
Perf book 9.3章节翻译(下)
作者:linuxer 发布于:2016-2-26 19:36 分类:内核同步机制
9.3.3.2 RCU is a Restricted Reference-Counting Mechanism
Because grace periods are not allowed to complete while there is an RCU read-side critical section in progress, the RCU read-side primitives may be used as a restricted reference-counting mechanism. For example, consider the following code fragment:
如果有thread仍然在RCU读侧的临界区内,那么Grace period不会结束,因此,RCU读侧的原语可以被用来做引用计数(当然不是适用所有场景,有些场景不能使用,因此这里说是restricted reference-counting mechanism)。例如下面的代码片段:
1 rcu_read_lock(); /* acquire reference. */
2 p = rcu_dereference(head);
3 /* do something with p. */
4 rcu_read_unlock(); /* release reference. */
The rcu_read_lock() primitive can be thought of as acquiring a reference to p, because a grace period starting after the rcu_dereference() assigns to p cannot possibly end until after we reach the matching rcu_read_unlock(). This reference-counting scheme is restricted in that we are not allowed to block in RCU read-side critical sections, nor are we permitted to hand off an RCU read-side critical section from one task to another.
rcu_read_lock() 原语可以被认为是获取了一个关于p指针(指向受RCU保护的数据)的引用,因为在rcu_dereference() 之后才启动的Grace period必须要等待该thread执行完rcu_read_unlock()。这种引用计数的机制是受限的,因为RCU读临界区是不运行阻塞的,所有有block需求的场景是不能使用这种机制的。此外,由于RCU读临界区是不运行抢占的,因此,对于那些想要打开抢占的代码片段,这个机制也不适用。
Regardless of these restrictions, the following code can safely delete p: The assignment to head prevents any future references to p from being acquired, and the synchronize_rcu() waits for any previously acquired references to be
released.
尽管有这些限制,下面的代码仍然能安全的删除P:
1 spin_lock(&mylock);
2 p = head;
3 rcu_assign_pointer(head, NULL);
4 spin_unlock(&mylock);
5 /* Wait for all references to be released. */
6 synchronize_rcu();
7 kfree(p);
第三行对head的赋值阻止了其他thread通过p获取对head的引用。因此synchronize_rcu() 会等待之前的读临界区结束,释放对受RCU保护数据的引用。
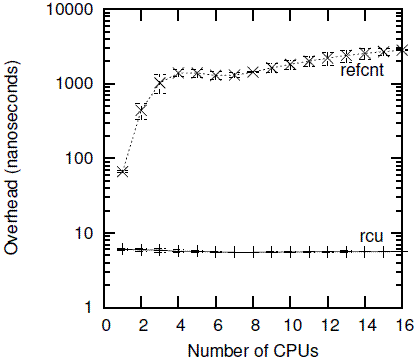
Of course, RCU can also be combined with traditional reference counting, as has been discussed on LKML and as summarized in Section 9.1. But why bother? Again, part of the answer is performance, as shown in Figure 9.30, again showing data taken on a 16-CPU 3GHz Intel x86 system.
当然,就像在LKML上讨论的那样,RCU也可以和传统的引用计数组合来使用,这些内容已经在9.1小节总结过了。
有了传统的引用计数机制,为何还要搞一个RCU based 引用计数机制呢?同样的,部分答案也是由于性能。就像下面的图片展示了16 CPU情况下,3GHz的Intel x86系统中RCU和reference counting机制的性能对比。
And, as with reader-writer locking, the performance advantages of RCU are most pronounced for short-duration critical sections, as shown Figure 9.31 for a 16-CPU system. In addition, as with reader-writer locking, many system calls (and thus any RCU read-side critical sections that they contain) complete in a few microseconds.
However, the restrictions that go with RCU can be quite onerous. For example, in many cases, the prohibition against sleeping while in an RCU read-side critical section would defeat the entire purpose. The next section looks at ways of addressing this problem, while also reducing the complexity of traditional reference counting, at least in some cases.
就像在上一节展示的那样,RCU的性能优势在较短的临界区的场合中能够优美的展示出来,具体请参考下图:

此外,和rwlock那一小节说的类似,大部分的系统调用可以在几个ms内完成,因此RCU的临界区也不会太长。不过RCU base的引用计数机制有天然的限制,只一点很烦人。例如:在很多场景下,不允许读临界区sleep的限制会把整个事情搞砸。下一节我们会处理这个问题,同时也会降低传统引用计数机制的复杂度(至少是在某些场合下)。
9.3.3.3 RCU is a Bulk Reference-Counting Mechanism
As noted in the preceding section, traditional reference counters are usually associated with a specific data structure, or perhaps a specific group of data structures. However, maintaining a single global reference counter for a large variety of data structures typically results in bouncing the cache line containing the reference count. Such cacheline
bouncing can severely degrade performance.
In contrast, RCU’s light-weight read-side primitives permit extremely frequent readside usage with negligible performance degradation, permitting RCU to be used as a “bulk reference-counting” mechanism with little or no performance penalty. Situations where a reference must be held by a single task across a section of code that blocks may be accommodated with Sleepable RCU (SRCU) [McK06]. This fails to cover the not-uncommon situation where a reference is “passed” from one task to another, for example, when a reference is acquired when starting an I/O and released in the corresponding completion interrupt handler. (In principle, this could be handled by the SRCU implementation, but in practice, it is not yet clear whether this is a good tradeoff.)
传统的引用计数机制一般是和某个特定的数据结构相关联(在数据结构中嵌入一个reference counter的成员), 这一点在前面的章节中我们已经说明了。不过,如果要为大量的、各种不同的数据结构维护一个全局的counter,这会导致cacheline bouncing现象,从而极大的影响了性能。而这种情况下,其实使用RCU是一个不错的选择。RCU reader side原语非常的轻盈,即便是频繁的调用也不会造成性能的降低,因此,我们可以说RCU可以应用在批量数据结构的引用计数机制中(一般引用计数是for一个数据结构对象的,但是一个reference counter应用在多个数据结构对象的时候,我们称之bulk reference counting)。对于那些想持有一个reference进入睡眠的场景,可以考虑使用SRCU。即便如此,仍然有些不太常见的场景我们无法覆盖到,比如reference可以从一个task传递到另外一个task的场景。举一个具体的例子:在启动I/O的时候获取了对某个数据的reference,但是却是在中断处理中释放这个reference。(理论上,SRCU也能处理这种场景,但是在实际的SRCU的实现过程中需要平衡)
Of course, SRCU brings restrictions of its own, namely that the return value from srcu_read_lock() be passed into the corresponding srcu_read_unlock(), and that no SRCU primitives be invoked from hardware interrupt handlers or from non-maskable interrupt (NMI) handlers. The jury is still out as to how much of a problem is presented by these restrictions, and as to how they can best be handled.
当然,SRCU也有自己的限制,也就是srcu_read_lock() 的返回值需要传递给对应的srcu_read_unlock(),此外,SRCU的原语也不能在中断handler或者NMI handler中调用。到底这些限制会带来多少的问题?如何优雅的处理这些限制?这些问题都还没有定论。
9.3.3.4 RCU is a Poor Man’s Garbage Collector
A not-uncommon exclamation made by people first learning about RCU is “RCU is sort of like a garbage collector!”. This exclamation has a large grain of truth, but it can also be misleading.
Perhaps the best way to think of the relationship between RCU and automatic garbage collectors (GCs) is that RCU resembles a GC in that the timing of collection is automatically determined, but that RCU differs from a GC in that: (1) the programmer must manually indicate when a given data structure is eligible to be collected, and (2) the programmer must manually mark the RCU read-side critical sections where references might legitimately be held.
Despite these differences, the resemblance does go quite deep, and has appeared in at least one theoretical analysis of RCU. Furthermore, the first RCU-like mechanism I am aware of used a garbage collector to handle the grace eriods. Nevertheless, a better way of thinking of RCU is described in the following section.
当第一次学习RCU的时候,一个普通的反应就是:RCU看起来好象是某种垃圾回收的机制。这种感慨也不无道理,但是容易把人引入歧途。
那么如何看待RCU和自动垃圾回收机制呢?类似自动垃圾回收机制,RCU确定回收的时间点也是自动确认的,但是RCU有自己的不同之处:(1)程序员必须自己手动告知一个给定数据结构可以被回收了。(2)程序员必须手动标识RCU读侧临界区,以便持有对数据的reference。
尽管有这些不同,但是在较深的层次仍然有相同之处,这一点出现在某些RCU理论分析中。此外,我了解的第一个类RCU机制就是使用garbage collector来处理grace period。无论如何,我们会在后续的章节中描述如何更好的理解RCU的方法。
9.3.3.5 RCU is aWay of Providing Existence Guarantees
Gamsa et al. [GKAS99] discuss existence guarantees and describe how a mechanism resembling RCU can be used to provide these existence guarantees (see section 5 on page 7 of the PDF), and Section 7.4 discusses how to guarantee existence via locking, along with the ensuing disadvantages of doing so. The effect is that if any RCU-protected data element is accessed within an RCU read-side critical section, that data element is guaranteed to remain in existence for the duration of that RCU read-side critical section.
Figure 9.32 demonstrates how RCU-based existence guarantees can enable perelement locking via a function that deletes an element from a hash table. Line 6 computes a hash function, and line 7 enters an RCU read-side critical section. If line 9 finds that the corresponding bucket of the hash table is empty or that the element present is not the one we wish to delete, then line 10 exits the RCU read-side critical section and line 11 indicates failure.
Gamsa等人在[GKAS99]文献中讨论了关于确认数据对象存在的机制(existence guarantees ),并且描述了一种类似RCU的机制用来保证数据对象的存在性(具体可以参考该文献的第七页的section 5)。同时,该文献在7.4小节也讨论了如何通过锁的机制来保证数据对象的存在性,以及该方法的不利之处。最终的结果就是:如果受RCU包含的数据仍然在读侧临界区被访问,那么该数据可以保证在整个读侧临界区中都是存在的,不会被释放。
1 int delete(int key)
2 {
3 struct element *p;
4 int b;
5
6 b = hashfunction(key);
7 rcu_read_lock();
8 p = rcu_dereference(hashtable[b]);
9 if (p == NULL || p->key != key) {
10 rcu_read_unlock();
11 return 0;
12 }
13 spin_lock(&p->lock);
14 if (hashtable[b] == p && p->key == key) {
15 rcu_read_unlock();
16 rcu_assign_pointer(hashtable[b], NULL);
17 spin_unlock(&p->lock);
18 synchronize_rcu();
19 kfree(p);
20 return 1;
21 }
22 spin_unlock(&p->lock);
23 rcu_read_unlock();
24 return 0;
25 }
上面的代码是一个基于RCU的existence guarantee的例子。第6行代码是计算hash值,第七行进入读侧临界区,如果第9行发现对应hash值的bucket是空的,或者说对应的节点不是我们需要找的(在这个例子中,bucket中只有一个节点),那么就在第10行退出临界区。
Otherwise, line 13 acquires the update-side spinlock, and line 14 then checks that the element is still the one that we want. If so, line 15 leaves the RCU read-side critical section, line 16 removes it from the table, line 17 releases the lock, line 18 waits for all pre-existing RCU read-side critical sections to complete, line 19 frees the newly removed element, and line 20 indicates success. If the element is no longer the one we want, line 22 releases the lock, line 23 leaves the RCU read-side critical section, and line 24 indicates failure to delete the specified key.
否则在13行代码处获取updater侧的spinlock,14行确认该节点仍然是我们想要删除的。如果是,那么15行代码处会离开读侧临界区,在第16行将该节点从hash table中删除。第17行释放spinlock。18行等待之前的读侧临界区完成,第19行释放删除节点的内存,20行返回successs的flag。如果该节点不是我们想要删除的那个,那么在22行会释放spinlock,第23行离开读侧临界区,返回错误。
Alert readers will recognize this as only a slight variation on the original “RCU is a way of waiting for things to finish” theme, which is addressed in Section 9.3.3.7. They might also note the deadlock-immunity advantages over the lock-based existence guarantees discussed in Section 7.4.
机警的读者可能会发现:这个例子几乎和9.3.3.7中的例子一样,只是有微小的变化。他们也会发现,就Existence Guarantees机制而言,我们在本节讨论的RCU-base的方法要比在7.4小节讨论的那个lock-base的方法要好,因为本节的方法是不会产生死锁的。
9.3.3.6 RCU is aWay of Providing Type-Safe Memory
A number of lockless algorithms do not require that a given data element keep the same identity through a given RCU read-side critical section referencing it—but only if that data element retains the same type. In other words, these lockless algorithms can tolerate a given data element being freed and reallocated as the same type of structure while they are referencing it, but must prohibit a change in type. This guarantee, called “type-safe memory” in academic literature [GC96], is weaker than the existence guarantees in the previous section, and is therefore quite a bit harder to work with. Type-safe memory algorithms in the Linux kernel make use of slab caches, specially marking these caches with SLAB_DESTROY_BY_RCU so that RCU is used when returning a freed-up slab to system memory. This use of RCU guarantees that any in-use element of such a slab will remain in that slab, thus retaining its type, for the duration of any pre-existing RCU read-side critical sections.
许多的免锁(lockless)算法不需要受保护的节点数据在整个读侧的临界区内保持同样的身份(身份是什么意思?是我的理解是指识别一个数据对象的信息,对于这个场景,我的理解是数据对象的地址和类型,地址和类型组合起来可以唯一确定一段内存在的数据对象),只要该数据节点保持同样的数据类型就OK了。换句话说,这些lockless算法可以忍受在访问某个节点数据的时候,该节点数据被释放掉,并且重新分配为同样类型的数据结构,但是必须要强调:数据结构的类型是不能变的(原来节点数据的类型是struct foo,重新分配后不能修改成struct bar)。这个类型不能变化要求就是学术上称作type-safe memory的东东啦。type-safe memory的要求(数据对象保证类型不变即可)比前面几个小节描述的要求(数据对象必须保证其身份,即地址和类型都不能变)要弱一些,因此,处理起来比较困难一些。type-safe memory算法在linux kernel中利用了内存分配子系统的slab机制,并且会标注SLAB_DESTROY_BY_RCU,以便该slab块被释放的时候可以被RCU子系统使用。在使用过程中,这种slab内存块将会一直呆在它的slab中,并在整个现存读临界区中保持同样的类型。
These algorithms typically use a validation step that checks to make sure that the newly referenced data structure really is the one that was requested [LS86, Section 2.5]. These validation checks require that portions of the data structure remain untouched by the free-reallocate process. Such validation checks are usually very hard to get right, and can hide subtle and difficult bugs.
Therefore, although type-safety-based lockless algorithms can be extremely helpful in a very few difficult situations, you should instead use existence guarantees where possible. Simpler is after all almost always better!
这些算法一般是应用在确认自己当前访问的数据结构确实是之前请求的那个(参考[LS86, Section 2.5])。这种确认性检查需要数据结构的部分内容在free-reallocate过程之中保持不变。一般来说,这样的检查很难设计的对,而且容易引入很多难于处理的issue。
9.3.3.7 RCU is aWay ofWaiting for Things to Finish
As noted in Section 9.3.2 an important component of RCU is a way of waiting for RCU readers to finish. One of RCU’s great strengths is that it allows you to wait for each of thousands of different things to finish without having to explicitly track each and every one of them, and without having to worry about the performance degradation, scalability limitations, complex deadlock scenarios, and memory-leak hazards that are inherent in schemes that use explicit tracking.
In this section, we will show how synchronize_sched()’s read-side counterparts (which include anything that disables preemption, along with hardware operations and primitives that disable interrupts) permit you to implement interactions with nonmaskable interrupt (NMI) handlers that would be quite difficult if using locking. This approach has been called “Pure RCU” [McK04], and it is used in a number of places in the Linux kernel.
就像9.3.2小节说的那样,RCU算法的一个重要组成部分就是:它是一种等待RCU reader离开临界区的方法。RCU的一个强大的功能就是它允许你等待成千上万的事件结束,而不需要显示的跟踪每一个事件,也不需要担心性能降低、可扩展性的限制、复杂的死锁场景以及内存泄这些风险,如果使用显示跟踪算法,这些风险就会存在。
在这一节中,我们将展示synchronize_sched()所同步的那些读侧临界区们(当然也包括那些由于硬件操作而禁止抢占、关闭中断的场景)是如何允许你和NMI handler进行交互的,如果想要用锁的机制实现这一个功能可能会非常的困难。这个方法在文献[McK04]中被称作Pure RCU,在linux kernel中有不少的应用。
The basic form of such “Pure RCU” designs is as follows:
1. Make a change, for example, to the way that the OS reacts to an NMI.
2. Wait for all pre-existing read-side critical sections to completely finish (for example,by using the synchronize_sched() primitive). The key observation here is that subsequent RCU read-side critical sections are guaranteed to see whatever change was made.
3. Clean up, for example, return status indicating that the change was successfully made
Pure RCU的基本的形式被设计如下:
(1)当收到NMI中断的时候,OS作出反应,在NMI handler中进行一些修改(例如修改某些状态变量)
(2)等待所有之前存在的读侧临界区完成(例如:通过调用synchronize_sched() 接口)。这里主要的关注点就是:随后的RCU读侧临界区可以保证看到之前的改动。
(3)清理工作。例如:返回之前已经修改完毕的状态
The remainder of this section presents example code adapted from the Linux kernel. In this example, the timer_stop function uses synchronize_sched() to ensure that all in-flight NMI notifications have completed before freeing the associated resources. A simplified version of this code is shown Figure 9.33.
Lines 1-4 define a profile_buffer structure, containing a size and an indefinite array of entries. Line 5 defines a pointer to a profile buffer, which is presumably initialized elsewhere to point to a dynamically allocated region of memory.
这个小节的随后的内容都会focus在linux内核中的示例代码上。在这个代码示例中,timer_stop函数使用了synchronize_sched函数来保证正在执行的NMI通知已经完成,从而安全的释放相关的资源。下面是一个简单版本的例子程序:
1 struct profile_buffer {
2 long size;
3 atomic_t entry[0];
4 };
5 static struct profile_buffer *buf = NULL;
6
7 void nmi_profile(unsigned long pcvalue)
8 {
9 struct profile_buffer *p = rcu_dereference(buf);
10
11 if (p == NULL)
12 return;
13 if (pcvalue >= p->size)
14 return;
15 atomic_inc(&p->entry[pcvalue]);
16 }
17
18 void nmi_stop(void)
19 {
20 struct profile_buffer *p = buf;
21
22 if (p == NULL)
23 return;
24 rcu_assign_pointer(buf, NULL);
25 synchronize_sched();
26 kfree(p);
27 }
1~4行定义了profile_buffer 这个数据结构,包含了一个size成员和一个不确定的数组entry成员,第五行定义了一个指针指向了profile buffer,初始值为NULL,未来估计会在程序中的某个位置初始化为一个动态分配的profile buffer。
Lines 7-16 define the nmi_profile() function, which is called from within an NMI handler. As such, it cannot be preempted, nor can it be interrupted by a normal interrupts handler, however, it is still subject to delays due to cache misses, ECC errors, and cycle stealing by other hardware threads within the same core. Line 9 gets a local pointer to the profile buffer using the rcu_dereference() primitive to ensure memory ordering on DEC Alpha, and lines 11 and 12 exit from this function if there is no profile buffer currently allocated, while lines 13 and 14 exit from this function if the pcvalue argument is out of range. Otherwise, line 15 increments the profile-buffer entry indexed by the pcvalue argument. Note that storing the size with the buffer guarantees that the range check matches the buffer, even if a large buffer is suddenly replaced by a smaller one.
7~16行定义了nmi_profile函数,将会被NMI handler调用,因此,这段代码不会被抢占,也不会被普通的中断handler打断执行。不过,由于cache miss,ECC errors,或者本CPU core中的其他hardware thread的cycle stealing(我也不知道这是什么,估计是超线程硬件资源的抢占的术语),这段代码仍然有可能delay执行。第9行首先通过rcu_dereference() 原语获取了一个指向profile buffer的局部指针变量,这个操作在DEC Alpha处理器上可以保证正确的内存访问顺序。如果不存在profile buffer,那么在12行退出。如果pcvalue大于当前profile buffer的size,那么也会在14行退出。在完成必要的检查之后,第15行代码将增加pcvalue对应的buffer的数值。需要注意的是:保存size成员主要是为了范围检查,即便是用一个大的buffer替换了之前小的buffer也没有问题。
Lines 18-27 define the nmi_stop() function, where the caller is responsible for mutual exclusion (for example, holding the correct lock). Line 20 fetches a pointer to the profile buffer, and lines 22 and 23 exit the function if there is no buffer. Otherwise, line 24 NULLs out the profile-buffer pointer (using the rcu_assign_pointer() primitive to maintain memory ordering on weakly ordered machines), and line 25 waits for an RCU Sched grace period to elapse, in particular, waiting for all non-preemptible regions of code, including NMI handlers, to complete. Once execution continues at line 26, we are guaranteed that any instance of nmi_profile() that obtained a pointer to the old buffer has returned. It is therefore safe to free the buffer, in this case using the kfree() primitive.
18~27行定义了nmi_stop() 函数,调用者在调用该函数的时候需要采用必要的互斥机制(例如使用正确的锁的机制)。第20行获取了一个指向profile buffer的指针,同样的,如果buffer不存在,在23行退出。否则在24行将buffer赋值为NULL(使用rcu_assign_pointer原语是保证采用弱内存模型CPU上的memory order)。25行是等待RCU sched grace period渡过,特别是要等待不可抢占的NMI handler完成。一旦指向到26行,可以保证在nmi_profile中对旧的profile buffer的访问已经结束,该函数已经返回,因此可以安全的释放这个内存。
In short, RCU makes it easy to dynamically switch among profile buffers (you just try doing this efficiently with atomic operations, or at all with locking!). However, RCU is normally used at a higher level of abstraction, as was shown in the previous sections.
简短的说呢RCU其实就是让profile buffer之间的动态切换变得简单(你可以考虑使用原子操作或者使用锁机制来“高效”的完成该功能,呵呵~~),不过RCU的主业还是更高层的抽象,就像我们前面章节描述的那样。
9.3.3.8 RCU Usage Summary
At its core, RCU is nothing more nor less than an API that provides:
1. a publish-subscribe mechanism for adding new data,
2. a way of waiting for pre-existing RCU readers to finish, and
3. a discipline of maintaining multiple versions to permit change without harming or unduly delaying concurrent RCU readers.
最后我们简单整理一下RCU的核心要素,它不多不少提供了下面的API:
(1)在增加新数据节点的时候采用publish-subscribe机制
(2)提供API以便等待之前已经存在的RCU读侧临界区完成
(3)维护多个版本的规则。这个规则可以允许updater进行数据的修改,同时不会影响并发的RCU reader
That said, it is possible to build higher-level constructs on top of RCU, including the reader-writer-locking, reference-counting, and existence-guarantee constructs listed in the earlier sections. Furthermore, I have no doubt that the Linux community will continue to find interesting new uses for RCU, as well as for any of a number of other
synchronization primitives. In the meantime, Figure 9.34 shows some rough rules of thumb on where RCU is most helpful.
也就是说,基于RCU机制,我们可以构建更高层次的一些软件模块,例如读写锁、引用计数和existence-guarantee,这些我们在前面的小节中都有所描述。此外,我丝毫不怀疑Linux内核社区会持续的挖掘RCU的新的有趣的应用场景,当然,对于其他的同步机制而言也是如此。下面这个图片展示了如何应用RCU机制的一些基本规则:

As shown in the blue box at the top of the figure, RCU works best if you have read-mostly data where stale and inconsistent data is permissible (but see below for more information on stale and inconsistent data). The canonical example of this case in the Linux kernel is routing tables. Because it may have taken many seconds or even minutes for the routing updates to propagate across Internet, the system has been sending packets the wrong way for quite some time. Having some small probability of continuing to send some of them the wrong way for a few more milliseconds is almost never a problem.
上图最顶端的蓝色box就是最适合RCU工作的场景:数据访问的场景大部分是read,偶尔有write,此外,reader thread们读到旧的或者不一致的数据也没有问题(后面会对旧数据以及不一致的数据进一步描述),最典型的例子就是linux内核中的路由表。由于系统需要花费若干秒,甚至是几分钟才能在internet上完成路由的更新,因此,只能使用旧的路由表进行数据包的发送。而用一个比较小的概率继续使用错误的路由数据来发送数据包(持续在几个毫秒)也是OK的。
If you have a read-mostly workload where consistent data is required, RCU works well, as shown by the green “read-mostly, need consistent data” box. One example of this case is the Linux kernel’s mapping from user-level System-V semaphore IDs to the corresponding in-kernel data structures. Semaphores tend to be used far more frequently than they are created and destroyed, so this mapping is read-mostly. However, it would be erroneous to perform a semaphore operation on a semaphore that has already been deleted. This need for consistency is handled by using the lock in the in-kernel semaphore data structure, along with a “deleted” flag that is set when deleting a semaphore. If a user ID maps to an in-kernel data structure with the “deleted” flag set, the data structure is ignored, so that the user ID is flagged as invalid.
Although this requires that the readers acquire a lock for the data structure representing the semaphore itself, it allows them to dispense with locking for the mapping data structure. The readers therefore locklessly traverse the tree used to map from ID to data structure, which in turn greatly improves performance, scalability, and real-timeresponse.
如果你的场景是这样的:虽然的确大部分是读操作,但是要求数据一致。这种场景RCU也基本能很好的工作,就像上面图片中的绿色block。一个关于这个场景的例子就是kernel中将user-level的System-V的semaphore ID映射到kernel内部的数据结构。对于这种semaphore,读的操作显然要远远大于创建或者销毁一个semaphore,因此它符合read-mostly这个要求。然而,如果在一个已经删除的semaphore上仍然执行操作,这就有问题了,为了满足这个数据一致性的需求,我们可以在kernel内部的semaphore数据结构中增加一个可以记录删除标记的flag成员以及一个锁的成员,当删除该数据结构的时候,我们在flag成员上标记删除标记,如果用户semaphore ID映射到了一个被删除的semaphore,那么后续的操作是无效的,对该数据结构的访问被忽略掉。
尽管reader在访问flag的时候需要持有锁,不过在映射到内核中数据结构的时候不需要持有锁,因此,对于reader而言,在通过semaphore ID遍历内核中的semaphore数据结构找到对应其对应的那个semaphore data的时候是lockfree的,这也就意味着性能,可扩展性,以及实时响应不会受到影响。
As indicated by the yellow “read-write” box, RCU can also be useful for read-write workloads where consistent data is required, although usually in conjunction with a number of other synchronization primitives. For example, the directory-entry cache in recent Linux kernels uses RCU in conjunction with sequence locks, per-CPU locks, and per-data-structure locks to allow lockless traversal of pathnames in the common case. Although RCU can be very beneficial in this read-write case, such use is often more complex than that of the read-mostly cases.
我们继续向下看,来到黄色的block,也就是有读有写并且要求数据一致性的场景。这个场景也许RCU也能帮上点忙,不过一般需要和其他的同步机制协同工作。比如最近内核中的directory-entry cache就使用了RCU + 顺序锁 + per-CPU lock + per-data-sturct-lock的机制以便让遍历路径名字的时候lockless。尽管RCU在有读有写的场景也能发挥其优势,但是显然比read-mostly场景要复杂的多。
Finally, as indicated by the red box at the bottom of the figure, update-mostly workloads requiring consistent data are rarely good places to use RCU, though there are some exceptions [DMS+12]. In addition, as noted in Section 9.3.3.6, within the Linux kernel, the SLAB_DESTROY_BY_RCU slab-allocator flag provides type-safe memory to RCU readers, which can greatly simplify non-blocking synchronization and other lockless algorithms.
最后我们来看看红色block的场景:大部分是更新操作,并且要求数据一致性。基本上这个场景其实是不适应RCU机制的,不过仍然有一些例外(参考[DMS+12])。此外,就像在9.3.3.6小节描述的那样,在linux kernel内部,标记SLAB_DESTROY_BY_RCU 的slab分配器为RCU reader提供了type-safe memory,可以大大简化非阻塞的同步操作以及其他的lockless算法。
In short, RCU is an API that includes a publish-subscribe mechanism for adding new data, a way of waiting for pre-existing RCU readers to finish, and a discipline of maintaining multiple versions to allow updates to avoid harming or unduly delaying concurrent RCU readers. This RCU API is best suited for read-mostly situations, especially if stale and inconsistent data can be tolerated by the application.
最后,一言以蔽之,RCU机制提供了下面3种API:publish-subscribe机制用于增加新的数据节点,等待已经存在的RCU reader离开临界区,维护多个版本的数据,使得updater不会影响并发reader的性能。RCU的API多用于read-mostly的场景,特别是可以容忍reader获取旧的或者不一致的数据。
9.3.4 RCU Linux-Kernel API
This section looks at RCU from the viewpoint of its Linux-kernel API. Section 9.3.4.1 presents RCU’s wait-to-finish APIs, and Section 9.3.4.2 presents RCU’s publishsubscribe and version-maintenance APIs. Finally, Section 9.3.4.4 presents concluding remarks.
这一节主要关注在linux内核的RCU API上。9.3.4.1小节关注等待reader临界区完成的API。9.3.4.2小节描述了publish-subscribe 的接口以及维护多个版本数据的API。最后9.3.4.4小节给出了结论性的评论。
9.3.4.1 RCU has a Family of Wait-to-Finish APIs
The most straightforward answer to “what is RCU” is that RCU is an API used in the Linux kernel, as summarized by Tables 9.4 and 9.5, which shows the wait-for-RCU readers portions of the non-sleepable and sleepable APIs, respectively, and by Table 9.6, which shows the publish/subscribe portions of the API.
对“什么是RCU”这个问题的最直接的回答就是:RCU是linux kernel中使用的一组API接口,总结如下:
| Attribute | RCU classic | RCU BH | RCU sched | Realtime RCU |
| purpose | Original | Prevent DDoS attack | wait for preempt disable regions,hardirq and NMI | Realtime response |
| avilability | 2.5.43 | 2.6.9 | 2.6.12 | 2.6.26 |
| 读侧原语 |
rcu_read_lock rcu_read_unlock |
rcu_read_lock_bh rcu_read_unlock_bh |
preempt_disable preempt_enable 等 |
rcu_read_lock rcu_read_unlock |
|
更新侧原语 (同步) |
synchronize_rcu synchronize_net |
synchronize_sched |
synchronize_rcu synchronize_net |
|
|
更新侧原语 (异步/callback) |
call_rcu | call_rcu_bh | call_rcu_sched | call_rcu |
|
更新侧原语 (等待callback完成) |
rcu_barrier | rcu_barrier_bh | rcu_barrier_sched | rcu_barrier |
| type-safe memory | SLAB_DESTROY_BY_RCU | SLAB_DESTROY_BY_RCU | ||
| 读侧限制 | 不允许睡眠 | 不能enable irq | 不能睡眠 | Only preemption and lock acquisition |
| 读侧开销 |
抢占式内核:enable/disable preempt 非抢占式内核:无 |
BH enable/disable |
抢占式内核:enable/disable preempt 非抢占式内核:无 |
Simple instructions, irq disable/enable |
| 异步更新侧开销 | 微秒以下 | 微秒以下 | 微秒以下 | |
| Grace Period延迟 | 几十个毫秒 | 几十个毫秒 | 几十个毫秒 | 几十个毫秒 |
| 没有配置PREEMPT_RT | RCU Classic | RCU BH | RCU classic | Preemptible RCU |
| 配置PREEMPT_RT | preemptible RCU | realtime RCU | 强制在所有CPU上进行调度 | realtime RCU |
上面的这个表格总结了non-sleepable RCU等待reader离开临界区的API。
| Attribute | SRCU | QRCU |
| purpose | sleeping reader | sleeping reader and fast Grace Period |
| avilability | 2.6.19 | |
| 读侧原语 |
srcu_read_lock srcu_read_unlock |
qrcu_read_lock qrcu_read_unlock |
| 更新侧原语(同步) | synchronize_srcu | synchronize_qrcu |
| 更新侧原语(异步/callback) | N/A | N/A |
| 更新侧原语(等待callback完成) | N/A | N/A |
| type-safe memory | ||
| 读侧限制 | 不能调用synchronize_srcu | 不能调用synchronize_qrcu |
| 读侧开销 | 简单的指令,preempt disable/enable | Atomic increment and decrement of shared variable |
| 异步更新侧开销 | N/A | N/A |
| Grace Period延迟 | 几十个毫秒 | 如果没有reader,仅仅需要几十个ns |
| 没有配置PREEMPT_RT | SRCU | N/A |
| 配置PREEMPT_RT | SRCU | N/A |
上面的这个表格总结了sleepable RCU等待reader离开临界区的API。
If you are new to RCU, you might consider focusing on just one of the columns in Table 9.4, each of which summarizes one member of the Linux kernel’s RCU API family. For example, if you are primarily interested in understanding how RCU is used in the Linux kernel, “RCU Classic” would be the place to start, as it is used most frequently. On the other hand, if you want to understand RCU for its own sake, “SRCU” has the simplest API. You can always come back for the other columns later.
If you are already familiar with RCU, these tables can serve as a useful reference.
如果你是RCU的新手,你可能需要focus在某一个列上,在上面的表格中,每一个列都总结了一类RCU的接口API。如果你主要的想法是理解RCU是如何在linux kernel中被使用的,那么RCU classic是一个很好的开始,因为它应用最广泛。另外一方面,如果你想要理解RCU内部的种种机制,那么SRCU比较适合,因为它的API最简单。在理解其中一列之后,你可以再慢慢熟悉其他。
如果你早已经了熟悉了RCU,那么这些表格可以做为一个有用的参考。
The “RCU Classic” column corresponds to the original RCU implementation, in which RCU read-side critical sections are delimited by rcu_read_lock() and rcu_read_unlock(), which may be nested. The corresponding synchronous updateside primitives, synchronize_rcu(), along with its synonym synchronize_net(), wait for any currently executing RCU read-side critical sections to complete. The length of this wait is known as a “grace period”. The asynchronous update-side primitive, call_rcu(), invokes a specified function with a specified argument after a subsequent grace period. For example, call_rcu(p,f); will result in the “RCU callback” f(p) being invoked after a subsequent grace period. There are situations, such as when unloading a Linux-kernel module that uses call_rcu(), when it is necessary to wait for all outstanding RCU callbacks to complete [McK07d]. The rcu_barrier() primitive does this job. Note that the more recent hierarchical RCU [McK08a] implementation also adheres to “RCU Classic” semantics.
RCU classic那一列实际上就是最原始的RCU实现版本,在该版本的实现中,RCU 读侧临界区被rcu_read_lock() 和 rcu_read_unlock()包围,当然读侧临界区也可以被嵌套。对应的同步更新原语synchronize_rcu()和一个类似的接口synchronize_net()用来等待任何一个当前正在读侧临界区的reader离开临界区。这个等待的时间段被成为宽限期(Grace period)。而异步更新侧的原语,call_rcu设定了一个grace period过去之后调用的callback函数。例如:call_rcu(p,f); 将会导致RCU callback函数f(p)在Grace period渡过之后被调用。在某些场合中,例如卸载linux内核的模块,并且在卸载函数中会调用call_rcu函数。这时候,不能仅仅等待grace period渡过,而是需要等待RCU callback函数执行完毕。在这种场景下,你需要使用rcu_barrier接口来完成这个功能。顺便一提的是:最新的hierarchical RCU的实现也遵守了RCU classic所规定的各种语义。
Finally, RCU may be used to provide type-safe memory [GC96], as described in Section 9.3.3.6. In the context of RCU, type-safe memory guarantees that a given data element will not change type during any RCU read-side critical section that accesses it. To make use of RCU-based type-safe memory, pass SLAB_DESTROY_BY_RCU to kmem_cache_create(). It is important to note that SLAB_DESTROY_BY_RCU will in no way prevent kmem_cache_alloc() from immediately reallocating memory that was just now freed via kmem_cache_free()! In fact, the SLAB_ DESTROY_BY_RCU-protected data structure just returned by rcu_dereference might be freed and reallocated an arbitrarily large number of times, even when under the protection of rcu_read_lock(). Instead, SLAB_DESTROY_BY_RCU operates by preventing kmem_cache_free() from returning a completely freed-up slab of data structures to the system until after an RCU grace period elapses. In short, although the data element might be freed and reallocated arbitrarily often, at least its type will remain the same.
最后一点要说明的是:RCU也可以用于提供type-safe memory,就像在9.3.3.6小节描述的那样。在RCU的上下文中,type-safe memory保证了给定的数据节点在整个RCU读侧临界区内不会改变其类型。为了使用基于RCU算法的type-safe memory,在调用kmem_cache_create()的时候需要传入SLAB_DESTROY_BY_RCU这个flag。有一点很重要,我们需要之处的是:在调用kmem_cache_free()接口释放了内存之后,SLAB_DESTROY_BY_RCU flag并不会阻止kmem_cache_alloc() 将该内存分配他用,实际上,在读侧临界区,通过rcu_dereference获取的那个RCU保护的内存(在slab cache中,有SLAB_ DESTROY_BY_RCU flag)可以释放,然后重新分配任意多次,即便是在读侧临界区内也是如此。而SLAB_ DESTROY_BY_RCU这个flag的真实用途是阻止在kmem_cache_free() 的时候将这段内存返回给系统,除非在Grace period过去之后。总结一句话:数据节点的内存可以被释放、重新分配多次,但是其数据类型不变。
In the “RCU BH” column, rcu_read_lock_bh() and rcu_read_unlock_bh() delimit RCU read-side critical sections, and call_rcu_bh() invokes the specified function and argument after a subsequent grace period. Note that RCU BH does not have a synchronous synchronize_rcu_bh() interface, though one could easily be added if required.
对于RCU BH那一列而言,这种RCU的读侧临界区被rcu_read_lock_bh()和rcu_read_unlock_bh() 包围,并且call_rcu_bh()会注册一个callback函数,在宽限期过去之后,该callback函数会被调用。注意:RCU BH没有同步版本的synchronize_rcu_bh接口,如果需要的话,增加也很容易。
In the “RCU Sched” column, anything that disables preemption acts as an RCU read-side critical section, and synchronize_sched() waits for the corresponding RCU grace period. This RCU API family was added in the 2.6.12 kernel, which split the old synchronize_kernel() API into the current synchronize_rcu() (for RCU Classic) and synchronize_sched() (for RCU Sched). Note that RCU Sched did not originally have an asynchronous call_rcu_sched() interface, but one was added in 2.6.26. In accordance with the quasi-minimalist philosophy of the Linux community, APIs are added on an as-needed basis.
在RCU sched那一列,任何的代码区域,只要是disable了preempt,那么就是RCU sched的临界区了。对于updater侧,调用synchronize_sched() 就可以等待所有禁止抢占的那些RCU sched读临界区了。这一系列的RCU API是在2.6.12版本加入到内核中的。加入之后,原来的synchronize_kernel() API变成两个接口,一个是用于RCU classic的synchronize_rcu() ,另外一个就是用于RCU Sched的synchronize_sched()。需要注意的是,RCU sched一开始并没有异步接口call_rcu_sched,在2.6.26中增加了这个接口,这也符合了内核开源社区推崇的极简哲学:API在需要的时候才添加。
The “Realtime RCU” column has the same API as does RCU Classic, the only difference being that RCU read-side critical sections may be preempted and may block while acquiring spinlocks. The design of Realtime RCU is described elsewhere [McK07a].
Realtime RUC那一列其接口和RCU classic是一样的,唯一不同的是:realtime RCU的读侧临界区可以被抢占,也有可能由于试图获取spinlock而阻塞。关于realtime RCU更详细的介绍请参考[McK07a]文档。
The “SRCU” column in Table 9.5 displays a specialized RCU API that permits general sleeping in RCU read-side critical sections [McK06]. Of course, use of synchronize_srcu() in an SRCU read-side critical section can result in selfdeadlock, so should be avoided. SRCU differs from earlier RCU implementations in that the caller allocates an srcu_struct for each distinct SRCU usage. This approach prevents SRCU read-side critical sections from blocking unrelated synchronize_ srcu() invocations. In addition, in this variant of RCU, srcu_read_lock() returns a value that must be passed into the corresponding srcu_read_unlock().
SRCU那一列展示了一个特殊的RCU API的情况,这种RCU允许在读侧临界区睡眠。当然,如果在SRCU的读侧临界区调用synchronize_srcu() 会导致死锁,这是需要避免的。SRCU和前面说的那些RCU的实现都不一样,对于SRCU,它会为每一个不同的SRCU应用场景分配一个srcu_struct,这样设计主要是为了防止SRCU读侧阻塞其他不相关的synchronize_ srcu()调用。此外,这个RCU的变种的srcu_read_lock() 接口函数会返回一个handle,在调用srcu_read_unlock接口的时候需要传递这个handle。
The “QRCU” column presents an RCU implementation with the same API structure as SRCU, but optimized for extremely low-latency grace periods in absence of readers, as described elsewhere [McK07e]. As with SRCU, use of synchronize_qrcu() in a QRCU read-side critical section can result in self-deadlock, so should be avoided. Although QRCU has not yet been accepted into the Linux kernel, it is worth mentioning given that it is the only kernel-level RCU implementation that can boast deep submicrosecond grace-period latencies.
QRCU那一列的接口和SRCU是一样的,不过在临界区没有reader的时候,这种RCU做了优化,以便可以获取延迟非常低的grace period。如果你想了解更多,可以参考[McK07e]。和SRCU一样,在QRCU的读侧临界区调用synchronize_qrcu() 也会导致死锁,需要避免这种调用场景。虽然QRCU并没有并入kernel mainline,但是还是有必要说一说这一种RCU,因为QRCU是唯一一个能够把宽限期缩小到微秒以下的RCU实现。
The Linux kernel currently has a surprising number of RCU APIs and implementations. There is some hope of reducing this number, evidenced by the fact that a given build of the Linux kernel currently has at most three implementations behind four APIs (given that RCU Classic and Realtime RCU share the same API). However, careful inspection and analysis will be required, just as would be required in order to eliminate one of the many locking APIs.
The various RCU APIs are distinguished by the forward-progress guarantees that their RCU read-side critical sections must provide, and also by their scope, as follows:
linux kernel中有辣么多RCU API和实现,让人眼花缭乱,一个正常人肯定会想减少这个数目,让事情变得简单一些。开源社区也是这么想的,一个证据就是:在任何一个给定的编译后的linux kernel image中,最多有3个RCU实现,提供4类API(RCU classic和Realtime RCU的接口是一样的)。就像在众多锁机制接口中删除一个接口一样,删减RCU的接口和实现也需要好好的分析和检查。不同的RCU有不同的特点,例如读临界区是否可以被hard irq,nmi irq,softirq等中断而无法持续向前执行,例如RCU的作用域,是整个系统使用一个RCU还是内核各个子系统有其自己的RCU,我们描述如下:
1. RCU BH: read-side critical sections must guarantee forward progress against everything except for NMI and interrupt handlers, but not including softwareinterrupt (softirq) handlers. RCU BH is global in scope.
2. RCU Sched: read-side critical sections must guarantee forward progress against everything except for NMI and irq handlers, including softirq handlers. RCU Sched is global in scope.
3. RCU (both classic and real-time): read-side critical sections must guarantee forward progress against everything except for NMI handlers, irq handlers, softirq handlers, and (in the real-time case) higher-priority real-time tasks.
RCU is global in scope.
4. SRCU and QRCU: read-side critical sections need not guarantee forward progress unless some other task is waiting for the corresponding grace period to complete, in which case these read-side critical sections should complete in no more than a few seconds (and preferably much more quickly). SRCU’s and QRCU’s scope is defined by the use of the corresponding srcu_struct or qrcu_struct, respectively.
In other words, SRCU and QRCU compensate for their extremely weak forwardprogress guarantees by permitting the developer to restrict their scope.
1、RCU BH:除了NMI还有hard interrupt handler,任何其他的上下文都无法阻止读侧临界区的执行。软中断的handler也不行(rcu_read_lock_bh会disable softirq的)。RCU BH是全局的,整个系统就一个。
2、RCU Sched:除了NMI handler,hard interrupt handler和soft interrupt handler之外,任何其他的上下文都无法打断读侧临界区的执行。RCU sched也是全局的。
3、RCU(classic和realtime):读侧临界区必须保证可以持续不断的向前执行,除非遇到NMI handler,hard interrupt handler和soft interrupt handler,在real time的情况下,高优先级的realtime任务也能打断读侧临界区的执行。RCU是全局的。
4、SRCU和QRCU:读侧临界区不需要保证持续向前执行,因为thread很有可能在临界区内阻塞。如果有其他的任务正在等待对应的SRCU的宽限期结束,那么需要保证改读侧临界区持续向前执行,以便能在几秒钟的时间内(当然能更快就更好拉)完成读侧临界区的执行。SRCU和QRCU的作用范围都是局部的,其局部作用范围分别被srcu_struct o或者qrcu_struct所定义。
换句话说,对于SRCU和QRCU,为了补偿其非常弱的持续向前执行的能力,开发者只好限定了其作用范围。
9.3.4.2 RCU has Publish-Subscribe and Version-Maintenance APIs
Fortunately, the RCU publish-subscribe and version-maintenance primitives shown in the following table apply to all of the variants of RCU discussed above. This commonality can in some cases allow more code to be shared, which certainly reduces the API proliferation that would otherwise occur. The original purpose of the RCU publish-subscribe APIs was to bury memory barriers into these APIs, so that Linux kernel programmers could use RCU without needing to become expert on the memoryordering models of each of the 20+ CPU families that Linux supports [Spr01].
幸运的是所有变种RCU的 publish-subscribe 和维护多个版本的数据之原语都是一样的,参考下面的表格:
| Category | Primitives | Availability | Overhead |
| 遍历链表操作 | list_for_each_entry_rcu | 2.5.59 | 简单的指令(在Alpha上是memory barrier的操作 |
| 链表更新操作 |
list_add_rcu list_add_tail_rcu list_del_rcu list_replace_rcu list_splice_init_rcu |
2.5.44 2.5.44 2.5.44 2.6.9 2.6.21 |
memory barrier memory barrier 简单的指令 memory barrier 宽限期延迟 |
| 遍历Hlist |
hlist_for_each_entry_rcu |
2.6.8 | 简单的指令(在Alpha上是memory barrier的操作 |
| Hlist更新操作 |
hlist_add_after_rcu hlist_add_before_rcu hlist_add_head_rcu hlist_del_rcu hlist_replace_rcu |
2.6.14 2.6.14 2.5.64 2.5.64 2.6.15 |
memory barrier memory barrier memory barrier 简单的指令 memory barrier |
| 获取执行受RCU保护数据的指针 | rcu_dereference | 2.6.9 | 简单的指令(在Alpha上是memory barrier的操作 |
| 对受RCU保护数据的指针进行赋值 | rcu_assign_pointer | 2.6.10 | memory barrier |
由于接口保持了一致,在某些场景中代码可以共用,从而减少了RCU API的数目。最开始的时候,RCU的 publish-subscribe 接口API就是为了隐藏memory barrier的操作,有了这样的封装,工程师不必关心linux 内核支持的20多个CPU在内存模型上的各种知识,也能自如的使用RCU。
The first pair of categories operate on Linux struct list_head lists, which are circular, doubly-linked lists. The list_for_each_entry_rcu() primitive traverses an RCU-protected list in a type-safe manner, while also enforcing memory ordering for situations where a new list element is inserted into the list concurrently with traversal. On non-Alpha platforms, this primitive incurs little or no performance penalty compared to list_for_each_entry(). The list_add_rcu(), list_add_tail_rcu(), and list_replace_rcu() primitives are analogous to their non-RCU counterparts, but incur the overhead of an additional memory barrier on weaklyordered machines. The list_del_rcu() primitive is also analogous to its non-RCU counterpart, but oddly enough is very slightly faster due to the fact that it poisons only the prev pointer rather than both the prev and next pointers as list_del() must do. Finally, the list_splice_init_rcu() primitive is similar to its non-RCU counterpart, but incurs a full grace-period latency. The purpose of this grace period
is to allow RCU readers to finish their traversal of the source list before completely disconnecting it from the list header – failure to do this could prevent such readers from ever terminating their traversal.
前两行是关于linux kernel中的普通链表操作(也就是环形双向链表了)。list_for_each_entry_rcu接口可以用来安全的遍历一个受RCU保护的链表,于此同时,在遍历的同时,如果插入一个新的节点数据,改接口也能保证memory order。在Alpha平台上,和list_for_each_entry这个接口对比,改原语不会引起性能问题。list_add_rcu(), list_add_tail_rcu(), 和 list_replace_rcu() 这些接口原语都和非RCU版本类似,只不过在一些weakly order的CPU上,RCU版本的接口会有额外的memory barrier的开销。list_del_rcu接口也和其对于的非RCU版本类似,不过很奇妙的是:RCU版本的接口要快些,因为RCU版本的接口只需要毒化(poison)list_head中的pre成员,而在list_del需要毒化pre和next两个成员。
未完,待续。
原创翻译文章,转发请注明出处。蜗窝科技
评论:
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2016-12-20 16:45