
Linux读写锁逻辑解析
作者:OPPO内核团队 发布于:2023-5-29 20:57 分类:内核同步机制
一、Linux为何会引入读写锁?
除了mutex,在linux内核中,还有一个经常用到的睡眠锁就是rw semaphore(后文简称为rwsem),它到底和mutex有什么不同呢?为何会有rw semaphore?无他,仅仅是为了增加内核的并发,从而增加性能而已。Mutex严格的限制只有一个thread可以进入临界区,但是实际应用中,有些场景对共享资源的访问可以严格区分读和写的,并且是读多写少,这时候,其实多个读的thread同时进入临界区是OK的,使用mutex则限制一个线程进入临界区,从而导致性能的下降。
本文会描述linux5.15.81中读写锁的数据结构和逻辑过程。
二、如何抽象读写锁的数据结构?
下图可以抽象rwsem相关的数据结构:

一个rwsem对象需要记录两种数据:
1、读写锁的状态信息
2、和该读写锁相关的任务信息
我们先看看读写锁的状态。读写锁状态字需要分别记录读锁和写锁的状态:由于多个reader可以同时处于临界区,所以对于reader-owned的场景,读锁状态变成了一个counter,来记录临界区内reader的数量,counter等于0表示读锁为空锁状态。对于writer,其行为和互斥锁一致,因此其写锁状态和mutex一样,仍然使用一个bit表示。
和读写相关的任务有两类,一类是已经持锁的线程(即在临界区的线程),另外一类是无法持锁而需要等待的任务。对于writer持锁情况,由于排他性,我们很清楚的知道是哪个task持锁,那么一个task struct指针就足够了记录owner了。然而对于读侧可以多个reader进入临界区,那么owner们需要组成一个队列才可以记录每一个临界区的reader。不过在实际的rwsem实现中,由于跟踪owner们开销比较大,因此也是用一个task struct指针指向其一。具体linux代码是这样处理的:reader进入的时候会设置owner task,但是离开读临界区并不会清除task指针。这样,实际上对于读,owner task应该表示该任务曾经拥有该锁,并不表示是目前持锁的owner task,也有可能已经离开临界区,甚至该任务已经销毁。
如果持锁失败,无法进入临界区,我们有两种选择:
1、乐观自旋
2、挂入等待队列
两种选择各有优点和缺点,总结如下:
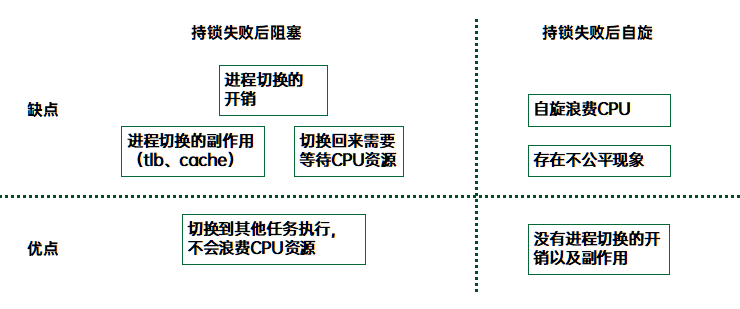
在5.15的内核中,只有在write持锁路径上有乐观自旋的操作,reader路径没有,只有偷锁的操作。当乐观自旋失败后就会挂入等待队列,阻塞当前线程。(乐观自旋功能有一个很有意思的发展过程,从开始支持writer的乐观自旋,到支持全场景的乐观自旋,然后又回到最初,有兴趣可以查阅内核的patch了解详情)
在了解了rwsem的基本概念之后,我们一起来看看struct rw_semaphore数据结构,其成员描述如下:
|
成员 |
描述 |
|
atomic_long_t count |
在64位平台上,成员count的各个bit解释如下: * Bit 0 - 写锁比特 * Bit 1 - 标记等待队列的状态 * Bit 2 - 标记handoff状态 * Bits 3-7 - reserved * Bits 8-62 - 55-bit reader counter(读锁counter) * Bit 63 - read fail bit,溢出检查bit 为了能够检测reader数量溢出问题,我们在MSB设置了保护位,程序本身并不设置它,但是如果太多的reader进入临界区,会导致该bit变成1。当然,正常情况下,这个guard bit永远不会被设置,一旦被设置,作为保护措施,这时候reader也会被禁止进入临界区。 除了持锁状态的比特,count成员还有两个用来标记其他锁状态的bit。Bit 1用来标记该rwsem的等待队列是否有waiter任务,bit 2用来支持锁的递交功能,后面会详述。 |
|
atomic_long_t owner |
owner这个成员有两个作用: 1、记录该rwsem对象被哪一个task持有(仅writer有效,对reader仅仅是debug的时候提供信息而已)。如果等于NULL表示还没有被任何一个任务持有。 2、由于task struct地址是L1_CACHE_BYTES对齐的,因此这个成员(实际是task struct指针)有若干的LSB可以被用于标记状态(在ARM64平台上,L1_CACHE_BYTES是64字节,因此LSB 6-bit可用于保存rwsem状态信息。具体的状态包括: RWSEM_READER_OWNED:说明当前rwsem被一个或者一组reader所持有。 RWSEM_NONSPINNABLE:在该rwsem上不执行乐观自旋的操作,关于乐观自旋功能,后面会详述。 |
|
struct optimistic_spin_queue osq |
在配置了CONFIG_RWSEM_SPIN_ON_OWNER的时候,rwsem支持乐观自旋机制,osq成员就是乐观自旋需要持有的MCS锁。 |
|
spinlock_t wait_lock |
用于保护等待链表操作wait_list的自旋锁 |
|
struct list_head wait_list |
等待队列。该队列上的任务都是处于阻塞状态,等待临界区清空后唤醒队列上的任务。 |
|
void *magic |
和debug相关的成员。如果开启了CONFIG_DEBUG_RWSEMS配置项,初始化的时候magic会被设置为rwsem的地址,用来防止操作未初始化的rwsem。 |
|
Struct lockdep_map dep_map |
和debug相关的成员 |
由于是sleep lock,我们需要把等待的任务挂入队列。在内核中,struct rwsem_waiter用来抽象等待rwsem的任务,其成员描述如下:
|
成员 |
描述 |
|
struct list_head list |
挂入rwsem等待队列(wait_list成员)的节点 |
|
struct task_struct *task |
等待该rwsem的任务 |
|
enum rwsem_waiter_type type |
该对象为何挂入等待队列?是reader还是writer? |
|
unsigned long timeout |
在队列中等待超时时间,目前设置为4ms |
|
bool handoff_set |
如果该任务等待对象的handoff_set等于true,那么说明该对象就是该读写锁的第一顺位继承人,在唤醒之后可以乐观自旋去持锁 |
三、Rwsem外部接口API为何?
Rwsem模块的外部接口API如下:
|
接口API |
描述 |
|
初始化接口API |
|
|
init_rwsem |
初始化rwsem对象,该rwsem对象已经由调用者定义。 |
|
__init_rwsem |
基本类似init_rwsem,但允许更灵活的设置debug信息 |
|
DECLARE_RWSEM |
定义并初始化一个rwsem对象 |
|
__RWSEM_INITIALIZER |
当rwsem嵌入其他数据结构中的时候,通过该API可以初始化数据结构中内嵌的rwsem对象 |
|
获取rwsem锁的API |
|
|
down_read |
Reader获取rwsem锁的接口,如果不成功,进入D状态 |
|
down_read_interruptible |
Reader获取rwsem锁的接口,如果不成功,进入S状态 |
|
down_read_killable |
Reader获取rwsem锁的接口,如果不成功,进入KILLABLE状态 |
|
down_read_trylock |
Reader尝试获取rwsem锁的接口,如果不成功,不阻塞,返回0,如果成功持锁,返回1 |
|
down_write |
Writer获取rwsem锁的接口,如果不成功,进入D状态 |
|
down_write_killable |
Writer获取rwsem锁的接口,如果不成功,进入KILLABLE状态 |
|
down_write_trylock |
Writer尝试获取rwsem锁的接口,如果不成功,不阻塞,返回0,如果成功持锁,返回1 |
|
释放rwsem锁的API |
|
|
up_read |
Reader释放读锁,离开读临界区。 |
|
up_write |
Writer释放写锁,离开写临界区。 |
|
downgrade_write |
当前是写锁上下文,在调用该函数之后,当前写锁可以降级为读锁。 |
|
获取rwsem锁状态的API |
|
|
rwsem_is_locked |
该rwsem是否处于locked的状态 |
|
rwsem_is_contended |
该rwsem是否处于被竞争的状态(等待队列至少有一个waiter) |
四、尝试获取读锁
和down_read不一样,down_read_trylock只是尝试获取读锁,如果成功,那么自然是好的,直接返回1,如果失败,也不会阻塞,只是返回0就可以了。代码主逻辑在__down_read_trylock函数中,如下:
|
tmp = RWSEM_UNLOCKED_VALUE; do { if (atomic_long_try_cmpxchg_acquire(&sem->count, &tmp, tmp + RWSEM_READER_BIAS)) {-----A rwsem_set_reader_owned(sem); return 1; } } while (!(tmp & RWSEM_READ_FAILED_MASK));-----B return 0; |
A、tmp的初始值设定为RWSEM_UNLOCKED_VALUE(0值),因此第一次循环是为当前是空锁而做的优化:如果当前的sem->count等于0,那么给sem->count赋值RWSEM_READER_BIAS,标记持锁成功,然后设定owner返回1即可。
B、如果快速获取空锁不成功,这时候tmp已经赋值(等于sem->count),不再是0值了。通过对当前sem->count的值可以判断是否是可以进入临界区。持读锁失败的情况包括:
|
Rwsem标记 |
说明 |
|
RWSEM_WRITER_MASK |
writer持锁 |
|
RWSEM_FLAG_WAITERS |
有writer或者reader在等待队列中了 |
|
RWSEM_FLAG_HANDOFF |
锁在转交过程中(即已经有了预定锁的owner) |
|
RWSEM_FLAG_READFAIL |
有太多的reader在临界区,应该是异常状态 |
如果判断可以进入读临界区(临界区仅有reader并且没有writer等待的场景),那么重新进入循环,如果sem->count保持不变,那么可以持锁成功,给进入临界区的reader数目加一,并设置owner task和reader持锁标记(non-spinnable比特保持不变)。如果这期间有其他线程插入修改了count值,那么需要再次判断是否能持读锁,重复上面的循环。如果判断不可以进入临界区,退出循环,持锁失败。
五、获取读锁
Reader获取读锁的代码主要在__down_read_common函数中,如下:
|
if (!rwsem_read_trylock(sem, &count)) {---快速路径 if (IS_ERR(rwsem_down_read_slowpath(sem, count, state)))---慢速路径 return -EINTR; } |
1、快速路径
rwsem_read_trylock是快速路径,代码如下:
|
*cntp = atomic_long_add_return_acquire(RWSEM_READER_BIAS, &sem->count);---A if (WARN_ON_ONCE(*cntp < 0))----B rwsem_set_nonspinnable(sem); if (!(*cntp & RWSEM_READ_FAILED_MASK)) {----C rwsem_set_reader_owned(sem); return true;---持锁成功 } return false;---持锁失败 |
A、reader直接会给sem->count加RWSEM_READER_BIAS来增加读临界区的线程个数,当然这有可能失败,那么就进入慢速路径(需要回退错误增加读临界区线程数量)。如果恰好能够进入临界区,那么就直接设定owner返回即可。注意:这里*cntp保存了atomic add之后的新值。rwsem_down_read_slowpath会使用这个新值作为参数。
B、当reader的数量过多(以至于都溢出了)的时候,需要禁止乐观自旋。
C、这里是持锁成功的路径。RWSEM_READ_FAILED_MASK上一节已经解释,这里不再赘述。这里需要注意的是rwsem_set_reader_owned函数中flag的设定,由于reader进入临界区,因此RWSEM_READER_OWNED也需要设定。RWSEM_RD_NONSPINNABLE标记保持不变。
在快速路径中,有两种常见的情况会持锁成功:一种是空锁,另外一种是没有任何waiter等待的纯reader并发。
2、慢速路径
如果快速路径持锁失败,那么进入慢速路径。慢速路径代码比较长,我们分段解析。首先是防止等待队列中waiter任务饿死的代码:
|
if ((atomic_long_read(&sem->owner) & RWSEM_READER_OWNED) && (rcnt > 1) && !(count & RWSEM_WRITER_LOCKED)) goto queue; |
如果当前的锁被reader持有(至少有一个reader在临界区),那么不再乐观偷锁而是直接进行挂等待队列的操作。为何怎么做呢?因为需要在饿死waiter和reader吞吐量上进行平衡。一方面,连续的reader持续偷锁的话会饿死等待队列上的任务。另外,在唤醒路径上,被唤醒的top reader会顺便将队列中的若干(不大于256个)reader也同时唤醒,以便增加rwsem的吞吐量。所以这里的reader直接挂入队列,累计多个reader以便可以批量唤醒。
Reader偷锁的场景主要发生在唤醒top waiter的过程中,这时候临界区没有线程,被唤醒的reader或者writer也没有持锁(writer需要被调度到CPU上执行之后才会试图持锁,高负载的场景下,锁被偷的概率比较大,reader是唤醒后立刻持锁,被偷的几率小一点)。具体乐观偷锁(optimistic lock stealing)的代码如下:
|
if (!(count & (RWSEM_WRITER_LOCKED | RWSEM_FLAG_HANDOFF))) {-----A rwsem_set_reader_owned(sem);-------------B if ((rcnt == 1) && (count & RWSEM_FLAG_WAITERS)) {-------------C raw_spin_lock_irq(&sem->wait_lock); if (!list_empty(&sem->wait_list)) rwsem_mark_wake(sem, RWSEM_WAKE_READ_OWNED, &wake_q); raw_spin_unlock_irq(&sem->wait_lock); wake_up_q(&wake_q); } return sem; } |
A、所谓偷锁就是不乐观自旋(要有排队),不管先来后到,直接获取锁。允许偷锁的场景是这样的:临界区没有writer持锁,也没有设置handoff,正在唤醒top waiter的过程中,并且有任务在等待队列的情况。这时候进入慢速路径的reader可以先于top waiter唤醒之前把锁偷走。需要特别说明的是:这时候reader counter已经加一,还是尽量让reader偷锁成功,否则还需要回退。
B、当前线程获得了读锁,需要设置owner,毕竟它是临界区的新客
C、如果偷锁成功并且它是临界区第一个reader,那么它还会把等待队列中的reader都唤醒(前提是top waiter不是writer),带领大家一起往前冲(这里会打破FIFO的顺序,惩罚了队列中的writer)。具体是通过rwsem_mark_wake来标记唤醒的reader,然后通过wake_up_q将reader唤醒并进入读临界区。为了减低对等待中的writer线程的影响,这时候对reader的并发是受限的,最多可以唤醒MAX_READERS_WAKEUP个reader。
如果偷锁不成功,当前的reader还是需要进入阻塞状态:
|
waiter.task = current; waiter.type = RWSEM_WAITING_FOR_READ; waiter.timeout = jiffies + RWSEM_WAIT_TIMEOUT;--------A raw_spin_lock_irq(&sem->wait_lock); if (list_empty(&sem->wait_list)) {------------B if (!(atomic_long_read(&sem->count) & (RWSEM_WRITER_MASK | RWSEM_FLAG_HANDOFF))) { smp_acquire__after_ctrl_dep(); raw_spin_unlock_irq(&sem->wait_lock); rwsem_set_reader_owned(sem); return sem;------------C } adjustment += RWSEM_FLAG_WAITERS; } rwsem_add_waiter(sem, &waiter);------------D count = atomic_long_add_return(adjustment, &sem->count); |
A、准备好挂入等待队列的rwsem waiter数据,需要特别说明的是这里的timeout时间:目前手机平台的HZ设置的是250,也就是说在触发handoff机制之前waiter需要至少在队列中等待一个tick(4ms)的时间。这里的timeout是指handoff timeout,为了防止偷锁或者自旋导致等待队列中的top waiter有一个长时间的持锁延迟。在timeout时间内,乐观偷锁或者自旋可以顺利进行,但是一旦超时就会设定handoff标记,乐观偷锁或者自旋被禁止,锁的所有权需要递交给等待队列中的top waiter。
B、如果目前等待队列为空,那么要做一些额外的处理。例如入队之前肯定给安排上RWSEM_FLAG_WAITERS这个标记。
C、当然,在入队之前还要垂死挣扎一下(等待队列为空的时候逻辑简单一些,不需要唤醒队列上的wait),看看是不是当前有机可乘,如果是这样,那么就顺势而为,直接持锁成功,而且counter都已经准备好了,前面已经加一了。
D、等待队列非空的时候,逻辑稍微负载一点。调用rwsem_add_waiter函数即可以把当前任务挂入等待队列尾部。这时候也需要把之前武断增加的counter给修正回来了(adjustment初始化为-RWSEM_READER_BIAS)。如果是第一个waiter,也顺便设置了RWSEM_FLAG_WAITERS标记。
在当前线程进入阻塞之前,我们需要进行试图持锁的动作(上面是空队列场景检查,这里的逻辑稍微复杂一点,由于已经入队,这里需要调用rwsem_mark_wake函数来完成阻塞后唤醒的动作),毕竟这时候可能恰好owner离开临界区,变成空锁。
|
if (!(count & RWSEM_LOCK_MASK)) {-------A clear_nonspinnable(sem); wake = true; } if (wake || (!(count & RWSEM_WRITER_MASK) && (adjustment & RWSEM_FLAG_WAITERS)))------B rwsem_mark_wake(sem, RWSEM_WAKE_ANY, &wake_q); raw_spin_unlock_irq(&sem->wait_lock); wake_up_q(&wake_q); |
A、如果这时候发现锁的owner恰好都离开了临界区,那么我们是需要执行唤醒top waiter操作的,唤醒之前需要清除禁止乐观自旋的标记,毕竟目前临界区没有任何线程。
B、除了上面说的场景需要唤醒,在reader持锁并且我们是队列中的第一个waiter的时候,也需要唤醒的动作(唤醒自己)。
阻塞部分的代码逻辑如下:
|
for (;;) { set_current_state(state); if (!smp_load_acquire(&waiter.task)) {---------A break; } if (signal_pending_state(state, current)) {-----B raw_spin_lock_irq(&sem->wait_lock); if (waiter.task) goto out_nolock; raw_spin_unlock_irq(&sem->wait_lock); break; } schedule();------C } __set_current_state(TASK_RUNNING); return sem; |
A、在rwsem_mark_wake函数中我们会唤醒reader并将其等待对象的task成员(waiter.task)设置为NULL。因此,这里如果发现waiter.task等于NULL,那么说明是该线程被正常唤醒,那么从阻塞状态返回,持锁成功。
B、如果在该线程阻塞的时候,有其他任务发送信号给该线程,那么就持锁失败退出。如果已经被唤醒,同时又收到信号,这时候需要首先完成唤醒,持锁成功,然后在其他的合适点再处理该信号。当然,大部分的rwsem都是D状态,也就不需要处理信号了。
C、进入阻塞状态,让调度器选择next task
六、释放读锁
释放读锁的代码逻辑主要在__up_read函数中,如下:
|
tmp = atomic_long_add_return_release(-RWSEM_READER_BIAS, &sem->count); if (unlikely((tmp & (RWSEM_LOCK_MASK|RWSEM_FLAG_WAITERS)) == RWSEM_FLAG_WAITERS)) { clear_nonspinnable(sem); rwsem_wake(sem); } |
需要强调的是:这里仅仅是减去了读临界区的counter计数,并没有清除owner中的task pointer。此外,当等待队列有waiter并且没有writer或者reader在临界区的时候,我们会调用rwsem_wake来唤醒等待队列的线程。因为临界区已经没有线程,所以需要清除nonspinable标记。唤醒的动作主要是通过rwsem_mark_wake和wake_up_q来完成的,wake_up_q比较简单,我们就不赘述了,主要看看rwsem_mark_wake的逻辑。
我们首先给出wake type的解释:
|
Wake type |
说明 |
|
RWSEM_WAKE_ANY |
唤醒等待队列头部的waiter(一个writer或者若干reader) |
|
RWSEM_WAKE_READERS |
唤醒等待队列头部的若干readers |
|
RWSEM_WAKE_READ_OWNED |
同RWSEM_WAKE_READERS,只不过唤醒者已经持有读锁。 |
在RWSEM_WAKE_READERS场景中,多个reader被唤醒,并且当前很可能是空锁状态,为了防止writer抢锁,因此会先让top waiter持有读锁,然后慢慢处理后续。RWSEM_WAKE_READ_OWNED则没有这个顾虑,因为唤醒者已经持有读锁。
在释放读锁的场景中,rwsem_mark_wake使用的是RWSEM_WAKE_ANY参数,具体的代码如下:
|
waiter = rwsem_first_waiter(sem); if (waiter->type == RWSEM_WAITING_FOR_WRITE) { if (wake_type == RWSEM_WAKE_ANY) { wake_q_add(wake_q, waiter->task); } return; } |
这段代码是处理top waiter是writer的逻辑。这时候,如果wake type是RWSEM_WAKE_ANY,即不关心唤醒的是reader还是writer,只要唤醒等待队列头部的waiter就好。如果top waiter是writer,我们只需要将这个writer唤醒即可,不需要修改锁的状态,出队等操作,这些都是在唤醒之后完成。如果wake type是其他两种类型(都是唤醒reader的),那么就直接返回。也就是说在rwsem_mark_wake想要唤醒reader的场景中,如果top waiter是writer,那么将不会唤醒任何reader线程。如果top waiter是reader的话,那么基本上是需要唤醒一组reader了。
|
if (wake_type != RWSEM_WAKE_READ_OWNED) {----------A struct task_struct *owner; adjustment = RWSEM_READER_BIAS; oldcount = atomic_long_fetch_add(adjustment, &sem->count); if (unlikely(oldcount & RWSEM_WRITER_MASK)) {---------B(持锁失败) if (!(oldcount & RWSEM_FLAG_HANDOFF) && time_after(jiffies, waiter->timeout)) { adjustment -= RWSEM_FLAG_HANDOFF; } atomic_long_add(-adjustment, &sem->count);设置handoff并恢复reader count return; } owner = waiter->task;-------------C(持锁成功) __rwsem_set_reader_owned(sem, owner); } |
A、执行到这里,我们需要唤醒等待队列头部的若干reader线程去持锁。由于writer有可能会在这个阶段偷锁,因此,这里我们会先让top waiter(reader)持锁,然后再慢慢去计算到底需要唤醒多少个reader并将其唤醒。如果当前线程已经持有了读锁(wake type的类型是RWSEM_WAKE_READ_OWNED),则不需要提前持锁,直接越过这部分的逻辑即可。
B、如果的确发生了writer通过乐观自旋偷锁,那么我们需要检查设置handoff的条件。如果reader被writer阻塞太久,那么我们设定handoff标记,要求rwsem的writer停止通过乐观自旋偷锁,将锁的所有权转交给top waiter(reader)
C、上面已经向rwsem的count增加reader计数,这里把owner也设定上(flag也同步安排,这里non-spinnable bit保持不变)。随后top waiter的reader会唤醒若干队列中的non top reader,但是它们都不配拥有名字。
读锁已经安排的妥妥的了,下面就是慢慢唤醒等待队列的reader了。我们通过两步来完成唤醒:
1、将等待队列中的reader摘下放入到一个单独的列表中(wlist),同时对reader进行计数。后续这个计数会写入rwsem 的reader counte域。
2、对于wlist中的每一个waiter对象(reader任务),清除waiter->task并将它们放入wake_q以便稍后被唤醒。
我们先看第一轮计算唤醒reader个数的计数:
|
INIT_LIST_HEAD(&wlist); list_for_each_entry_safe(waiter, tmp, &sem->wait_list, list) { if (waiter->type == RWSEM_WAITING_FOR_WRITE) continue;-----------------A woken++; list_move_tail(&waiter->list, &wlist); if (woken >= MAX_READERS_WAKEUP)---------B break; } adjustment = woken * RWSEM_READER_BIAS - adjustment;--------C |
A、对于rwsem,其公平性是区分读写的。对于读,如果top waiter是reader,那么所有的reader都可以进入临界区,不管reader在队列中的顺序。对于writer,我们要确保其公平性,我们要按照writer在队列中的顺序依次持锁。根据上面的原则,我们会略过队列中的writer,将尽量多的reader唤醒并进入临界区
B、唤醒数量不能大于256,否则会饿死writer
C、根据唤醒的reader数量计算count调整值
Rwsem的count成员还有一些bit用来标记当前读写锁状态(waiter bit和handoff bit),也需要根据情况进行调整:
|
oldcount = atomic_long_read(&sem->count); if (list_empty(&sem->wait_list)) {---------A adjustment -= RWSEM_FLAG_WAITERS; if (oldcount & RWSEM_FLAG_HANDOFF) adjustment -= RWSEM_FLAG_HANDOFF; } else if (woken) { if (oldcount & RWSEM_FLAG_HANDOFF)-----B adjustment -= RWSEM_FLAG_HANDOFF; } if (adjustment)--------------C atomic_long_add(adjustment, &sem->count); |
A、如果等待队列为空了,肯定是要清除waiter flag,同时要清除handoff flag,毕竟没有什么等待任务可以递交锁了。
B、虽然队列非空,但已经唤醒了reader,那么需要清除handoff标记,毕竟top waiter已经被唤醒去持锁了,完成了锁的递交。
C、完成sem->count的调整
第二轮将唤醒的reader加入唤醒队列,具体的逻辑如下:
|
list_for_each_entry_safe(waiter, tmp, &wlist, list) { struct task_struct *tsk; tsk = waiter->task; get_task_struct(tsk); smp_store_release(&waiter->task, NULL); wake_q_add_safe(wake_q, tsk); } |
主要是把等待任务对象的task成员设置为NULL,唤醒之后根据这个成员来判断是正常唤醒还是异常唤醒路径。
这里对唤醒等待队列上的reader和writer处理是不一样的。对于writer,唤醒之然后被调度到之后再去试图持锁。对于reader,在唤醒路径上就已经持锁(增加rwsem的reader count,并且修改了相关的状态标记)。之所以这么做主要是降低调度的开销,毕竟若干个reader线程被唤醒之后,获得CPU资源再去持锁,持锁失败然后继续阻塞,这些都会增加调度的负载。
七、尝试获取写锁
和down_write不一样,down_write_trylock只是尝试获取写锁,如果成功,那么自然是好的,直接返回1,如果失败,也不会阻塞,只是返回0就可以了。代码主逻辑在rwsem_write_trylock函数中,如下:
|
long tmp = RWSEM_UNLOCKED_VALUE; if (atomic_long_try_cmpxchg_acquire(&sem->count, &tmp, RWSEM_WRITER_LOCKED)) { rwsem_set_owner(sem); return true; } return false; |
tmp的初始值设定为RWSEM_UNLOCKED_VALUE(0值),对于writer而言,只有rwsem是空锁的时候才能进入临界区。如果当前的sem->count等于0,那么给sem->count赋值RWSEM_WRITER_LOCKED,标记持锁成功,并且把owner设定为当前task。
atomic_long_try_cmpxchg_acquire函数有三个参数,从左到右分别是value,old和new。该函数会对比value和old,如果相等那么执行赋值value=new同时返回true。如果不相等,不执行赋值操作,直接返回false。
八、获取写锁
Writer获取写锁的代码主要在__down_write_common函数中,如下:
|
static inline int __down_write_common(struct rw_semaphore *sem, int state) { if (unlikely(!rwsem_write_trylock(sem))) { if (IS_ERR(rwsem_down_write_slowpath(sem, state))) return -EINTR; } return 0; } |
rwsem_write_trylock(快速路径)上一节已经描述,我们主要看慢速路径的逻辑(乐观自旋我们下面会讲,这里暂且略过):
|
waiter.task = current; waiter.type = RWSEM_WAITING_FOR_WRITE; waiter.timeout = jiffies + RWSEM_WAIT_TIMEOUT; waiter.handoff_set = false; raw_spin_lock_irq(&sem->wait_lock); rwsem_add_waiter(sem, &waiter); |
首先准备好一个等待任务对象(栈上)并初始化,将其挂入等待队列。在真正睡眠之前,我们需要做一些唤醒动作(和reader持锁过程类似,有可能在挂入等待队列的时候,临界区线程恰好离开,变成空锁),具体逻辑如下:
|
if (rwsem_first_waiter(sem) != &waiter) {----------A count = atomic_long_read(&sem->count); if (count & RWSEM_WRITER_MASK)---------B goto wait; rwsem_mark_wake(sem, (count & RWSEM_READER_MASK)----C ? RWSEM_WAKE_READERS : RWSEM_WAKE_ANY, &wake_q); if (!wake_q_empty(&wake_q)) {---------D raw_spin_unlock_irq(&sem->wait_lock); wake_up_q(&wake_q); wake_q_init(&wake_q); /* Used again, reinit */ raw_spin_lock_irq(&sem->wait_lock); } } else { atomic_long_or(RWSEM_FLAG_WAITERS, &sem->count); } |
A、如果我们是等待队列的top waiter(等待队列从空变为非空),那么需要设定RWSEM_FLAG_WAITERS标记,直接进入后续阻塞逻辑。如果不是,那么逻辑要复杂点,需要扫描一下之前挂入队列的任务,看看是否需要唤醒。
B、如果是writer持锁,那么不需要任何唤醒动作,毕竟writer是排他的
C、如果是空锁状态,我们需要唤醒top waiter(RWSEM_WAKE_ANY,top writer或者reader们)。你可能会疑问:为何空锁还要唤醒等待队列的线程?当前线程快马加鞭去持锁不就OK了吗?这主要是和handoff逻辑相关,这时候更应该持锁的是等待队列中设置了handoff的那个waiter,而不是当前writer。如果是reader在临界区内,那么,我们将唤醒本等待队列头部的所有reader(RWSEM_WAKE_READERS)。
D、上面仅仅是标记唤醒者,这里的代码段完成具体的唤醒动作
下面进入具体writer的阻塞过程:
|
for (;;) { if (rwsem_try_write_lock(sem, &waiter)) { break;--------------------A } raw_spin_unlock_irq(&sem->wait_lock); if (signal_pending_state(state, current))----B goto out_nolock; if (waiter.handoff_set) {--------------C enum owner_state owner_state; preempt_disable(); owner_state = rwsem_spin_on_owner(sem); preempt_enable(); if (owner_state == OWNER_NULL) goto trylock_again; } schedule();-----------------D set_current_state(state); trylock_again: raw_spin_lock_irq(&sem->wait_lock);-------E } |
A、调用rwsem_try_write_lock试图持锁,如果成功持锁则退出循环,不再阻塞。有两个逻辑路径会路过这里。一个是线程持锁失败进入这里,另外一个是阻塞后被唤醒试图持锁。
B、有pending的信号,异常路径退出
C、持锁失败但是设置了handoff,那么该线程对owner进行自旋等待,以便加快锁的传递。
D、进入阻塞状态
E、唤醒之后,重新试图持锁。Writer和reader不一样,writer是唤醒之后自己再通过rwsem_try_write_lock试图持锁,而reader是在唤醒路径上持锁。
rwsem_try_write_lock代码如下:
|
count = atomic_long_read(&sem->count); do { bool has_handoff = !!(count & RWSEM_FLAG_HANDOFF); if (has_handoff) {-----------A if (!first) return false; waiter->handoff_set = true; } new = count; if (count & RWSEM_LOCK_MASK) { if (has_handoff || (!rt_task(waiter->task) && !time_after(jiffies, waiter->timeout))) return false; new |= RWSEM_FLAG_HANDOFF;--------------B } else { new |= RWSEM_WRITER_LOCKED;-----------C new &= ~RWSEM_FLAG_HANDOFF; if (list_is_singular(&sem->wait_list)) new &= ~RWSEM_FLAG_WAITERS; } } while (!atomic_long_try_cmpxchg_acquire(&sem->count, &count, new)); |
A、如果已经设置了handoff,并且自己不是top waiter(top waiter才是锁要递交的对象),返回false,持锁失败。如果是top waiter,那么就设置handoff_set,标记自己就是锁递交的目标任务。
B、如果当前rwsem已经有了owner,那么说明该锁被偷走了。在适当的条件下(等待超时)设置handoff标记,防止后续继续被抢。如果已经设置了handoff就不必重复设置了。
C、如果当前rwsem没有owner,则持锁成功,清除handoff标记并根据情况设置waiter标记。
D、通过原子操作来持锁,成功操作后退出循环,否则是有其他线程插入,需要重复上面的逻辑。
|
if (new & RWSEM_FLAG_HANDOFF) {----------A waiter->handoff_set = true; return false; } list_del(&waiter->list);----------------B rwsem_set_owner(sem); return true; |
至此我们要不获取了锁并清除了handoff bit(B逻辑块),或者没有获取锁,仅仅是设置了handoff bit(A逻辑块)。
九、释放写锁
除了清除了owner task成员,其他逻辑和释放读锁类似,不再赘述。
十、乐观自旋的条件
只有writer在进入慢速路径的时候才会进行乐观自旋,而rwsem_can_spin_on_owner函数用来判断writer是否可以乐观自旋:
|
if (need_resched()) return false;---------A owner = rwsem_owner_flags(sem, &flags);--------B if ((flags & nonspinnable) || (owner && !(flags & RWSEM_READER_OWNED) && !owner_on_cpu(owner))) ret = false;-----C |
A、本cpu上需要reschedule,还自旋个毛线,赶紧去睡眠也顺便触发一次调度
B、读取sem->owner,标记部分保存在flags临时变量中,任务指针保存在owner中
C、如果该rwsem已经禁止了对应的nonspinnable标志,那么肯定是不能乐观自旋了。如果当前rwsem没有禁止,那么需要看看owner的状态。这里需要特别说明的是:为了方便debug,我们在释放读锁的时候并不会清除owner task。也就是说,对于reader而言,owner中的task信息是最后进入临界区的那个reader,仅此而已,实际这个task可能已经离开临界区,甚至已经销毁都有可能。所以,如果rwsem是reader拥有,那么其实判断owner是否在cpu上运行是没有意义的,因此owner是reader的话是允许进行乐观自旋的(ret的缺省值是true),通过超时来控制自旋的退出。如果rwsem是writer拥有,那么owner的的确确是正在持锁的线程,如果该线程没有在CPU上运行(不能很快离开临界区),那么也不能乐观自旋。
十一、rwsem_spin_on_owner
函数rwsem_spin_on_owner的功能是对rwsem的owner task进行乐观自旋(即不断轮询其状态,仅writer有效),详细的代码逻辑如下:
|
owner = rwsem_owner_flags(sem, &flags);-----A state = rwsem_owner_state(owner, flags); if (state != OWNER_WRITER)----B return state; for (;;) {-------自旋的writer线程进行rwsem的状态进行轮询 new = rwsem_owner_flags(sem, &new_flags); if ((new != owner) || (new_flags != flags)) { state = rwsem_owner_state(new, new_flags); break;----------C } if (need_resched() || !owner_on_cpu(owner)) { state = OWNER_NONSPINNABLE; break;----------D } } |
A、在自旋之前,首先要获得初始的状态(owner task指针以及2-bit LSB flag),当这些状态发生变化才好退出自旋。
B、rwsem_owner_state函数会根据当前的owner task和flag判断当前的owner state。owner state的状态总结如下:
|
状态 |
说明 |
|
OWNER_NULL |
当前owner为空 |
|
OWNER_WRITER |
Owner发生修改且当前owner是writer |
|
OWNER_READER |
Owner发生修改且当前owner是reader |
|
OWNER_NONSPINNABLE |
禁止了乐观自旋,主要有两种情况: 1、对于writer-owned,当持锁的writer处于off cpu或者执行writer的cpu需要resched 2、对于reader-owned,超时会禁止乐观自旋 |
只有明确的知道当前rwsem的owner是某个writer线程且没有禁止自旋的时候才开启下面的自旋过程。对于其他情况,例如reader owned的场景,我们不需要spin on owner,直接返回。
C、只要owner task或者flag其一发生变化,这里就会停止轮询,同时也会返回当前的状态,说明停止自旋的原因。例如当owner task(一定是writer)离开临界区的时候会清空rwsem的owner域(owner task和flag会清零),这时候自旋的writer会停止自旋,到外层函数会去试图持锁。当然也有可能是其他自旋writer抢到了锁,owner task从A切到B。无论那种情况,统一终止对owner的自旋。
D、如果当前cpu需要reschedule或者owner task没有正在运行,那么也需要停止自旋
十二、Writer的乐观自旋
和mutex的乐观自旋的概念是类似的,想要进行rwsem的乐观自旋,首先要获取osq锁,只有获得了osq lock才能进入rwsem的乐观自旋,否则自旋在per cpu的mcs lock上。Writer通过rwsem_optimistic_spin完成整个乐观自旋的过程。对于writer owned场景,自旋发生在rwsem_spin_on_owner中,上一节已经描述了,这里我们主要看reader owned的情况,这时候通过for loop不断自旋去持锁:
|
for (;;) {-------显然乐观自旋需要不停的探测状态,所以这里有一个for loop。 enum owner_state owner_state; owner_state = rwsem_spin_on_owner(sem);----在owner task上自旋 if (!(owner_state & OWNER_SPINNABLE)) break;-------------A 自旋失败,return false taken = rwsem_try_write_lock_unqueued(sem);-------B if (taken) break;-------持锁成功,退出for loop, return true 持锁失败,看看是否要退出自旋还是继续。 if (owner_state == OWNER_READER) { if (prev_owner_state != OWNER_READER) {-----------C if (rwsem_test_oflags(sem, RWSEM_NONSPINNABLE)) break;----已经标记了停止乐观自旋flag,自旋失败,return false rspin_threshold = rwsem_rspin_threshold(sem); loop = 0; } else if (!(++loop & 0xf) && (sched_clock() > rspin_threshold)) {----D rwsem_set_nonspinnable(sem); break; } } if (owner_state != OWNER_WRITER) { if (need_resched())---------------E break; if (rt_task(current) && (prev_owner_state != OWNER_WRITER))-------F break; } prev_owner_state = owner_state; } |
A、对于rwsem,只有writer-owned场景能清楚的知道owner task是哪一个。因此,如果是writer-owned场景,会在rwsem_spin_on_owner函数进行自旋。对于非writer-owned场景(reader-owned场景或者禁止了乐观自旋),在rwsem_spin_on_owner函数中会直接返回。从rwsem_spin_on_owner函数返回会给出owner state,如果需要退出乐观自旋,那么这里break掉,自旋失败,下面就准备挂入等待队列了。
B、每次退出rwsem_spin_on_owner并且没有要退出自旋的时候,都试着去获取rwsem,如果持锁成功那么退出乐观自旋。
C、C和D是对reader-owned场景的处理。每次rwsem的owner state发生变化(从non-reader变成reader-owned状态)时都会重新初始化 rspin_threshold。
D、Owner state没有发生变化,那么当前试图持锁的writer可以进行乐观自旋,但是需要有一个度,毕竟rwsem的临界区内可能有多个reader线程,这有可能使得writer乐观自旋很长时间。设置自旋门限阈值的公式是Spinning threshold = (10 + nr_readers/2)us,最大25us(30 reader)。一旦自旋超期,那么将调用rwsem_set_nonspinnable禁止乐观自旋。
E、对于writer-owned场景,need_resched在函数rwsem_spin_on_owner中完成,对于reader-owned场景,也是需要检查owner task所在cpu的resched情况。毕竟当前任务如果有调度需求,无论reader持锁还是writer持锁场景都要停止自旋。
F、在reader-owned场景中,由于无法判定临界区reader们的执行状态,因此rt线程的乐观自旋需要更加的谨慎,毕竟有可能自旋的rt线程和临界区的reader在一个CPU上从而导致活锁现象。当然也不能禁止rt线程的自旋,毕竟在临界区为空的情况下,rt自旋会有一定的收益的。允许rt线程自旋的场景有两个:
a) lock owner正在释放锁,sem->owner被清除但是锁还没有释放。
b) 锁是空闲的并且sem->owner已清除,但是在我们尝试获取锁之前另一个任务刚刚进入并获取了锁(例如一个自旋的writer先于我们进入临界区)。
十三、关于handoff
1、设置handoff标记
设置handoff往往是发生在唤醒持锁阶段。对于等待队列的writer,唤醒之后要调度执行后才去持锁,这是一个长路径,很可能被其他的write或者reader把锁抢走。唤醒等待队列中的reader们有点不一样,在唤醒路径上就会从这一组待唤醒的reader们选出一个代表(一般是top waiter)去持锁,然后再一个个的唤醒。在这个reader代表线程持锁的时候也有可能由于writer偷锁而失败(reader虽然也会偷锁,但是偷锁的reader也会唤醒等待队列的reader们,完成top waiter未完成的工作)。无论是reader还是writer,如果唤醒后持锁失败,并且等待时间已经超过了RWSEM_WAIT_TIMEOUT,这时候就会设置handoff bit,防止等待队列的waiter饿死。具体设置handoff bit的场景如下:
|
场景 |
Handoff的处理逻辑 |
|
唤醒阻塞在该rwsem线程(writer或者reader们)的场景 rwsem_mark_wake |
在唤醒top waiter(是reader线程且需要持锁)的时候,发现锁被writer偷走。在这种场景下,如果尚未设置handoff,并且超过4ms的等待时长,那么将设置handoff标记,阻止writer线程继续抢锁 |
|
阻塞在该rwsem的writer线程被唤醒后去试图持锁场景 rwsem_try_write_lock |
在writer试图持锁的过程中,如果发现锁被reader或者writer偷走,并且超过4ms的等待时长,那么将设置handoff标记,阻止其他线程继续抢锁 |
2、清除handoff标记
标记了hand off之后,快速路径、乐观偷锁(reader)、乐观自旋(writer)都无法完成持锁,锁最终会递交给top waiter的线程,完成持锁。一旦完成持锁,handoff标记就会被清除。具体清除handoff bit的场景包括:
|
场景 |
Handoff的处理逻辑 |
|
在down read或者down write慢速路径中持锁失败进入阻塞,线程在等锁的时候被信号打断。参考rwsem_del_waiter函数 |
将该rwsem waiter对象从等待队列中摘下的时候,如果是最后一个等待对象(即摘下后等待队列变成空队列),那么清除handoff标记(当然也清除waiter标记) |
|
阻塞的reader线程被唤醒的时候,参考函数rwsem_mark_wake |
在唤醒reader线程们的时候,等待对象节点会从等待队列中摘下。如果已经唤醒top waiter线程的时候,清除handoff标记。 |
|
阻塞的 writer被唤醒且被调度执行后会去试图持锁,如果持锁成功会清除handoff标记。具体请参考函数rwsem_try_write_lock |
唤醒writer,通过rwsem_try_write_lock去试图持锁,持锁成功后就会清除handoff标记 |
3、确保锁的所有权递交给top waiter
|
场景 |
Handoff的处理逻辑 |
|
Down read系列接口中的快速路径(rwsem_read_trylock) |
如果rwsem设置了handoff标记,那么将无法走快速路径持锁 |
|
Read try lock中过滤handoff条件(down_read_trylock) |
如果rwsem设置了handoff标记,那么将无法try lock成功 |
|
Writer线程的乐观自旋场景 rwsem_try_write_lock_unqueued |
如果rwsem设置了handoff标记,writer将无法通过乐观自旋完成持锁 |
|
Down read系列接口中的慢速路径中的偷锁场景 rwsem_down_read_slowpath |
由于reader不允许乐观自旋,因此reader在慢速路径上进行一次(没有spin)偷锁行为。如果rwsem设置了handoff标记,reader将无法完成偷锁行为 |
十四、结论
标准linux内核的读写锁是在公平性、吞吐量和延迟选择了比较均衡的策略,这样的策略在手机平台上(特别是重载场景下)不能算是“优秀”,只能是合格吧。实际上,在手机用户交互场景中,我们更期望是确保用户体验相关线程的持锁时延,同时兼顾吞吐量。在这样的背景下,OPPO内核团队对linux中的读写锁进行了优化,下一次有机会可以分享我们在读写锁的持锁时延方面做的改进。
参考文献:
1、linux-5.15.81内核源代码
2、linux-5.15.81\Documentation\locking\*
本文作者:郭健Cojack
本文首发在“内核工匠”微信公众号,欢迎扫描以下二维码关注公众号获取最新Linux技术分享:
标签: rwsem
评论:
功能
最新评论
文章分类

随机文章
文章存档
- 2025年4月(5)
- 2024年2月(1)
- 2023年5月(1)
- 2022年10月(1)
- 2022年8月(1)
- 2022年6月(1)
- 2022年5月(1)
- 2022年4月(2)
- 2022年2月(2)
- 2021年12月(1)
- 2021年11月(5)
- 2021年7月(1)
- 2021年6月(1)
- 2021年5月(3)
- 2020年3月(3)
- 2020年2月(2)
- 2020年1月(3)
- 2019年12月(3)
- 2019年5月(4)
- 2019年3月(1)
- 2019年1月(3)
- 2018年12月(2)
- 2018年11月(1)
- 2018年10月(2)
- 2018年8月(1)
- 2018年6月(1)
- 2018年5月(1)
- 2018年4月(7)
- 2018年2月(4)
- 2018年1月(5)
- 2017年12月(2)
- 2017年11月(2)
- 2017年10月(1)
- 2017年9月(5)
- 2017年8月(4)
- 2017年7月(4)
- 2017年6月(3)
- 2017年5月(3)
- 2017年4月(1)
- 2017年3月(8)
- 2017年2月(6)
- 2017年1月(5)
- 2016年12月(6)
- 2016年11月(11)
- 2016年10月(9)
- 2016年9月(6)
- 2016年8月(9)
- 2016年7月(5)
- 2016年6月(8)
- 2016年5月(8)
- 2016年4月(7)
- 2016年3月(5)
- 2016年2月(5)
- 2016年1月(6)
- 2015年12月(6)
- 2015年11月(9)
- 2015年10月(9)
- 2015年9月(4)
- 2015年8月(3)
- 2015年7月(7)
- 2015年6月(3)
- 2015年5月(6)
- 2015年4月(9)
- 2015年3月(9)
- 2015年2月(6)
- 2015年1月(6)
- 2014年12月(17)
- 2014年11月(8)
- 2014年10月(9)
- 2014年9月(7)
- 2014年8月(12)
- 2014年7月(6)
- 2014年6月(6)
- 2014年5月(9)
- 2014年4月(9)
- 2014年3月(7)
- 2014年2月(3)
- 2014年1月(4)

2023-05-31 15:52