
CFS任务的负载均衡(load balance)
作者:OPPO内核团队 发布于:2021-11-22 20:49 分类:进程管理
前言
我们描述CFS任务负载均衡的系列文章一共三篇,第一篇是框架部分,第二篇描述了task placement和active upmigration两个典型的负载均衡场景。本文是第三篇,主要是分析各种负载均衡的触发和具体的均衡逻辑过程。
本文出现的内核代码来自Linux5.10.61,为了减少篇幅,我们尽量删除不相关代码,如果有兴趣,读者可以配合代码阅读本文。
一、几种负载均衡的概述
整个Linux的负载均衡器有下面的几个类型:
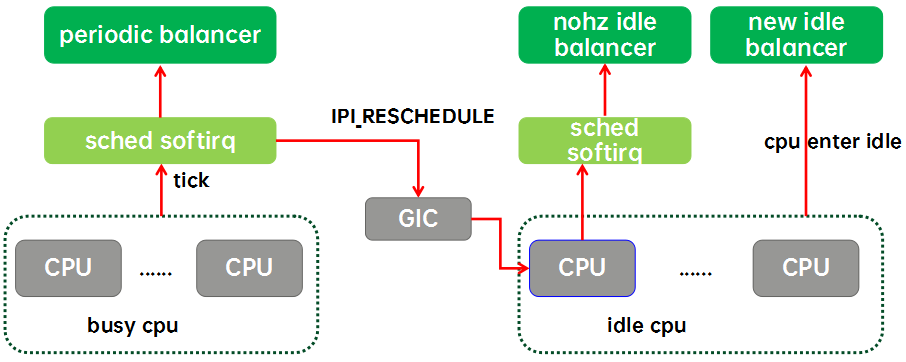
实际上内核的负载均衡器(本文都是特指CFS任务的)有两种,一种是为繁忙CPU们准备的periodic balancer,用于CFS任务在busy cpu上的均衡。还有一种是为idle cpu们准备的idle balancer,用于把繁忙CPU上的任务均衡到idle cpu上来。idle balancer有两种,一种是nohz idle balancer,另外一种是new idle balancer。
周期性负载均衡(periodic load balance或者tick load balance)是指在tick中,周期性的检测系统的负载均衡状况。周期性负载均衡是一个自底向上的均衡过程。即从该CPU对应的base sched domain开始,向上直到顶层sched domain,在各个level的domain上进行负载均衡。具体在某个特定的domain上进行负载均衡是比较简单,找到domain中负载最重的group和CPU,将其上的runnable任务拉到本CPU以便让该domain上各个group的负载处于均衡的状态。由于Linux上的负载均衡仅支持任务拉取,周期性负载均衡只能在busy cpu之间均衡,不能把任务push到其他空闲CPU上,要想让系统中的idle cpu“燥起来”就需要借助idle load balance。
NOHZ load balance是指其他的cpu已经进入idle(错过new idle balance),本CPU任务太重,需要通过ipi将其他idle的CPUs唤醒来进行负载均衡。为什么叫NOHZ load balance呢?那是因为这个balancer只有在内核配置了NOHZ(即tickless mode)下才会生效。如果CPU进入idle之后仍然有周期性的tick,那么通过tick load balance就能完成负载均衡了,不需要IPI来唤醒idle的cpu。和周期性均衡一样,NOHZ idle load balance也是通过busy cpu上tick驱动的,如果需要kick idle load balancer,那么就会通过GIC发送一个ipi中断给选中的idle cpu,让它代表系统所有的idle cpu们进行负载均衡。NOHZ load balance具体均衡的方式和tick balance类似,也是自底向上,在整个sched domain hierarchy进行均衡的过程,不同的是NOHZ load balance会在多个CPU上执行这个均衡过程。
New idle load balance比较好理解,就是在CPU上没有任务执行,马上要进入idle状态的时候,看看其他CPU是否需要帮忙,如果有需要便从busy cpu上拉任务,让整个系统的负载处于均衡状态。NOHZ load balance涉及系统中所有的idle cpu,但New idle load balance只是和即将进入idle的本CPU相关。
二、周期性负载均衡
1、触发
当tick到来的时候,在scheduler_tick函数中会调用trigger_load_balance来触发周期性负载均衡,相关的代码如下:
|
// Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing. void trigger_load_balance(struct rq *rq) { if (time_after_eq(jiffies, rq->next_balance)) raise_softirq(SCHED_SOFTIRQ);-----触发periodic balance nohz_balancer_kick(rq);-----触发nohz idle balance } |
整个代码非常的简单,主要的逻辑就是调用raise_softirq触发SCHED_SOFTIRQ,当然要满足均衡间隔时间的要求。nohz_balancer_kick用来触发nohz idle balance的,这是后面章节要仔细描述的内容。上面的代码片段,我特地保留了函数的注释,这里看起似乎注释不对,因为这个函数不但触发的周期性均衡,也触发了nohz idle balance。然而,其实nohz idle balance本质上也是另外一种意义上的周期性负载均衡,只是因为CPU进入idle,无法产生tick,因此让能产生tick的busy CPU来帮忙触发tick balance。而实际上tick balance和nohz idle balance都是通过SCHED_SOFTIRQ的软中断来处理,最后都是执行run_rebalance_domains这个函数,也就是说着两种均衡本质都是一样的。
另外,从上面的代码也可以看出,周期性均衡的触发是受控的,并非在每次tick中都会触发周期性均衡。在均衡过程中,我们会跟踪各个层级上sched domain的下次均衡时间点,并用rq->next_balance记录最近的均衡时间点,从而控制了周期性均衡的频次。Nohz idle balance也会控制均衡的触发次数,具体下一章节描述。
2、均衡处理
SCHED_SOFTIRQ类型的软中断处理函数是run_rebalance_domains,代码逻辑如下:
|
if (nohz_idle_balance(this_rq, idle))------nohz idle balance return; update_blocked_averages(this_rq->cpu); rebalance_domains(this_rq, idle);-----周期性均衡 |
nohz idle balance和periodic load balance都是通过SCHED_SOFTIRQ类型的软中断来完成,也就是说它们两个都是通过SCHED_SOFTIRQ注册的handler函数run_rebalance_domains来完成其功能的,这时候就有一个先后顺序的问题了,哪一个先执行?从上面的代码可见调度器优先处理nohz idle balance,毕竟nohz idle balance是一个全局的事情(代表系统所有idle cpu做均衡),而periodic load balance只是均衡自己的各阶sched domain。如果先执行this cpu的均衡,那么在执行rebalance_domains有可能拉取负载到this cpu,这会导致在执行nohz_idle_balance的时候会忽略其他idle cpu而直接退出(nohz idle balance要求选中的cpu是idle的)。如果成功进行了nohz idle balance,那么就没有必要进行周期性均衡了。
周期性负载均衡的主要代码逻辑在rebalance_domains函数中(也是nohz idle balance的主入口函数),如下:
|
for_each_domain(cpu, sd) { if (time_after(jiffies, sd->next_decay_max_lb_cost)) {-------A sd->max_newidle_lb_cost = (sd->max_newidle_lb_cost * 253) / 256; sd->next_decay_max_lb_cost = jiffies + HZ; need_decay = 1; } max_cost += sd->max_newidle_lb_cost; if (!continue_balancing) {--------------------B if (need_decay) continue; break; } interval = get_sd_balance_interval(sd, busy); if (time_after_eq(jiffies, sd->last_balance + interval)) {-------------C if (load_balance(cpu, rq, sd, idle, &continue_balancing)) { idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE; busy = idle != CPU_IDLE && !sched_idle_cpu(cpu); } sd->last_balance = jiffies; interval = get_sd_balance_interval(sd, busy); } out: if (time_after(next_balance, sd->last_balance + interval)) {------D next_balance = sd->last_balance + interval; update_next_balance = 1; } } |
A、max_newidle_lb_cost是sched domain上的最大newidle load balance的开销。这个开销会随着时间进行衰减,每1秒衰减1%。此外,这里还汇聚了各个sched domain上的max_newidle_lb_cost,赋值给rq->max_idle_balance_cost,用来控制new idle balance的深度。具体细节后面会详细描述。
B、这里的循环控制是从base domain直到顶层domain,但是实际上,越是上层的sched domain,其覆盖的cpu就越多,如果每一个CPU的周期性负载均衡都对高层domain进行均衡那么高层domain被撸的遍数也太多了,所以这里通过continue_balancing控制均衡的level。这里还有一个特殊场景:需要更新runqueue的max_idle_balance_cost(need_decay等于true)的时候,这个场景仍然需要遍历各个domain,但是仅仅是更新new idle balance开销(把各个层级衰减的max_newidle_lb_cost体现到rq的max_idle_balance_cost)。
C、在满足该sched domain负载均衡间隔的情况下,调用load_balance在指定的domain进行负载均衡。如果load_balance的确完成了某些任务搬移,那么需要更新this cpu的busy状态。这里并不能直接确定this cpu的繁忙状态,因为load_balance可能会修改dst cpu,从而导致任务搬移并非总是拉任务到本CPU。CPU繁忙状态的变更也导致我们需要重新调用get_sd_balance_interval获取
D、每个level的sched domain都会计算下一次均衡的时间点,这里记录最近的那个均衡时间点(倾向性能,尽快进行均衡),并在后面赋值给rq->next_balance。这样,在下次tick中,我们通过rq->next_balance来判断是否需要触发周期性负载均衡(trigger_load_balance),从而降低均衡次数,避免不必要均衡带来的开销。Nohz idle balance稍微复杂一些,因此还要考虑更新blocked load的场景。具体下一章描述。
rebalance_domains第二段代码主要内容是把各个层级sched domain上的变化传递到runqueue上去的,具体如下:
|
if (need_decay) {--------------------------------------A rq->max_idle_balance_cost = max((u64)sysctl_sched_migration_cost, max_cost); } if (likely(update_next_balance)) {----------------B rq->next_balance = next_balance; if ((idle == CPU_IDLE) && time_after(nohz.next_balance, rq->next_balance)) nohz.next_balance = rq->next_balance;--------C } |
A、如果该cpu的任何一个level的domain衰减了idle balance cost,那么就需要更新到rq->max_idle_balance_cost,该值是汇聚了各个level的domain的new idle balance的最大开销。
B、rq->next_balance是综合考虑各个level上domain的下次均衡点最近的那个时间点,在这里完成更新。
C、如果本CPU处于idle状态,那么有可能还需要更新到nohz.next_balance,用于触发nohz idle balance,是否更新主要是看是否该cpu下次均衡时间点距离当前时间点更近。
3、Sched domain的均衡间隔控制
负载均衡执行的频次其实是在延迟和开销之间进行平衡。不同level的sched domain上负载均衡带来的开销是不一样的。在手机平台上,MC domain在inter-cluster之内进行均衡,对性能的影响小一点。但是DIE domain上的均衡需要在cluster之间迁移任务,对性能和功耗的影响都比较大一些(例如cache命中率,或者一个任务迁移到原来深度睡眠的大核CPU)。因此执行均衡的时间间隔应该是和domain的层级相关的。此外,负载状况也会影响均衡的时间间隔,在各个CPU负载比较重的时候,均衡的时间间隔可以拉大,毕竟大家都忙,让子弹先飞一会,等尘埃落定之后在执行均衡也不迟。
struct sched_domain中和均衡间隔控制相关的数据成员包括:
|
成员 |
描述 |
|
last_balance |
最近在该sched domain上执行均衡操作的时间点。判断sched domain是否需要进行均衡的标准是对比当前jiffies值和last_balance+interval 这里的interval是get_sd_balance_interval实时获取的 |
|
min_interval max_interval |
做均衡也是需要开销的,我们不能时刻去检查调度域的均衡状态,这两个参数定义了检查该sched domain均衡状态的时间间隔的范围。min_interval缺省设定为sd weight,即sched domain内CPU的个数。max_interval等于2倍的min_interval。 |
|
balance_interval |
定义了该sched domain均衡的基础时间间隔,一方面,该值和sched domain所处的层级有关,层级越高,覆盖的CPU越多,balance_interval越大。另外一方面,在调用load_balance的时候,会根据实际的均衡情况对其进行加倍或者保持原值。 |
|
busy_factor |
正常情况下,balance_interval定义了均衡的时间间隔,如果cpu繁忙,那么均衡要时间间隔长一些,即时间间隔定义为busy_factor x balance_interval。缺省值是32。 |
具体控制均衡间隔的函数是get_sd_balance_interval,代码如下:
|
unsigned long interval = sd->balance_interval;-----------------A if (cpu_busy)------------------------B interval *= sd->busy_factor; interval = msecs_to_jiffies(interval); if (cpu_busy)-----------------------C interval -= 1; interval = clamp(interval, 1UL, max_load_balance_interval); |
A、sd->balance_interval是均衡间隔的基础值。balance_interval是一个不断跟随sched domain的不均衡程度而变化的值。初值一般从min_interval开始,如果sched domain仍然处于不均衡状态,那么sd->balance_interval保持min_interval,随着不均衡的状况在变好,无任务可以搬移,需要通过主动迁移来完成均衡,这时候balance_interval会逐渐变大,从而让均衡的间隔变大,直到max_interval。对于一个4+4的手机平台,在MC domain上,小核和大核cluster的min_interval都是4ms,而max_interval等于8ms。而在DIE domain层级上,由于CPU个数是8,其min_interval是8ms,而max_interval等于16ms。
B、由于各个cpu上的tick大约是同步到来,因此自下而上的周期性均衡在各个CPU上几乎是同时触发。如果sched domain覆盖更多的cpu,那么它的均衡由于要收集更多的信息而会稍稍慢一些。这样就会产生这样的一种现象:低阶的sched domain刚刚完成迁移的任务就会被高阶的sched domain选中被拉到其他CPU上去。为了降低这种低阶和高阶domain的均衡同步效应,调频间隔减去一,使得高阶sched domain和低阶sched domain的interval不是整数倍数的关系。此外,调频间隔最大也不能超过100ms。
最后强调一下,这一小节的内容适用于periodic balance和nozh idle balance。
三、nohz idle balance
1、Nohz idle均衡的触发条件
nohz idle均衡的触发上一章已经描述了部分过程:scheduler_tick函数中调用trigger_load_balance函数,最终通过nohz_balancer_kick函数来触发,具体代码逻辑如下:
|
if (unlikely(rq->idle_balance))----------------------A return; nohz_balance_exit_idle(rq);------------------------B if (likely(!atomic_read(&nohz.nr_cpus)))---------C return; if (READ_ONCE(nohz.has_blocked) && time_after(now, READ_ONCE(nohz.next_blocked))) flags = NOHZ_STATS_KICK;------------------D if (time_before(now, nohz.next_balance))-----------E goto out; |
A、nohz idle balance是本cpu繁忙,需求其他idle cpu来协助,这里如果本CPU也是空闲的,那么也就没有必要触发nohz idle balance了。
B、当CPU从idle状态醒来,第一个tick会更新全局变量nohz的状态以及sched domain的cpu busy状态。虽然nohz idle balance本质上是tick balance,但是它会发IPI,会唤醒idle的cpu,带来额外的开销,所以还是要控制触发nohz idle balance的频次。为了方便控制触发nohz idle balance,调度器定义了一个nohz的全局变量,其数据结构如下:
|
成员 |
描述 |
|
idle_cpus_mask |
统中哪些cpu进入了idle状态 |
|
nr_cpus |
多少个cpu进入了idle状态 |
|
has_blocked |
这些idle的CPUs是否需要更新blocked load |
|
next_balance |
下一次触发nohz idle balance的时间 |
|
next_blocked |
下一次更新blocked load的时间点 |
在nohz_balance_exit_idle函数中,我们会更新nr_cpus和idle_cpus_mask这两个成员。
C、nr_cpus和idle_cpus_mask这两个成员可以让调度器了解当前系统idle CPU的情况,从而选择合适的CPU来执行nohz idle balance。如果系统中根本没有idle cpu,那么也就没有必要触发nohz idle load balance了。
D、nohz idle balance有两部分的功能:(1)更新idle cpu上的blocked load(2)负载均衡。可以只更新blocked load,但是负载均衡必须要包括更新blocked load功能。如果当前idle的cpu上有需要衰减的负载,那么标记之。负载更新不是本文的内容,不再详述。
E、next_balance是用来控制触发nohz idle balance的时间点,这个时间点应该是和系统中所有idle cpu的rq->next_balance相关的,也就是说,如果系统中所有idle cpu都还没有到达均衡时间点,那么根本也就没有必要触发nohz idle balance。在执行nohz idle balance的时候,调度器实际上会遍历idle cpu找到rq->next_balance最小的(即最近需要均衡的)赋值给nohz.next_balance,这个值作为触发nohz idle balance的时间点。
上面是一些基本条件的判断,下面会根据cpu runqueue的任务情况进行判定:
|
if (rq->nr_running >= 2) {---------------------------A flags = NOHZ_KICK_MASK; goto out; } sd = rcu_dereference(rq->sd);-------------------B if (sd) { if (rq->cfs.h_nr_running >= 1 && check_cpu_capacity(rq, sd)) { flags = NOHZ_KICK_MASK; goto unlock; } } sd = rcu_dereference(per_cpu(sd_asym_cpucapacity, cpu)); if (sd) { if (check_misfit_status(rq, sd)) {------------------C flags = NOHZ_KICK_MASK; goto unlock; } goto unlock;----------------------D } sds = rcu_dereference(per_cpu(sd_llc_shared, cpu)); if (sds) { nr_busy = atomic_read(&sds->nr_busy_cpus);-------------E if (nr_busy > 1) { flags = NOHZ_KICK_MASK; goto unlock; } } |
A、要触发nohz idle balance之前,需要保证自己有可以被拉取的任务。本cpu runqueue上如果有大于等于2个以上的任务,那么就基本确定可以发起nohz idle balance了
B、虽然本cpu runqueue上只有1个cfs任务,但是这个CPU用于cfs任务的算力已经已经衰减到一定程度了(由于rt任务或者irq等的影响),这时候也需要发起nohz idle balance
C、在异构系统中,我们还需要考虑misfit task。当本CPU上有misfit task,即便只有一个任务也是需要发起nohz idle balance
D、对于异构系统,我们忽略了LLC check,这是因为功耗的考量。小核cluster有busy的CPU并不说明需要进行均衡,只要小核CPU有足够的算力能够容纳当前运行的任务,那么没有必要发起nohz idle balance把大核给搞起来,增加额外的功耗。
E、在同构系统中,我们还是期望负载能够在各个LLC domain上进行均衡(毕竟可以增加整个系统的cache使用率),同时,我们也希望在LLC domain内部的CPU上能够任务均布。不过我们也不知道其他LLC domain的情况,因此只要有2个及以上的CPU处于busy,那么就发起nohz idle balance。
一旦确定要进行nohz idle balance,我们就会调用kick_ilb函数来选择一个适合的CPU作为代表,来进行负载均衡。
2、选择哪一个CPU?
kick_ilb函数代码逻辑大致如下:
|
if (flags & NOHZ_BALANCE_KICK) nohz.next_balance = jiffies+1;------------------A ilb_cpu = find_new_ilb();----------------------B if (ilb_cpu >= nr_cpu_ids) return; flags = atomic_fetch_or(flags, nohz_flags(ilb_cpu));--------C if (flags & NOHZ_KICK_MASK) return; smp_call_function_single_async(ilb_cpu, &cpu_rq(ilb_cpu)->nohz_csd);--------D |
A、如果是需要做均衡(而不是仅仅更新负载),那么我们需要更新nohz.next_balance到下一个jiffies。更新之后,其他的CPU的tick(同一个jiffies)将不会再触发nohz balance的检查。如果nohz idle balance顺利完成,那么nohz.next_balance会响应的进行更新,如果nohz idle balance被中断(参考下一节_nohz_idle_balance函数中的B段代码),那么这里可以确保在下一个tick可以继续完成之前未完的nohz idle balance。
B、如果不考虑功耗,那么从所有的idle cpu中选择一个就OK了,然而,在异构系统中(例如手机环境),我们要考虑更多。例如:如果大核CPU和小核CPU都处于idle状态,那么选择唤醒大核CPU还是小核CPU?大核CPU虽然算力强,但是功耗高。如果选择小核,虽然能省功耗,但是提供的算力是否足够。此外,发起idle balance请求的CPU在那个cluster?是否首选同一个cluster的cpu来执行nohz idle balance?还有cpu idle的深度如何?很多思考点,不过本文就不详述了,毕竟标准内核选择的最简单的算法:选择nohz全局变量idle cpu mask中的第一个。
C、确保选择的cpu没有正在进行nohz idle load balance,如果有pending的请求,那么不需要重复发生IPI,触发nohz idle balance。
D、我们定义发起nohz idle balance的CPU叫做kicker;接收请求来执行均衡操作的CPU叫做kickee。Kicker和kickee之间的交互是这样的:
a) Kicker通知kickee已经被选中执行nohz idle balance,具体是通过设定kickee cpu runqueue的nohz_flags成员来完成的。
b) Send ipi把kickee唤醒
c) Kickee被中断唤醒,执行scheduler_ipi来处理这个ipi中断。当发现其runqueue的nohz_flags成员被设定了,那么知道自己被选中,后续的流程其实和周期性均衡一样的,都是触发一次SCHED_SOFTIRQ类型的软中断。
我们再强调一下:被kick的那个idle cpu并不是负责拉其他繁忙cpu上的任务到本CPU上就完事了,kickee是为了重新均衡所有idle cpu(tick被停掉)的负载,也就是说被选中的idle cpu仅仅是一个系统所有idle cpu的代表,它被唤醒是要把系统中繁忙CPU的任务均衡到系统中所有的idle cpu们。
3、均衡处理
和tick balance一样,nohz idle balance的SCHED_SOFTIRQ软中断的处理函数run_rebalance_domains,只不过在这里调用nohz_idle_balance函数完成均衡。具体执行nohz idle balance非常简单,遍历系统所有的idle cpu,调用rebalance_domains来完成该cpu上的各个level的sched domain的负载均衡。
均衡处理大部分在_nohz_idle_balance函数中完成,我们重点看看这个函数的代码逻辑:
|
WRITE_ONCE(nohz.has_blocked, 0);------------------# for_each_cpu(balance_cpu, nohz.idle_cpus_mask) { if (balance_cpu == this_cpu || !idle_cpu(balance_cpu)) continue;-----------------A if (need_resched()) {------------------B has_blocked_load = true; goto abort; } rq = cpu_rq(balance_cpu); has_blocked_load |= update_nohz_stats(rq, true);---------C if (time_after_eq(jiffies, rq->next_balance)) {----------D if (flags & NOHZ_BALANCE_KICK) rebalance_domains(rq, CPU_IDLE); } if (time_after(next_balance, rq->next_balance)) {-----------E next_balance = rq->next_balance; update_next_balance = 1; } } |
A、暂时略过本cpu的均衡处理,完成其他idle CPU遍历后会立刻对当前CPU进行均衡。此外,如果CPU已经不处于idle状态了,那么也就没有必要进行均衡了。
B、如果本CPU已经有了任务要做,那么需要放弃本次负载均衡,尽快执行自己队列上的任务,否则其队列上的任务会有较长的调度时延,毕竟也许后面有若干个idle cpu的各个level的sched domain需要进行均衡,都是比较耗时的操作。由于终止了nohz idle balance,那么有些idle cpu的blocked load没有更新,我们在遍历之前就已经假设会完成所有的均衡,因此设定了系统没有blocked load需要更新(代码#处)。在nohz idle balance半途而废,只能重新标记系统仍然有blocked load要更新。
C、对该idle cpu进行blocked load的更新
D、如果达到均衡的时间间隔的要求,那么调用rebalance_domains进行具体的负载均衡
E、rebalance_domains中会根据情况修改rq->next_balance,因此这里需要跟踪各个IDLE cpu上最近时间点的那个next_balance,后面会更新到nohz.next_balance,以便控制系统触发nohz idle balance的频次。
_nohz_idle_balance第二段的代码主要是处理本CPU(即被选中的idle cpu代表)的均衡,比较简单,不再赘述。
四、new idle load balance
1、均衡触发
Newidle balance的主入口函数是newidle_balance,我们分段解读其逻辑:
|
if (this_rq->avg_idle < sysctl_sched_migration_cost ||--------------A !READ_ONCE(this_rq->rd->overload)) {---------------------------B sd = rcu_dereference_check_sched_domain(this_rq->sd); if (sd) update_next_balance(sd, &next_balance);---------------C nohz_newidle_balance(this_rq);--------------------------------D goto out; } |
A、当CPU马上进入idle状态的时候是否要做new idle load balance主要考虑两个因素:一个是当前cpu的cache状态,另外一个就是当前的整机负载情况。如果该CPU平均idle时间非常短,那么当CPU重新回来执行的任务的时候,CPU cache还是热的,如果从其他CPU上拉取任务,那么这些新的任务会破坏CPU之前任务的cache,当之前那些任务回到CPU执行的时候性能会下降,同时也有功耗的增加。
B、整机负载的overload状态记录在root domain中的overload成员中。一个CPU处于overload状态就是指满足下面的条件:
a) 大于1个runnable task,即该CPU上有等待执行的任务
b) 只有一个正在运行的任务,但是是misfit task
满足上面的条件我们称这个CPU是overload状态的,如果系统中至少有一个CPU是overload状态,那么我们认为系统是overload状态的。如果系统没有overload,那么也就没有需要拉取的任务,也就必要做new idle load balance了。
C、由于不适合进行new idle balance(仅做阻塞负载更新),本cpu即将进入idle状态,即CPU忙闲状态发生变化,对应base domain的均衡间隔也需要进行相应的更新
D、和nohz idle balance一样,new idle balance不仅仅要处理负载均衡,同时也要负责处理blocked load的更新。如果条件不满足,该cpu不需要进行均衡,那么在进入idle状态之前,还需要看看系统中的哪些idle cpu们的blocked load是否需要更新了,如果需要,那么该CPU就会执行blocked load的负载更新。其背后的逻辑是:与其在nohz idle balance过程中遍历选择一个idle CPU来做负载更新,还不如就让这个即将进入idle的cpu来处理。(注意:5.10的代码仍然使用kick_ilb选择一个CPU发起仅负载更新的均衡,最新代码已经修复这个issue)
上面的代码已经过滤了不适合做newidle_balance的场景,代码至此说明需要在这个CPU上执行均衡,代码如下:
|
update_blocked_averages(this_cpu);-------------------------A for_each_domain(this_cpu, sd) { if (this_rq->avg_idle < curr_cost + sd->max_newidle_lb_cost) { update_next_balance(sd, &next_balance); break;-----------------B } if (sd->flags & SD_BALANCE_NEWIDLE) { t0 = sched_clock_cpu(this_cpu); pulled_task = load_balance(this_cpu, this_rq,-----------------C sd, CPU_NEWLY_IDLE, &continue_balancing); domain_cost = sched_clock_cpu(this_cpu) - t0; if (domain_cost > sd->max_newidle_lb_cost) sd->max_newidle_lb_cost = domain_cost;--------------D curr_cost += domain_cost;---------------E } update_next_balance(sd, &next_balance); if (pulled_task || this_rq->nr_running > 0) break;----------------E } |
A、这段代码主要的功能是遍历这个即将进入idle状态CPU的各个level的sched domain,进行均衡。在均衡之前,首先更新负载
B、上段代码A中是从CPU视角做的决定(cache冷热),降低了new idlebalance的次数,此外,调度器也从sched domain的角度进行检查,进一步避免了new idlebalance发生的深度。首先我们要明确一点:做new idle load balance是有开销的,我们辛辛苦苦找到了繁忙的CPU,从它的runqueue中拉了任务来,然而如果自己其实也没有那么闲,可能很快就有任务放置到自己的runqueue上来,这样,那些用于均衡的CPU时间其实都白白浪费了。怎么避免这个尴尬状况?我们需要两个数据:一个是当前CPU的平均idle时间,另外一个是在new idle load balance引入的开销(max_newidle_lb_cost成员)。如果CPU的平均idle时间小于max_newidle_lb_cost+本次均衡的开销,那么就不启动均衡。
C、如果该sched domain支持newidle balance,那么调用load_balance启动均衡
D、如果需要,更新该sched domain上的最大newidle balance开销
E、累计各个层级sched domain上的开销,用于控制new idle balance的层级深度
F、在任何一个层级的sched domain上通过均衡拉取了任务,那么new idle balance都会终止,不会进一步去更高层级上进行sched domain的均衡。同样的,这也是为了控制new idle balance的开销。
2、关于new idle balance的开销
由于其他的均衡方式都是基于tick触发的,因此均衡次数都比较容易控制住。New idle balance不一样,每次cpu进入idle就会触发,因此我们需要谨慎对待。目前内核中使用两个参数来控制new idle balance的频次:cpu的平均idle时间和new idle balance的最大开销。本小节描述如何计算这两个参数的。
struct sched_domain数据结构中有下面的成员记录new idle balance的开销:
|
成员 |
描述 |
|
u64 max_newidle_lb_cost |
在该domain上进行newidle balance的最大时间长度(即newidle balance的开销)。 每次在该domain上进行new idle balance的时候都会记录时长,然后把最大值记录在这个成员中。 这个值会随着时间衰减,防止一次极值会造成永久的影响。 |
|
unsigned long next_decay_max_lb_cost |
max_newidle_lb_cost会记录最近在该sched domain上进行newidle balance的最大时间长度,这个max cost不是一成不变的,它有一个衰减过程,每秒衰减1%,这个成员就是用来控制衰减的。 |
为了控制cpu无效进入new idle load balance,struct rq数据结构中有下面的成员:
|
成员 |
描述 |
|
idle_stamp |
记录CPU进入idle状态的时间点,用于计算avg_idle。在该CPU执行任务期间,该值等于0 |
|
avg_idle |
记录CPU的平均idle时间 |
|
max_idle_balance_cost |
该CPU进行new idle balance的最大开销。 |
CPU在进行new idle balance的时候需要在各个层级上执行new idle均衡,rq的max_idle_balance_cost成员就是汇聚了各个level上sched domain进行new idle balance的最大时间开销之和,但是限制其最小值sysctl_sched_migration_cost。
avg_idle的算法非常简单,首先在newidle_balance的时候记录idle_stamp,第一调用ttwu_do_wakeup的时候会计算这之间的时间,得到本次的CPU处于idle状态的时间,然后通过下面的公式计算平均idle time:
|
当前的avg_idle = 上次avg_idle + (本次idle time - 上次avg_idle)/8 |
为了防止CPU一次idle太久时间带来的影响,我们限制了avg_idle的最大值,即计算出来avg_idle的值不能大于2倍的max_idle_balance_cost值。
五、结束语
周期性均衡和nohz idle balance都是SCHED类型的软中断触发,最后都调用了rebalance_domains来执行该CPU上各个level的sched domain的均衡,具体在某个sched domain执行均衡的函数是load_balance函数。对于new idle load balance,也是遍历该CPU上各个level的sched domain执行均衡动作,调用的函数仍然是load_balance。因此,无论哪一种均衡,最后都万法归宗来到load_balance。由于篇幅原因,本文不再相信分析load_balance的逻辑,想要了解细节且听下回分解吧。
参考文献:
1、内核源代码
2、linux-5.10.61\Documentation\scheduler\*
本文首发在“内核工匠”微信公众号,欢迎扫描以下二维码关注公众号获取最新Linux技术分享:
评论:
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2023-02-02 14:39