
Process Creation(二)
作者:linuxer 发布于:2014-4-28 15:40 分类:进程管理
本文是Process Creation(一)的延续,主要内容包括:
1、进程描述符中Realtime Mutex相关数据结构的初始化
2、子进程如何复制父进程的credentials
3、per-task delay accounting的处理
4、子进程如何复制父进程的flag
七、初始化Realtime Mutex相关的成员
static void rt_mutex_init_task(struct task_struct *p)
{
raw_spin_lock_init(&p->pi_lock);
#ifdef CONFIG_RT_MUTEXES
p->pi_waiters = RB_ROOT;
p->pi_waiters_leftmost = NULL;
p->pi_blocked_on = NULL;
p->pi_top_task = NULL;
#endif
}
Mutex是一种人民群众喜闻乐见的内核同步方式,不过real time mutex是什么呢?real time mutex是被设计用来支PI-futexes的。什么是PI?什么又是futex?PI是优先级继承(Priority Inheritance),该方法是用来解决优先级翻转问题的。什么是优先级翻转(Priority Inversion)?它是一种调度延迟现象。一般而言,调度器总是优先调度到优先级高的进程(线程),但是,当同步资源被较低优先级的进程所拥有(也就是说持有锁),高优先级的进程未能获取该同步资源,这时候,高优先级进程要等到持有锁的进程释放该资源后才能被调度到。下面的图片更加详细的描述了该问题:
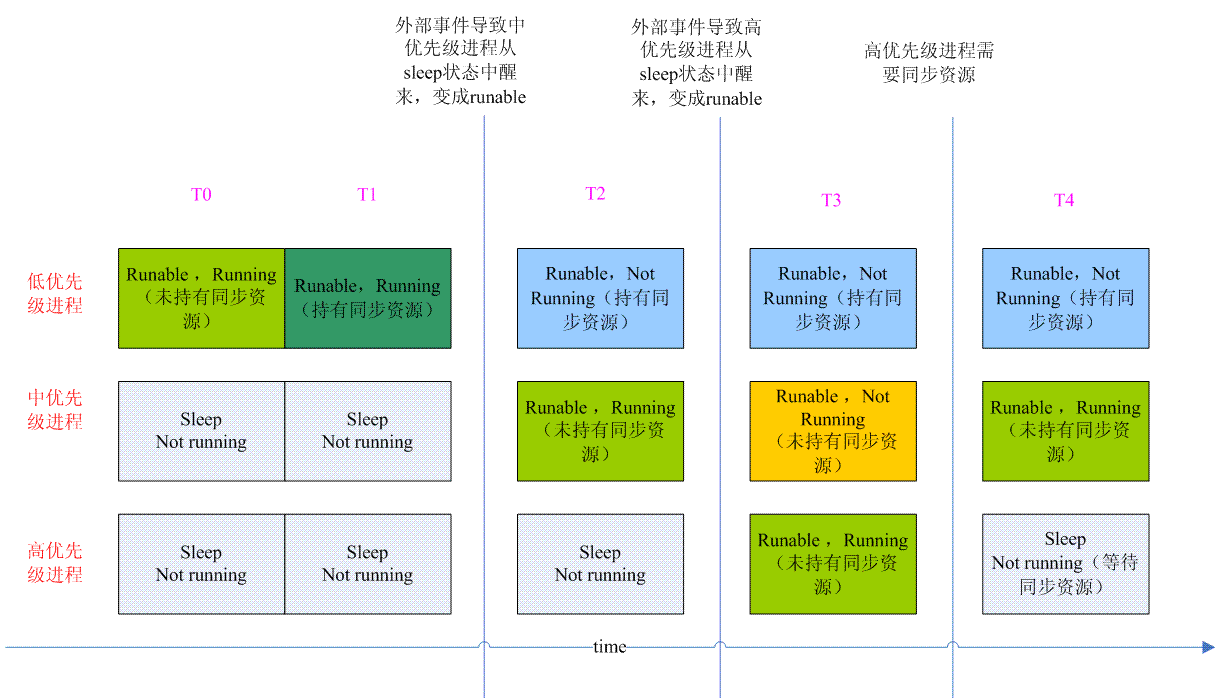
低优先级进程和高优先级进程都需要访问一个公共资源,因此需要一个mutex来保护对该公共资源的访问。
T0时刻,只有低优先级进程处于可运行状态,运行过程中,在T1时刻,低优先级进程访问公共资源,并且持有了mutex lock,T2时刻,由于外部事件,导致中优先级进程进入可运行状态,中优先级进程就绪进入可运行状态,由于优先级高于正在运行的低优先级进程,低优先级进程被抢占(没有unlock mutex),中优先级进程被调度执行。同样地T3时刻,由于外部事件,高优先级进程抢占中优先级进程。高优先级进程运行到T4时刻,需要访问公共资源,但该资源被更低优先级的进程所拥有,高优先级进程只能被挂起等待该资源,而此时处于可运行状态的线程中,中优先级进程由于优先级高而被调度执行。
上述现象中,优先级高的进程要等待优先级低的进程完之后才能被调度,更加严重的是如果中优先级进程执行很费时的操作,显然高优先级进程的被调度时机就不能保证,整个实时调度的性能就很差了。
为了解决上述由于优先级翻转引起的问题,很多操作系统引入了优先级继承(Priority Inheritance)的解决方法。优先级继承的方法是这样的,当高优先级进程在等待低优先级的进程程占用的竞争资源时,为了使低优先级的进程能够尽快获得调度运行(以便释放高优先级进程需要的竞争资源),由操作系统kernel把低优先级进程的优先级提高到等待竞争资源高优先级进程的优先级。
OK,了解完这些内容之后,我们回到了futex。linux内核提供了一个叫做快速用户空间互斥(Fast User-Space Mutexes)的锁的机制,简称futex,通过这样的机制用户空间程序可以实现对互斥资源的快速访问。为什么提供futex这样的机制?如何使用?在用户空间如何互斥?为何能够快速?问题太多了,下次我会启动一个专题来描述futex。
八、process credentials
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
current->flags &= ~PF_NPROC_EXCEEDED;retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
上面的这段代码主要是处理如何复制新创建进程的credentials。在task struct数据结构中,下面的数据结构描述了进程这个对象的credentials:
const struct cred __rcu *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task
* credentials (COW) */
虽然本网站的process credentials描述了一些进程credentials的相关知识,但那是基于2.6.29版本之前的描述。随着内核的演进,从2.6.29版本开始,内核对于credential有了进一步的抽象。首先,credential不再是进程特有的,而是内核对象(进程、file、socket等)的一个属性集合。而这些内核对象的属性被分成两类:一类是该对象作为动作的发起者,操作其他内核对象时候需要用的credential属性,被称为subjective context。另外一类是本内核对象被其他内核对象操作时候需要用到的credential属性,被称为objective context。举一个简单的例子:对于内核中的进程对象,可能存在下面的动作:
1、该进程访问文件系统中的文件
2、在进行文件的asynchronous I/O操作的时候,文件会向进程发送信号。
对于进程这个内核对象而言,在上面的场景1中,要使用进程的subjective context,而在场景2中,使用进程的objective context。内核中,struct cred就是对credential的抽象,进程描述符(struct task_struct)、文件描述符(struct file )这些内核对象都需要定义一个struct cred的成员来代表该对象的credential信息。OK,了解了上述信息之后,我们可以继续讲述task struct数据结构中的credentials成员。在进程对象在操作其他内核对象时候使用cred成员,而在其他对象操作该进程对象的时候,需要获取该进程的credential的时候,需要使用real_cred成员。
在copy process credential之前首先进行资源检查
1、该用户是否已经创建了太多的进程,如果没有超出了resource limit,那么继续fork
2、如果超出了resource limit,但user ID是root的话,没有问题,继续
3、如果不是root,但是有CAP_SYS_RESOURCE或者CAP_SYS_ADMIN的capbility,也OK,否则的话fork失败
检查完成之后就正式开始copy credential了(注:略去CONFIG_KEYS的代码,内核中支持密钥相关的操作值得用一篇单独的文档来描述,此外,为了降低文档长度,删除了debug相关的代码):
int copy_creds(struct task_struct *p, unsigned long clone_flags)
{
struct cred *new;
int ret;if ( clone_flags & CLONE_THREAD ) { //创建线程相关的代码
p->real_cred = get_cred(p->cred);
get_cred(p->cred); //对credential描述符增加两个计数,因为新创建线程的cred和real_cred都指向父进程的credential描述符
atomic_inc(&p->cred->user->processes); //属于该user的进程/线程数目增加1
return 0;
}new = prepare_creds(); //后段的代码是和fork进程相关。prepare_creds是创建一个当前task的subjective context(task->cred)的副本。
if (!new)
return -ENOMEM;if (clone_flags & CLONE_NEWUSER) {//如果父子进程不共享user namespace,那么还需要创建一个新的user namespace
ret = create_user_ns(new);
if (ret < 0)
goto error_put;
}atomic_inc(&new->user->processes);
p->cred = p->real_cred = get_cred(new); //和线程的处理类似,只不过进程需要创建一个credential的副本
return 0;error_put:
put_cred(new);
return ret;
}
对于创建线程,所谓copy,也就是共享,在之前的task struct进行copy的时候,credential相关的两个指针都已经是指向同样的struct cred数据结构,完成了共享的操作(被创建进程/线程的real_cred指向其父进程的real_cred,被创建进程/线程的cred指向其父进程的cred),这些需要做一些修正:
1、被创建进程/线程的real_cred指向其父进程的cred。具体原因TODO
2、修正credential描述符的reference count
对于创建进程,内核会分配一个新的cred描述符,copy 父进程的credentials,也就是说,不是共享cred描述符,而的确是copy的动作了。如果本次fork也携带了CLONE_NEWUSER参数,打算创建一个新的user namespace,那么父子进程的username space也需要独立开来,
九、进程创建总数限制
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
nr_threads是系统当前的线程数目;max_threads是系统允许容纳的最大的线程数。由于资源(CPU、memory)受限,系统不可能无限制的创建线程,否则,系统的memory可能会被进程的内核栈消耗掉。
在系统初始化的时候(fork_init),会根据当前系统中的memory对该值进行设定。
max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE);
if (max_threads < 20) // 最小也会被设定为20
max_threads = 20;
max_threads可以由用户进行设定。在/proc/sys目录下保存着若干的内核参数,该目录下的kernel/threads-max文件就是对系统内的可以创建的最大线程数的限制。
十、模块处理
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
struct thread_info数据结构中的exec_domain成员指向了当前进程/线程的execution domain descriptor。linux kernel有一个很好的设计就是允许在其他操作系统上编译的程序在GNU/linux上执行。对于DOS或者Windows这样的操作系统,GNU/linux支持起来有些困难,多半是通过用户空间的仿真来做。但是对于POSIX兼容的操作系统,由于接口API是相同的,GNU/linux应该不会花费太多的力气,只需要处理系统调用的具体细节问题或者各种信号的编码问题。这些信息在kernel中用struct exec_domain抽象。
既然是共享了父进程的exec_domain,那么需要通过try_module_get去增加reference count(具体的copy在copy thread info的时候已经完成了)。
十一、per-task delay accounting的处理
delayacct_tsk_init(p);
delayacct是一个缩写,是指per-task delay accounting。这个feature是统计每一个task的等待系统资源的时间(例如等待CPU、memeory或者IO)。这些统计信息有助于精准的确定task访问系统资源的优先级。
一个进程/线程可能会因为下面的原因而delay:
1、该进程/线程处于runnable,但是等待调度器调度执行
2、该进程/线程发起synchronous block I/O,进程/线程处于阻塞状态,直到I/O的完成
3、进程/线程在执行过程中等待page swapping in。由于内存有限,系统不可能把进程的各个段(正文段、数据段等)都保存在物理内存中,当访问那些没有在物理内存的段的地址的时候,就会有磁盘操作,导致进程delay,这里有个专业的术语叫做capacity misses
4、进程/线程申请内存,但是由于资源受限而导致page frame reclaim的动作。
系统为何对这些delay信息进行统计呢?主要让系统确定下列的优先级的时候更有针对性:
1、task priority。如果该进程/线程长时间的等待CPU,那么调度器可以调高该任务的优先级。
2、IO priority。如果该进程/线程长时间的等待I/O,那么I/O调度器可以调高该任务的I/O优先级。
3、rss limit value。引入虚拟内存后,每个进程都拥有4G的地址空间。系统中有那么多进程,而物理内存就那么多,不可能让每一个进程虚拟地址(page)都对应一个物理地址(page frame)。没有对应物理地址的那部分虚拟地址的实际内容应该保存在文件或者swap设备上,一旦要访问该地址,系统会产生异常,并处理好分配page frame,页表映射,copy磁盘内容到page frame等一系列动作。rss的全称是resident set size,表示有物理内存对应的虚拟地址空间。由于物理内存资源有限,各个进程要合理使用。rss limit value定义了各个进程rss的上限。
struct task_delay_info *delays;
进程描述符中的delays成员记录了该task的delay统计信息,delayacct_tsk_init就是对该数据结构进程初始化。本文先简单描述概念,后续会有专门的文件来描述进程的统计信息。
十二、复制进程描述符的flag
static void copy_flags(unsigned long clone_flags, struct task_struct *p)
{
unsigned long new_flags = p->flags;new_flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER);
new_flags |= PF_FORKNOEXEC;
p->flags = new_flags;
}
copy_flags函数用来copy进程的flag,大部分的flag都是直接copy,但是下面的几个是例外:
1、PF_SUPERPRIV,这个flag是标识进程曾经使用了super-user privileges(并不表示该进程有超级用户的权限)。对于新创建的进程,当然不会用到super-user privileges,因此要清掉。
2、清除PF_WQ_WORKER标识。PF_WQ_WORKER是用来标识该task是一个workqueue worker。如果新创建的内核线程的确是一个workqueue worker的话,那么在其worker thread function(worker_thread)中会进行设定的。具体worker、workqueue等概念请参考Concurrency-managed workqueues相关的描述。
3、设定PF_FORKNOEXEC标识,表明本进程/线程正在fork,还没有执行exec的动作。
原创文章,转发请注明出处。蜗窝科技,www.wowotech.net。
标签: process management do_fork
评论:
2014-11-06 13:53
1. 定时获取电量,是否有必要开线程?
线程的开销是比较大的,起一个timer反而会更好。
2. 如果真的需要线程的话,suspend和resume不需要处理,就算你处理了,也是多余的。因为当执行到driver的suspend时,thread早已被PM core freeze掉,当执行到driver的resume时,kthread_start是无法生效的,还得等到PM core后续的处理。
3. 如果真的需要在在suspend和resume中start和stop线程,也没关系,什么意外都不会发生。
2014-11-06 14:09
当然,即便如此,使用线程也不是一个好的方法,可以考虑workqueue。
2014-11-06 14:25
IRQF_ONESHOT one shot本身的意思的只有一次的,结合到中断这个场景,则表示中断是一次性触发的,不能嵌套。对于primary handler,当然是不会嵌套,但是对于threaded interrupt handler,我们有两种选择,一种是mask该interrupt source,另外一种是unmask该interrupt source。一旦mask住该interrupt source,那么该interrupt source的中断在整个threaded interrupt handler处理过程中都是不会再次触发的,也就是one shot了。这种handler不需要考虑重入问题。
具体是否要设定one shot的flag是和硬件系统有关的,我们举一个例子,比如电池驱动,电池里面有一个电量计,是使用HDQ协议进行通信的,电池驱动会注册一个threaded interrupt handler,在这个handler中,会通过HDQ协议和电量计进行通信。对于这个handler,通过HDQ进行通信是需要一个完整的HDQ交互过程,如果中间被打断,整个通信过程会出问题,因此,这个handler就必须是one shot的。
2014-11-05 19:57
2014-11-05 20:15
首先第一点,你现在的driver你指的是什么?你指的是driver的probe函数吗?
我的理解,你在driver中启动了一个线程,那么这个线程就是独立于你这个driver存在的啦。这个线程的调度就依赖于linux的进程调度,不依赖于之前的driver,除非有其他的信号量或者其他的通信。
2014-11-05 21:52
2014-11-06 13:28
2014-11-05 22:47
1、driver中创建的内核线程上下文
2、调用进程的上下文(xxx_read, xxx_write等函数)
3、中断上下文
4、softirq context
内核驱动的某个函数也有可能根据运行时候的调用情况属于多个上下文,我们必须动态的来看待driver的代码。
你的问题是:请问在schedule出去这3秒钟内,driver中其它函数还能被调用么?其实,如果driver的其他函数不属于这个内核线程上下文,那么它们当然是自由的被其他进程调用,亦或由于响应中断或者softirq而调用。
2016-04-07 09:34
2016-04-08 08:48
1、A进程调用open、read、write等函数,通过系统调用陷入内核态,这时候,B驱动对应的xxx_open、xxx_read、xxx_write函数被调用,在这种情况下,驱动运行在进程A的进程上下文,当然使用了A进程的内核栈。
2、A进程在用户空间欢快的执行,但是B驱动的中断来了,打断A进程的执行,虽然这时候current是A进程,在内核态执行的是B驱动的interrupt handler,而且使用的也是A进程的内核栈,但是,这时候是中断上下文
因此,不是说驱动使用了某个进程的内核栈就能说是进程上下文,因此,我反对“内核栈上下文“这种表述
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2019-06-06 14:54