantee that all the LOAD operations specified before the barrier will appear to happen before all the LOAD operations specified after the barrier with respect to the other components of the system.
A read barrier is a partial ordering on loads only; it is not required to have any effect on stores.
Read memory barriers imply data dependency barriers, and so can substitute for them.
Note that read barriers should normally be paired with write barriers; see the “SMP barrier pairing” subsection.
首先rmb能达到ddmb的顺序保证,此外,rmb还能够保证rmb之前的那些load操作看起来(被系统中的所有的observer观察)是首先完成,之后,rmb之后的load指令才执行完成。
rmb仅仅约束load的顺序,对store操作没有任何影响。rmb隐含了ddmb的功能,因此可以替代其使用。
需要注意的是:rmb一般需要和wmb成对使用,具体参考“SMP barrier pairing”小节。
General Memory Barriers A general memory barrier gives a guarantee that all the LOAD and STORE operations specified before the barrier will appear to happen before all the LOAD and STORE operations specified after the barrier with respect to the other components of the system.
A general memory barrier is a partial ordering over both loads and stores.
General memory barriers imply both read and write memory barriers, and so can substitute for either.
通用mb(或者是全功能mb)就是rmb+wmb,用来约束load和store的操作顺序。mb隐含了rmb和wmb的功能,因此,rmb或者wmb的使用场合换成mb也OK,不过可能性能会受点影响。
14.2.10.2 Implicit Memory Barriers
There are a couple of types of implicit memory barriers, so called because they are embedded into locking primitives:
1. LOCK operations and
2. UNLOCK operations.
除了显式的使用memor barrier工具,有些操作可以隐含memory barrier的功能,之所以这么说,是因为memory barrier是内嵌在内核同步原语中,主要有两种类型的操作:一是加锁操作,另外一个是释放锁的操作。
LOCK Operations A lock operation acts as a one-way permeable barrier. It guarantees that all memory operations after the LOCK operation will appear to happen after the LOCK operation with respect to the other components of the system.
Memory operations that occur before a LOCK operation may appear to happen after it completes.
A LOCK operation should almost always be paired with an UNLOCK operation.
加锁操作被认为是一种half memory barrier,加锁操作之前的内存访问可以任意渗透过加锁操作,在其他执行,但是,另外一个方向绝对是不允许的:即加锁操作之后的内存访问操作,必须在加锁操作之后完成。
lock总是和unlock成对使用。
UNLOCK Operations Unlock operations also act as a one-way permeable barrier. It guarantees that all memory operations before the UNLOCK operation will appear to happen before the UNLOCK operation with respect to the other components of the system.
Memory operations that occur after an UNLOCK operation may appear to happen before it completes.
LOCK and UNLOCK operations are guaranteed to appear with respect to each other strictly in the order specified.
The use of LOCK and UNLOCK operations generally precludes the need for other sorts of memory barrier (but note the exceptions mentioned in the subsection “MMIO write barrier”).
和lock操作一样,unlock也是half memory barrier。它确保在unlock操作之前的内存操作先于unlock操作完成,也就是说unlock之前的操作绝对不能越过unlock这个篱笆,在其后执行。当然,另外一个方向是OK的,也就是说,unlock之后的内存操作可以在unlock操作之前完成。
lock和unlock操作组合起来,确保了它们之间的内存操作不会渗透出临界区,从而确保了合理的内存访问顺序。
使用了lock和unlock操作,避免了显式的调用memory barrier原语,不过需要注意的是这里不包括对MMIO write barrier的使用。
14.2.10.3 What May Not Be Assumed About Memory Barriers?
There are certain things that memory barriers cannot guarantee outside of the confines of a given architecture:
1. There is no guarantee that any of the memory accesses specified before a memory barrier will be complete by the completion of a memory barrier instruction; the barrier can be considered to draw a line in that CPU’s access queue that accesses of the appropriate type may not cross.
当然,memory barrier也不是无所不能的,有些事情它也不能保证(主要是受限于给定的CPU体系结构):
1、假设执行代码如下:
A段内存访问代码
memory barrier指令
B段内存访问代码
由于使用了memory barrier指令,我们会保证A段内存访问代码看起来会在B段内存访问代码之前完成,也就是说,先实现A段内存访问代码,然后memory barrier指令,最后B段内存访问代码。请注意:这里使用的词汇是“看起来”,但是,实际上,memory barrier并不保证A段内存访问代码在memory barrier指令完成之前“真正的”执行完毕。由于使用了access buffer、access queue等硬件加速机制,memory barrier也可以仅仅是在这些access buffer或者access queue中画一条线,确保是A段内存访问代码先执行,然后执行B段内存访问代码就OK了。
2. There is no guarantee that issuing a memory barrier on one CPU will have any direct effect on another CPU or any other hardware in the system. The indirect effect will be the order in which the second CPU sees the effects of the first CPU’s accesses occur, but see the next point.
2、在某个CPU上(我们称之A CPU)执行的memory barrier不会对其他CPU或者系统中其他的硬件组件有任何直接的影响,只是有间接的影响。所谓间接的影响就是其他CPU观察到的A CPU上的内存访问顺序。
3. There is no guarantee that a CPU will see the correct order of effects from a second CPU’s accesses, even if the second CPU uses a memory barrier, unless the first CPU also uses a matching memory barrier (see the subsection on “SMP Barrier Pairing”).
3、我们假设在某个CPU上(我们称之A CPU)执行了memory barrier,保证了mb两段的内存访问顺序,但是,这样不能保证其他CPU能正确的观察到A CPU的操作顺序,除非观察者自己也使用了和A CPU匹配的memory barrier。可以参考SMP Barrier Pairing小节了解更多。
4. There is no guarantee that some intervening piece of off-the-CPU hardware7 will not reorder the memory accesses. CPU cache coherency mechanisms should propagate the indirect effects of a memory barrier between CPUs, but might not do so in order.
4、memory barrier不能阻止一些CPU之外的硬件block对内存访问进行重排。
14.2.10.4 Data Dependency Barriers
The usage requirements of data dependency barriers are a little subtle, and it’s not always obvious that they’re needed. To illustrate, consider the following sequence of events, with initial values {A = 1, B = 2, C = 3, P = &A, Q = &C}:
数据依赖屏障(data dependency barriers)的使用场景有些微妙,有些场合不是一眼就看出来需要数据依赖屏障。为了说明它的使用,我们一起来看下面的代码,初始值是{A = 1, B = 2, C = 3, P = &A, Q = &C}:
| CPU1 | CPU2 |
|
B = 4; Write barrier P = &B; |
Q = P; D = &Q; |
There’s a clear data dependency here, and it would seem intuitively obvious that by the end of the sequence, Q must be either &A or &B, and that:
这里有一个很明显的数据依赖关系,直觉上,当CPU执行完这些代码的时候,Q要么是&A ,要么是 &B,并且:
(Q == &A) implies (D == 1)
(Q == &B) implies (D == 4)
Counter-intuitive though it might be, it is quite possible that CPU 2’s perception of P might be updated before its perception of B, thus leading to the following situation:
会不会有违反直觉的结果出现呢?例如下面的结果:
(Q == &B) and (D == 2) ????
Whilst this may seem like a failure of coherency or causality maintenance, it isn’t, and this behaviour can be observed on certain real CPUs (such as the DEC Alpha).
看起来,这样的执行结果似乎是违反了一致性或者因果性。但是它没有并且这样的执行结果在真实的CPU上还是有可能的(例如Alpha处理器)
To deal with this, a data dependency barrier must be inserted between the address load and the data load (again with initial values of {A = 1, B = 2, C = 3, P = &A, Q = &C}):
为了解决这个问题,数据依赖屏障必须插入到加载地址和加载该地址的数据之间(初值同上):
| CPU1 | CPU2 |
|
B = 4; Write barrier P = &B; |
Q = P; data dependency barrier D = &Q; |
This enforces the occurrence of one of the two implications, and prevents the third possibility from arising.
有了这个data dependency barrier,就可以阻止那个反直觉的结果出现了。
Note that this extremely counterintuitive situation arises most easily on machines with split caches, so that, for example, one cache bank processes even-numbered cache lines and the other bank processes odd-numbered cache lines. The pointer P might be stored in an odd-numbered cache line, and the variable B might be stored in an even-numbered cache line. Then, if the even-numbered bank of the reading CPU’s cache is extremely busy while the odd-numbered bank is idle, one can see the new value of the pointer P (which is &B), but the old value of the variable B (which is 1).
需要注意的是:这个反直觉的结果的出现往往是因为CPU使用了split cache。例如,cache分成2个bank,一个负责奇数cacheline,另外一个负责偶数cacheline。P变量保存在奇数的cacheline,而B保存在偶数的cacheline,如果CPU2上,偶数bank非常繁忙,但是奇数bank非常空闲,那么CPU很有可能会看到P变量的新值(即&B),但是B值仍然是旧值“1”。
Another example of where data dependency barriers might by required is where a number is read from memory and then used to calculate the index for an array access with initial values {M[0] = 1, M[1] = 2, M[3] = 3, P = 0, Q = 3}:
另外一个数据依赖屏障的例子是数组index计算,初值是{M[0] = 1, M[1] = 2, M[3] = 3, P = 0, Q = 3}:
| CPU1 | CPU2 |
|
M[1] = 4; Write barrier P = 1; |
Q = P; data dependency barrier D = M[Q]; |
The data dependency barrier is very important to the Linux kernel’s RCU system, for example, see rcu_dereference() in include/linux/rcupdate.h. This permits the current target of an RCU’d pointer to be replaced with a new modified target,without the replacement target appearing to be incompletely initialised.
See also Section 14.2.13.1 for a larger example.
数据依赖屏障对于内核中的RCU子系统而言非常的重要,例如:include/linux/rcupdate.h文件中的rcu_dereference()接口。这个接口可以保证RCU保护的指针在更换target的时候,新的target都已经被正确的初始化了。
可以参考14.2.13.1,那里有很多的例子程序。
14.2.10.5 Control Dependencies
A control dependency requires a full read memory barrier, not simply a data dependency barrier to make it work correctly. Consider the following bit of code:
有数据依赖的场景需要数据依赖屏障来保证顺序,但是如果加入控制依赖关系,那么仅仅使用数据依赖屏障是不够的,需要一个rmb,代码如下:
1 q = &a;
2 if (p)
3 q = &b;
4 <data dependency barrier>
5 x = *q;
This will not have the desired effect because there is no actual data dependency, but rather a control dependency that the CPU may short-circuit by attempting to predict the outcome in advance. In such a case what’s actually required is:
上面的代码实际上是达不到想要的效果的,因为这不是真正的数据依赖,而是控制依赖。在这种场景下,由于CPU会进行分支预测,因此CPU会“抄近路”执行第五行的load操作,在这种情况下,需要修改代码如下:
1 q = &a;
2 if (p)
3 q = &b;
4<read barrier>
5 x = *q;
14.2.10.6 SMP Barrier Pairing
When dealing with CPU-CPU interactions, certain types of memory barrier should always be paired. A lack of appropriate pairing is almost certainly an error.
A write barrier should always be paired with a data dependency barrier or read barrier, though a general barrier would also be viable. Similarly a read barrier or a data dependency barrier should always be paired with at least an write barrier, though, again, a general barrier is viable:
当处理CPU-CPU交互场景的时候(就是不同CPU访问share memory),memory barrier总是需要成对使用的,如果缺少了适当的对端的memory barrier,往往你期待的内存顺序不能被保证。
一个wmb总是和rmb或者ddmb配对,当然通用mb也是OK的。同样的,一个rmb或者ddmb也总是需要和wmb搭配,当然,通用mb也能搭。一个使用的例子如下:
| CPU1 | CPU2 |
|
A = 1; Write barrier B = 2; |
X = B; read barrier Y = A; |
或者:
| CPU1 | CPU2 |
|
A = 1; Write barrier B = &A; |
X = B; data dependency barrier Y = *X; |
One way or another, the read barrier must always be present, even though it might be of a weaker type.
无论如何,rmb必须存在,有时候也许是一个较弱的rmb。
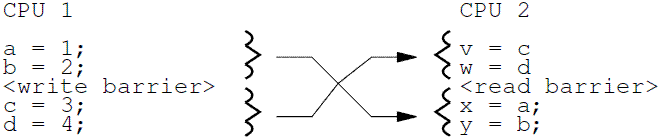
Note that the stores before the write barrier would normally be expected to match the loads after the read barrier or data dependency barrier, and vice versa:
需要注意的是:在wmb之前的store操作应该是匹配对端在rmb或者ddmb之后的load操作,反之亦然:
14.2.10.7 Examples of Memory Barrier Pairings
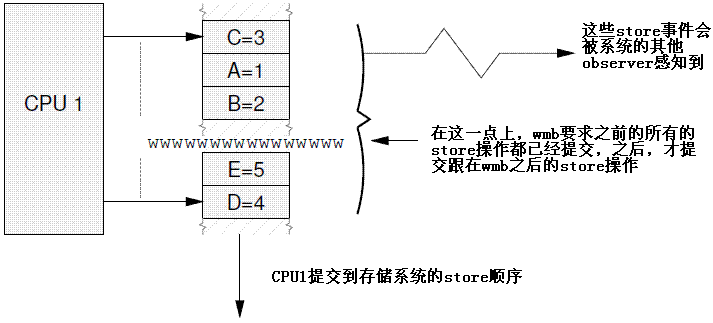
Firstly, write barriers act as a partial orderings on store operations. Consider the following sequence of events:
首先,我们来看撑起半边天的wmb,它只是约束store的顺序,考虑下面的内存访问序列:
STORE A = 1
STORE B = 2
STORE C = 3
STORE D = 4
STORE E = 5
This sequence of events is committed to the memory coherence system in an order that the rest of the system might perceive as the unordered set of {A=1,B=2,C=3} all occurring before the unordered set of {D=4,E=5}, as shown in Figure 14.7.
从系统的其他的observer(其他cpu或者DMA)来看,CPU1对wmb之前的三条store操作可以是乱序的,同理wmb之后的两个store操作顺序也可以是乱序的,不过,从整体来看,对ABC的store操作一定是首先被CPU1提交到存储系统,然后才轮到DE的store操作,具体如下图所示:
Secondly, data dependency barriers act as a partial orderings on data-dependent loads. Consider the following sequence of events with initial values {B = 7, X = 9, Y = 8, C = &Y}:
其次,我们再来看看数据依赖屏障,它对有数据依赖关系的load操作有顺序要求。我们来看看下面示例代码,初始值设定为{B = 7, X = 9, Y = 8, C = &Y}:
| CPU1 | CPU2 |
|
A = 1; B = 2; Write barrier C = &B; D = 4; |
load X; load C;---获取B的地址 load *C;---获取地址B的内容 |
Without intervention, CPU 2 may perceive the events on CPU 1 in some effectively random order, despite the write barrier issued by CPU 1, as shown in Figure 14.8.
没有memory barrier的约束,CPU2可以根据其性能要求,以任意的顺序感知CPU1上的各种store事件,这时候,尽管CPU1使用了wmb,但是仍然出现问题,具体参考下图:
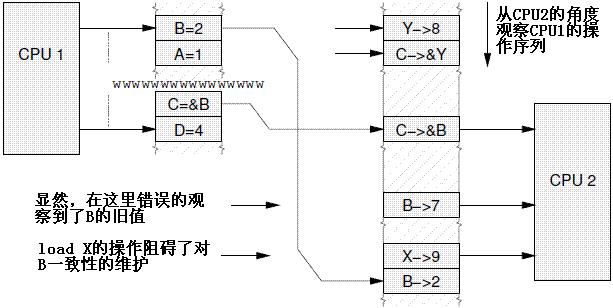
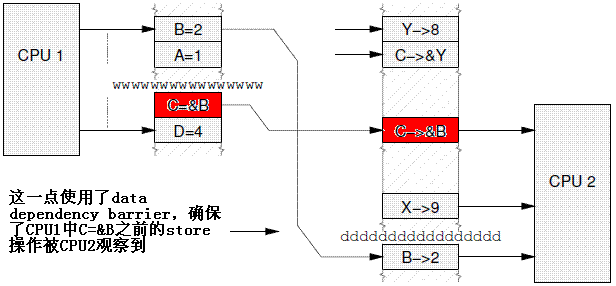
In the above example, CPU 2 perceives that B is 7, despite the load of *C (which would be B) coming after the LOAD of C. If, however, a data dependency barrier were to be placed between the load of C and the load of *C (i.e.: B) on CPU 2, again with initial values of {B = 7, X = 9, Y = 8, C = &Y}:
在上面的例子中,CPU2的确是先load C获取了B的地址,然后通过C获取了B地址的内容,但是,CPU2仍然看到B的旧值7。如果增加一个数据依赖屏障,那么情况就不一样了,代码如下:
| CPU1 | CPU2 |
|
A = 1; B = 2; Write barrier C = &B; D = 4; |
load X; load C;---获取B的地址 data dependency barrier load *C;---获取地址B的内容 |
增加了数据依赖屏障之后,程序执行结果和直觉是符合的,具体可以参考下图:
And thirdly, a read barrier acts as a partial order on loads. Consider the following sequence of events, with initial values {A = 0, B = 9}:
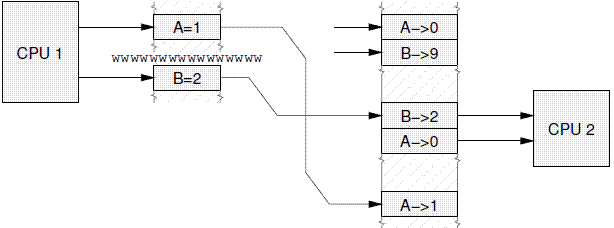
下面我们再来看看read barrier,rmb只约束load的顺序。下面是示例代码,初始值为{A = 0, B = 9}:
| CPU1 | CPU2 |
|
A = 1; Write barrier B = 2; |
load B; load A; |
Without intervention, CPU 2 may then choose to perceive the events on CPU 1 in some effectively random order, despite the write barrier issued by CPU 1, as shown in Figure 14.10.
没有memory barrier的约束,CPU2可以根据其性能要求,以任意的顺序感知CPU1上的各种store事件的结果,这时候,尽管CPU1使用了wmb,但是仍然出现问题,具体参考下图:
If, however, a read barrier were to be placed between the load of B and the load of A on CPU 2, again with initial values of {A = 0, B = 9}:
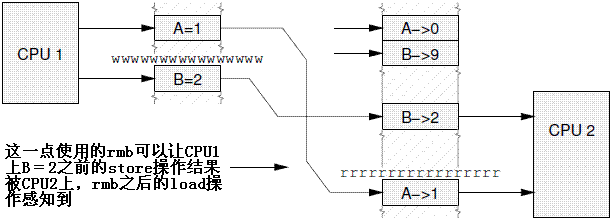
不过,如果在两个load之间增加一个rmb,那么情况可就不一样了,代码如下:
| CPU1 | CPU2 |
|
A = 1; Write barrier B = 2; |
load B; Read barrier load A; |
then the partial ordering imposed by CPU 1’s write barrier will be perceived correctly by CPU 2, as shown in Figure 14.11.
这时候,CPU1上约束了的store操作顺序,能够被CPU正确的感知到,具体可以参考下图:
To illustrate this more completely, consider what could happen if the code contained a load of A either side of the read barrier, once again with the same initial values of {A = 0, B = 9}:
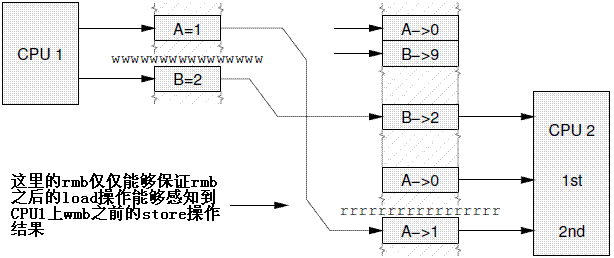
为了进一步说明rmb的功能,我们在rmb之前增加一个load A的操作,代码如下,初值仍然是{A = 0, B = 9}:
| CPU1 | CPU2 |
|
A = 1; Write barrier B = 2; |
load B; load A;---第一次 Read barrier load A;---第二次 |
Even though the two loads of A both occur after the load of B, they may both come up with different values, as shown in Figure 14.12.
尽管两个load A操作都在load B之后,但是,它们可以有不同的取值,如下图所示:
Of course, it may well be that CPU 1’s update to A becomes perceptible to CPU 2 before the read barrier completes, as shown in Figure 14.13.
The guarantee is that the second load will always come up with A == 1 if the load of B came up with B == 2. No such guarantee exists for the first load of A; that may come up with either A == 0 or A == 1.
当然,CPU2上的第一次的load A也是有可能看到CPU1对A的修改操作,但是不保证总是能够看到,等于0或者等于1都是OK的。真正能够保证的是rmb之后的第二次的load A操作,这个操作总能能够得到等于1的结果(条件是load B获得了2的结果)。
14.2.10.8 Read Memory Barriers vs. Load Speculation
Many CPUs speculate with loads: that is, they see that they will need to load an item from memory, and they find a time where they’re not using the bus for any other loads, and then do the load in advance—even though they haven’t actually got to that point in the instruction execution flow yet. Later on, this potentially permits the actual load instruction to complete immediately because the CPU already has the value on hand.
很多CPU都会对load操作进行推测性加载:也就是说,虽然还没有到达执行该load操作的那一点,但是,CPU会提前进行load的操作,因为根据程序执行流,它发现后续有可能会进行这个load 操作,而且当前又没有其他的CPU在占用总线。当的确需要执行该load操作的时候,由于CPU提前做好了工作,因此load操作可以瞬间完成。
It may turn out that the CPU didn’t actually need the value (perhaps because a branch circumvented the load) in which case it can discard the value or just cache it for later use. For example, consider the following:
当然,CPU辛辛苦苦提前执行的load操作很可能没有什么卵用(可能分支指令绕开了这个load操作),在这种情况下,从memory系统中load的值可能会被丢弃掉或者被cache起来以备不时之需。我们举个例子,代码如下:
| CPU1 | CPU2 |
|
load B divide divide load A |
On some CPUs, divide instructions can take a long time to complete, which means that CPU 2’s bus might go idle during that time. CPU 2 might therefore speculatively load A before the divides complete. In the (hopefully) unlikely event of an exception from one of the dividees, this speculative load will have been wasted, but in the (again, hopefully) common case, overlapping the load with the divides will permit the load to complete more quickly, as illustrated by Figure 14.14.
在有些处理器上,除法指令非常耗时,这也就意味着CPU2的总线会有一段不断的时间内,总线处于idle状态。这时候,CPU2会在除法指令完成之前,提前执行load A的操作。一般来说,提前进行的load A不会浪费(完成了除法操作总还是需要load A的),这大大加快这段代码的执行时间(通过同时执行divide操作和load A操作)。但是,如果在执行除法指令的时候发生了异常,提前load A这个投机行为会变得没有意义了,因此这个执行结果会被丢弃掉。具体可以参考下面的图示:

Placing a read barrier or a data dependency barrier just before the second load:
如果增加一个rmb或者ddmb的时候会怎样呢?具体入下面的代码:
| CPU1 | CPU2 |
|
load B divide divide read memory barrier load A |
will force any value speculatively obtained to be reconsidered to an extent dependent on the type of barrier used. If there was no change made to the speculated memory location, then the speculated value will just be used, as shown in Figure 14.15. On the other hand, if there was an update or invalidation to A from some other CPU, then the speculation will be cancelled and the value of A will be reloaded, as shown in Figure 14.16.
使用rmb(或者ddmb)会产生这样的效果:提前执行的load A操作获得的值会被重新考虑。如果其他CPU没有对该值进行修改,那么提前执行的load A操作获得的值最后会被采用。但是如果有其他CPU修改了该值或者invalidate该值,那么提前执行的load A操作获得的值会被丢弃,然后会reload A。
14.2.11 Locking Constraints
As noted earlier, locking primitives contain implicit memory barriers. These implicit memory barriers provide the following guarantees:
前面也提过了,加锁和释放锁的原语都隐含了memory barrier的功能。这些隐含的内存屏障操作提供了下面的保证:
1. LOCK operation guarantee:
• Memory operations issued after the LOCK will be completed after the LOCK operation has completed.
• Memory operations issued before the LOCK may be completed after the LOCK operation has completed.
1、上锁操作的保证:在上锁操作之后的那些内存操作会在上锁操作完成之后完成,在上锁操作之前的那些内存操作没有特别要求,可以在上锁操作完成之后完成,当然在上锁操作完成之前完成更加没有问题。
2. UNLOCK operation guarantee:
• Memory operations issued before the UNLOCK will be completed before the UNLOCK operation has completed.
• Memory operations issued after the UNLOCK may be completed before the UNLOCK operation has completed.
2、释放锁操作的保证:在释放锁操作之前的那些内存操作会在释放锁操作完成之前完成,在释放锁操作之后的那些内存操作没有特别要求,可以在释放锁操作完成之前完成,当然在释放锁操作完成之后完成更加没有问题。
3. LOCK vs LOCK guarantee:
• All LOCK operations issued before another LOCK operation will be completed before that LOCK operation.
3、lock和lock之间操作保证。在某个上锁操作(我们称之LOCK A)之前发出的所有的上锁操作都会在LOCK A操作之前完成。
4. LOCK vs UNLOCK guarantee:
• All LOCK operations issued before an UNLOCK operation will be completed before the UNLOCK operation.
• All UNLOCK operations issued before a LOCK operation will be completed before the LOCK operation.
4、综合上锁操作和释放操作保证。所有的在释放锁操作之前发出的上锁操作都会在该释放锁操作之前完成。所有的在上锁操作之前发出的释放锁的操作都会在该上锁操作之前完成。
5. Failed conditional LOCK guarantee:
• Certain variants of the LOCK operation may fail, either due to being unable to get the lock immediately, or due to receiving an unblocked signal or exception whilst asleep waiting for the
5、获取锁失败的时候的情况。有些锁并不保证一定成功,在某些条件下会在执行加锁操作的时候失败,失败的原因可能因为无法获得锁的资源,也可能是睡眠等待在该锁资源的时候,收到了未阻塞的信号或者异常。当上锁失败的时候,该锁操作不隐含任何的memory barrier的功能。
14.2.12 Memory-Barrier Examples
14.2.12.1 Locking Examples
LOCK Followed by UNLOCK: A LOCK followed by an UNLOCK may not be assumed to be a full memory barrier because it is possible for an access preceding the LOCK to happen after the LOCK, and an access following the UNLOCK to happen before the UNLOCK, and the two accesses can themselves then cross. For example, the following:
我们一起先来看看LOCK--->UNLOCK的场景。这种场景不是一个全功能的内存屏障场景,因为在LOCK之前的内存操作可以越过LOCK,发生在LOCK之后。而在UNLOCK之后的内存访问,也可以越过UNLOCK,并在UNLOCK之前完成。此外,这两种内存访问(指LOCK之前的内存访问和UNLOCK之后的内存访问)也可以乱序,示例代码如下:
1 *A = a;
2 LOCK
3 UNLOCK
4 *B = b;
might well execute in the following order:
上面的程序有可能按照下面的顺序执行:
2 LOCK
4 *B = b;
1 *A = a;
3 UNLOCK
Again, always remember that both LOCK and UNLOCK are permitted to let preceding operations “bleed in” to the critical section.
再强调一次,LOCK和UNLOCK隐含的memory barrier的功能只是确保临界区的内存访问不会越过LOCK和UNLOCK,逃离临界区而已。
LOCK-Based Critical Sections: Although a LOCK-UNLOCK pair does not act as a full memory barrier, these operations do affect memory ordering. Consider the following code:
锁保护的临界区:经LOCK-UNLOCK对不能实现完全的内存屏障的功能,但是,它们也的确会影响内存访问顺序,参考下面的示例代码:
1 *A = a;
2 *B = b;
3 LOCK
4 *C = c;
5 *D = d;
6 UNLOCK
7 *E = e;
8 *F = f;
This could legitimately execute in the following order, where pairs of operations on the same line indicate that the CPU executed those operations concurrently:
下面的执行顺序也是允许的。在同一行上的指令也就意味着CPU是同时并发执行这些操作
3 LOCK
1 *A = a; *F = f;
7 *E = e;
4 *C = c; *D = d;
2 *B = b;
6 UNLOCK
Ordering with Multiple Locks: Code containing multiple locks still sees ordering constraints from those locks, but one must be careful to keep track of which lock is which. For example, consider the code shown in Table 14.3, which uses a pair of locks named “M” and “Q”.
多个锁的场景:在有多个锁的场景下,内存访问的规则其实是一样的,只不过需要小心的分辨不同的锁,不要搞混了。例如下面的代码就使用了两个锁,名字分别是M和Q:
| CPU1 | CPU2 |
|
A = a; LOCK M; B = b; C = c; UNLOCK M; D = d; |
E = e; LOCK Q; F = f; G = g; UNLOCK Q; H = h; |
In this example, there are no guarantees as to what order the assignments to variables “A” through “H” will appear in, other than the constraints imposed by the locks themselves, as described in the previous section.
在这个例子中,每个锁(M和Q)提供的约束仍然是和上一段的描述一致,不过,由于是不同的锁,对A的访问和对H的访问没有任何的约束。
Ordering with Multiple CPUs on One Lock: Suppose, instead of the two different locks as shown in Table 14.3, both CPUs acquire the same lock, as shown in Table 14.4?
多个CPU对一把锁操作的场景:在上面的例子程序中,如果使用同一个锁情况会怎么样呢?程序如下:
| CPU1 | CPU2 |
|
A = a; LOCK M; B = b; C = c; UNLOCK M; D = d; |
E = e; LOCK M; F = f; G = g; UNLOCK M; H = h; |
In this case, either CPU 1 acquires M before CPU 2 does, or vice versa. In the first case, the assignments to A, B, and C must precede those to F, G, and H. On the other hand, if CPU 2 acquires the lock first, then the assignments to E, F, and G must precede those to B, C, and D.
这种情况下,或者CPU1,或者CPU2,只能有一个进入临界区,如果是CPU1进入临界区的话,对A B C的赋值操作,必然在对F G H变量赋值之前完成。如果CPU2进入临界区的话,对E F G的赋值操作,必然在对B C D变量赋值之前完成。
14.2.13 The Effects of the CPU Cache
The perceived ordering of memory operations is affected by the caches that lie between the CPUs and memory, as well as by the cache coherence protocol that maintains memory consistency and ordering. From a software viewpoint, these caches are for all intents and purposes part of memory. Memory barriers can be thought of as acting on the vertical dotted line in Figure 14.17, ensuring that the CPU presents its values to memory in the proper order, as well as ensuring that it sees changes made by other CPUs in the proper order.
CPU在感知其他CPU的store操作结果的时候其实是受到CPU和存储系统之间的cache影响的。此外,也会受到维护memory order以及memory consistency的cache一致性协议的影响。从软件的角度看,这些cache应该是属于存储系统的一部分。memory barrier主要是作用在下图的红色的垂直线上:
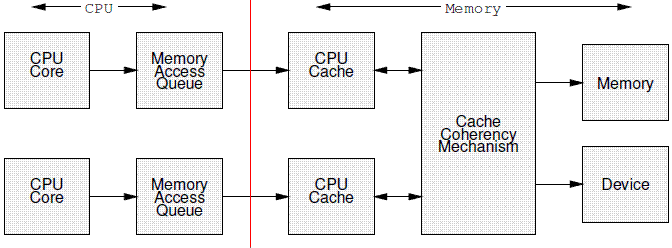
应用在上图红色线的memory barrier可以保证两个方向的内存访问顺序:一方面是保证CPU core写入存储系统的顺序,另外一方面是保证CPU core以正确的顺序感知其他CPU core的store操作。
Although the caches can “hide” a given CPU’s memory accesses from the rest of the system, the cache-coherence protocol ensures that all other CPUs see any effects of these hidden accesses, migrating and invalidating cachelines as required. Furthermore, the CPU core may execute instructions in any order, restricted only by the requirement that program causality and memory ordering appear to be maintained. Some of these instructions may generate memory accesses that must be queued in the CPU’s memory access queue, but execution may nonetheless continue until the CPU either fills up its internal resources or until it must wait for some queued memory access to complete.
对于系统的其他组件而言,尽管cache可以隐藏给定CPU的内存访问操作,但是cache coherence协议可以保证系统中所有的CPU可以看到那些被隐藏的内存操作的结果(有些cacheline会从一个cpu的local cache迁移到另外cpu的local cache,也有可能是针对某些cacheline的invalidate操作)。此外,在保证程序因果性以及内存访问顺序(这里应该说的是以自己的视角的memory order)的情况下,CPU core可以以任意顺序执行指令。因此,对于CPU core而言,有些内存访问的指令会被放入到Memory Access Queue中,这时候CPU core并不会停下脚步,而是继续执行其他指令,直到其内部资源占用完毕,或者需要等待一些放入memory access queue中的内存访问指令的结果的时候,CPU core才会停下来。
14.2.13.1 Cache Coherency
Although cache-coherence protocols guarantee that a given CPU sees its own accesses in order, and that all CPUs agree on the order of modifications to a single variable contained within a single cache line, there is no guarantee that modifications to different variables will be seen in the same order by all CPUs—although some computer systems do make some such guarantees, portable software cannot rely on them.
尽管cache-coherence协议保证了给定的CPU看到的自己的内存访问操作是顺序进行的,并且,如果某个CPU对一个共享变量(该变量在一个cacheline内)进行的一系列的修改,那么cache-coherence协议也保证了其他的CPUs所看到的修改序列也是一致的。不过,如果是对不同变量的修改序列,那么cache-coherence协议是不能保证其他的CPUs看到的是一致的顺序。尽管有些CPU会保证这一点,但是如果想写移植性好的软件,我们不能依赖这样的硬件特性。
To see why reordering can occur, consider the two-CPU system shown in Figure 14.18, in which each CPU has a split cache. This system has the following properties:
我们用一个实际的例子来看看为何会发生乱序,具体的系统是一个2个cpu core的系统,每个CPU core的cache都有两个bank,如下图所示:

1. An odd-numbered cache line may be in cache A, cache C, in memory, or some combination of the above.
2. An even-numbered cache line may be in cache B, cache D, in memory, or some combination of the above.
3. While the CPU core is interrogating one of its caches, its other cache is not necessarily quiescent. This other cache may instead be responding to an invalidation request, writing back a dirty cache line, processing elements in the CPU’s memory-access queue, and so on.
4. Each cache has queues of operations that need to be applied to that cache in order to maintain the required coherence and ordering properties.
5. These queues are not necessarily flushed by loads from or stores to cache lines affected by entries in those queues.
上图的系统有下面的特点:
1、奇数的cacheline可能在cache A或者CacheC,也可能在主存中,或者是上述的组合
2、偶数的cacheline可能在cache B或者CacheD,也可能在主存中,或者是上述的组合
3、当CPU在操作其中一个cache bank的时候,并不意味着另外一个cache bank处于静默状态,这个cache可以回应invalidation request,可以将dirty cache line写回到memory中,处理该CPU的memory access queue中的内存访问等等
4、为了维护一致性和内存访问顺序,每一个cache bank都队列,这个队列可以缓存需要该cache bank处理的操作。
5、如果load或者store涉及队列中的内存操作条目,那么在将该操作放入队列中的时候,不会flush这个队列中现存的内存操作条目。
In short, if cache A is busy, but cache B is idle, then CPU 1’s stores to odd-numbered cache lines may be delayed compared to CPU 2’s stores to even-numbered cache lines. In not-so-extreme cases, CPU 2 may see CPU 1’s operations out of order. Much more detail on memory ordering in hardware and software may be found in Appendix C.
简单的说,如果cache A处于忙状态,但是B是idle的,那么相对于CPU2上对偶数cacheline的操作而言,CPU1对奇数cacheline的store操作会delay,即使在不是那么极端的场景下,CPU2也可以看到CPU1的操作是乱序的。更详细的信息可以参考附录C。
14.2.14 Where Are Memory Barriers Needed?
Memory barriers are only required where there’s a possibility of interaction between two CPUs or between a CPU and a device. If it can be guaranteed that there won’t be any such interaction in any particular piece of code, then memory barriers are unnecessary in that piece of code.
内存屏障仅仅用于CPU-CPU之间有互操作或者CPU和device的操作场景,如果你确认你的代码中不会有这样的场景,那么其实是不必要使用内存屏障的。
Note that these are the minimum guarantees. Different architectures may give more substantial guarantees, as discussed in Appendix C, but they may not be relied upon outside of code specifically designed to run only on the corresponding architecture.
需要仔细体会memory barrier最低能保证的内存访问顺序。不同的cpu体系结构可能会有不同的保证(附录C中有讨论),但是,要知道,我们应该尽量撰写可移植性强代码,而不是for特定平台的代码。
However, primitives that implement atomic operations, such as locking primitives and atomic data-structure manipulation and traversal primitives, will normally include any needed memory barriers in their definitions. However, there are some exceptions, such as atomic_inc() in the Linux kernel, so be sure to review the documentation, and, if possible, the actual implementations, for your software environment.
还有一点要注意,一般而言,实现原子操作的原语,例如加锁原语,原子性的数据结构的操作,以及遍历原语,这些原语都会包含它需要的内存屏障的功能,然而,也有一些例外,例如linux kernel中atomic_inc()。因此,记住要去看看文档,如果确实有必要,可以考虑去看看实际的代码实现。
One final word of advice: use of raw memory-barrier primitives should be a last resort. It is almost always better to use an existing primitive that takes care of memory barriers.
最后一点建议:能不直接调用内存屏障原语就不调用,最好使用类似互斥原语这样的隐含了memory barrier功能的原语,如果确实需要,才考虑直接使用内存屏障原语。
原创翻译文章,转发请注明出处。蜗窝科技
评论:
2016-11-01 18:30
前后的代码是一样的。我猜上面的代码在q = &b之前是read dependency barrier,下面的代码在q = &b之前是read barrier吧?
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2017-12-11 17:09
preempt_disable 里面为什么仅仅用了编译器优化屏障呢?
CPU乱序也会造成在不可抢占区间内的指令提前到 preempt_disable 指令之上啊