
linux kernel内存回收机制
作者:itrocker 发布于:2015-11-12 20:37 分类:内存管理
无论计算机上有多少内存都是不够的,因而linux kernel需要回收一些很少使用的内存页面来保证系统持续有内存使用。页面回收的方式有页回写、页交换和页丢弃三种方式:如果一个很少使用的页的后备存储器是一个块设备(例如文件映射),则可以将内存直接同步到块设备,腾出的页面可以被重用;如果页面没有后备存储器,则可以交换到特定swap分区,再次被访问时再交换回内存;如果页面的后备存储器是一个文件,但文件内容在内存不能被修改(例如可执行文件),那么在当前不需要的情况下可直接丢弃。
1 回收的时机

2 哪些内存可以回收
2.1 页框的回收
LRU(Least Recently Used),近期最少使用链表,是按照近期的使用情况排列的,最少使用的存在链表末尾,通过以下宏定义即可看出:
#define lru_to_page(_head) (list_entry((_head)->prev, struct page, lru))
每个zone有5个LRU链表用以存放各种最近使用状态的页面。
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
其中INACTIVE_ANON、ACTIVE_ANON、INACTIVE_FILE、ACTIVE_FILE 4个链表中的页面是可以回收的。ANON代表匿名映射,没有后备存储器;FILE代表文件映射。
页面回收时,会优先回收INACTIVE的页面,只有当INACTIVE页面很少时,才会考虑回收ACTIVE页面。
为了评估页的活动程度,kernel引入了PG_referend和PG_active两个标志位。为什么需要两个位呢?假定只使用一个PG_active来标识页是否活动,在页被访问时,设置该位,但是何时清楚呢?为此需要维护大量的内核定时器,这种方法注定是要失败的。
使用两个标志,可以实现一种更精巧的方法,其核心思想是:一个表示当前活动程度,一个表示最近是否被引用过,下图说明了基本算法。
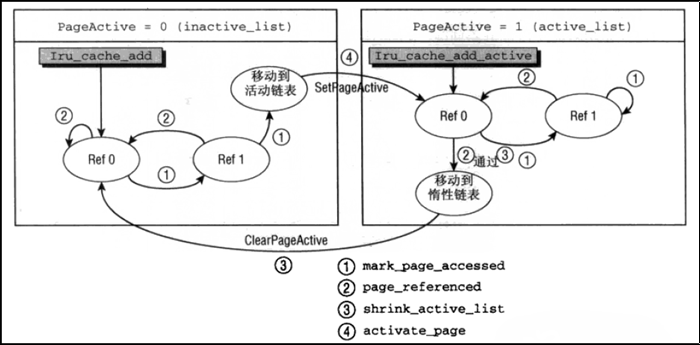
基本上有以下步骤:
(1)如果页是活动的,设置PG_active位,并保存在ACTIVE LRU链表;反之在INACTIVE;
(2)每次访问页时,设置PG_referenced位,负责该工作的是mark_page_accessed函数;
(3)PG_referenced以及由逆向映射提供的信息用来确定页面活动程度,每次清除该位时,都会检测页面活动程度,page_referenced函数实现了该行为;
(4)再次进入mark_page_accessed。如果发现PG_referenced已被置位,意味着page_referenced没有执行检查,因而对于mark_page_accessed的调用比page_referenced更频繁,这意味着页面经常被访问。如果该页位于INACTIVE链表,将其移动到ACTIVE,此外还会设置PG_active标志位,清除PG_referenced;
(5)反向的转移也是有可能的,在页面活动程度减少时,可能连续调用两次page_referenced而中间没有mark_page_accessed。
如果对内存页的访问是稳定的,那么对page_referenced和mark_page_accessed的调用在本质上是均衡的,因而页面保持在当前LRU链表。这种方案同时确保了内存页不会再ACTIVE与INACTIVE链表间快速跳跃。
2.2
slab缓存回收
slab缓存回收相对比较灵活,所有注册到shrinker_list中的方法都会被执行。
内核默认针对每个文件系统都注册了prune_super方法,这个函数用来回收文件系统中不再使用的dentry和inode缓存;
android的lowmemorykiller机制注册了选择性杀死进程的方法,回收进程使用的内存。
3怎样回收页框
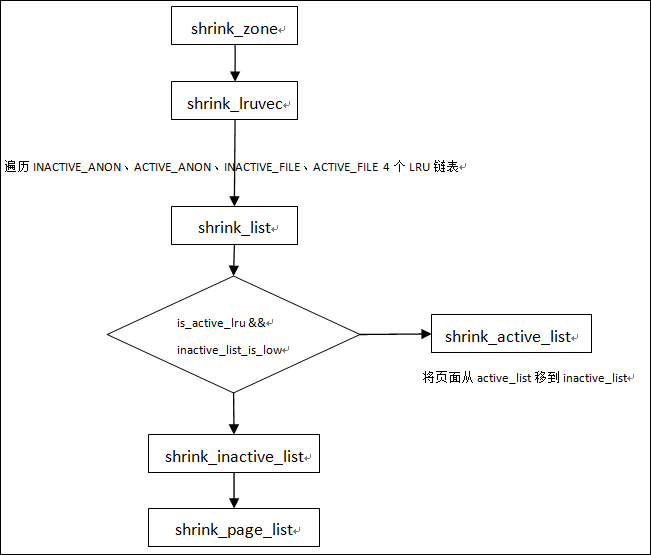
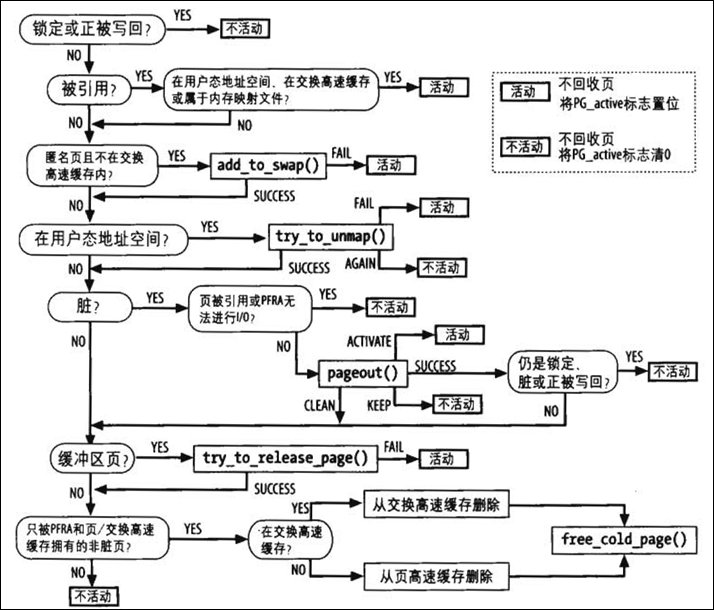
其中shrink_page_list是真正回收页面的过程
4周期性回收的频率
4.1
kswapd
kswapd是内核为每个内存node创建的内存回收线程,为什么有了紧缺回收机制还需要周期性回收呢?因为有些内存分配是不允许阻塞等待回收的,比如中断和异常处理程序中的内存分配;还有些内存分配不允许激活I/O访问的。只有少数情况的内存紧缺可以完整执行回收过程,所以利用系统空闲时间回收内存非常必要。
该函数记录了上一次均衡操作时所用的分配order,如果kswapd_max_order大于上一次的值,或者classzone_idx小于上一次的值,则调用balance_pgdat再次均衡该内存域,否则可以进行短暂休眠,休眠的时间是HZ/10,对于arm(HZ=100)来说,休眠的时间就是1ms。
balance_pgdat均衡操作直到该内存域的zone_wartermark_ok为止。
4.2
cache_reap
cache_reap用来回收slab中的空闲对象,如果空闲对象可以还原成一个页面,则释放回buddy system。每次调用cache_reap会把所有的slab_caches遍历一遍,之后休眠2*HZ,对于arm(HZ=100)来说,周期就是20ms。
5 参考文献
(1)《understanding the linux kernel》
(2)《professional linux kernel architecture》
评论:
2021-03-31 09:41
虚拟机通过VA得到IPA(你说的gpte/spte/pte)后,宿主机中的stage2页表负责IPA到PA(同理有另外一套页表map机制),host可以感知到IPA的PA的访问,同理加个硬件标志位 即可。
2018-07-19 19:38
1. 你提到kswapd会周期性的回收,并且正常情况下回收的周期是100ms。但是我代码中(kswapd_try_to_sleep)看到似乎是kswapd会先睡眠100ms,如果睡眠过程中没有被唤醒的话就永久进入睡眠,直到下一次被唤醒。这是否与你说的周期性回收相矛盾呢?
2. 我这边碰到一个问题,就是有时候会有突发性的GFP_ATOMIC标志的大量分配内存的需求,虽然每次分配只要一个页面,但会一下子要求分配很多。这种情况下我经常看到即使kswapd在工作,似乎回收速度也赶不上分配的速度,因此会造成分配失败。这个有什么办法能改善么?谢谢!
2018-06-04 15:50
而且现在inactive -> active 的转移除了mark_page_accessed,在shrink_page_list也有体现。
所以上面那张图貌似是老了,期待更新哈
2017-07-07 11:25
我理解HZ ARM中定义是100, 相当于1S内产生100个时钟中断,jiffies = 1S/100 = 10, 所以一个jiffes代表10ms, HZ是100个jiffes 等于1s,所以2HZ=2S, 但看您的计算HZ=1S/100 = 10MS, 难道我之前理解都错了么。。。请帮忙再普及下HZ,JIFFIES概念,谢谢~
2016-05-12 10:05
2016-05-13 09:18
也就是说,decache和inode回收时机,是文件系统自己的事情,和vm无关。而具体的回收行为,我也没有研究过,你可以试试自己看一下。
2016-03-06 21:50
当回收一个页框时,怎么知道这个页框是否在被使用呢?
-------------------------------------------
struct page中有reference counter,可以用来确定该page是否被引用。
如果用户程序映射到这个页框,并正在使用,是不是就不能回收?
-------------------------------------------
如果用户程序的正文段mapping到了某个物理page上来,实际上,在内存比较紧俏的时候,仍然会回收该page,只不过,但该用户程序再次执行的时候,访问正文段产生异常,然后再次分配page并从backup的磁盘中加载该page的数据,返回异常的现场。
2017-04-19 19:55
但该用户程序再次执行的时候,访问正文段产生异常,然后再次分配page并从backup的磁盘中加载该page的数据,返回异常的现场。
》》》我想问问,在回收page时,会把page 的内存backup到磁盘吗?
2017-04-28 14:11
非常感谢你的回复
count 在什么时候加一,减一又是什么时候?初始时,count是多少?当上层应用在执行free 的时候是否会对count 进行减一操作?
2017-04-28 16:35
应用调用memory和free的时候,分配的都是虚拟地址,和物理页帧没有任何的关系
2017-04-28 18:00
当然shrink_page_list是在shrink_inactive_list 中调用的,是否在内存回收时并不在乎_count 的值,如果等于1或者2,只要try_to_unmap就可以了?
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2021-03-30 17:40